1. 环境
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
hive默认使用mr作为计算引擎,当进入cli时会看到以上的提示信息,刚好有hive2.1.0,查了下pom文件,依赖了spark1.6.0,版本应该可以兼容spark1.6.1,所以在此基础上搭建hive on spark环境。
2.搭建hadoop环境
3.搭建spark环境
虽要注意的一点是,使用hive on spark模式时,spark-assembly-1.6.1-hadoop2.6.0.jar不能包含hive的相关依赖,所以需要自己编译spark源码,在编译时去掉-Phive参数。
4.安装mysql
采用mysql来存储hive的元数据,使用了免安装的mysql,安装过程略。
5.安装hive
5.1 下载hive2.1.0
https://hive.apache.org/downloads.html
5.2 解压到服务器
/usr/apache-hive-2.1.0-bin
5.3 配置环境变量
export HIVE_HOME=/usr/apache-hive-2.1.0-bin
export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/bin
export HCAT_HOME=$HIVE_HOME/hcatalog/5.4 初始化hive配置
- 创建hive-default.xml文件
cp hive-default.xml.template hive-default.xml- 创建hive-site.xml文件
参考hive-default.xml文件生成hive-site.xml,并将内容修改为以下:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive2?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>mysql</value>
</property>把mysql的驱动包旋转到$HIVE_HOME/lib目录下
初始化元数据:
schematool -initSchema -dbType mysql- 使用
hive进入cli客户端验证hive是否安装成功
5.5 配置hive on spark
- 添加spark依赖到hive环境中
scala-library.jar
spark-core_2.10-1.6.1.jar
spark-network-common_2.10-1.6.1.jar设置hive的执行引擎为spark
方式一:进入cli后通过以下命令进行动态设置
set hive.execution.engine=spark; set spark.master=spark://master:7077;方式二:在hive-site.xml中进行全局设置
<property> <name>hive.execution.engine</name> <value>spark</value> </property> <property> <name>hive.enable.spark.execution.engine</name> <value>true</value> </property> <property> <name>spark.master</name> <value>spark://master:7077</value> </property>
验证hive on spark
create table tb_user(id int,name string ,age int);
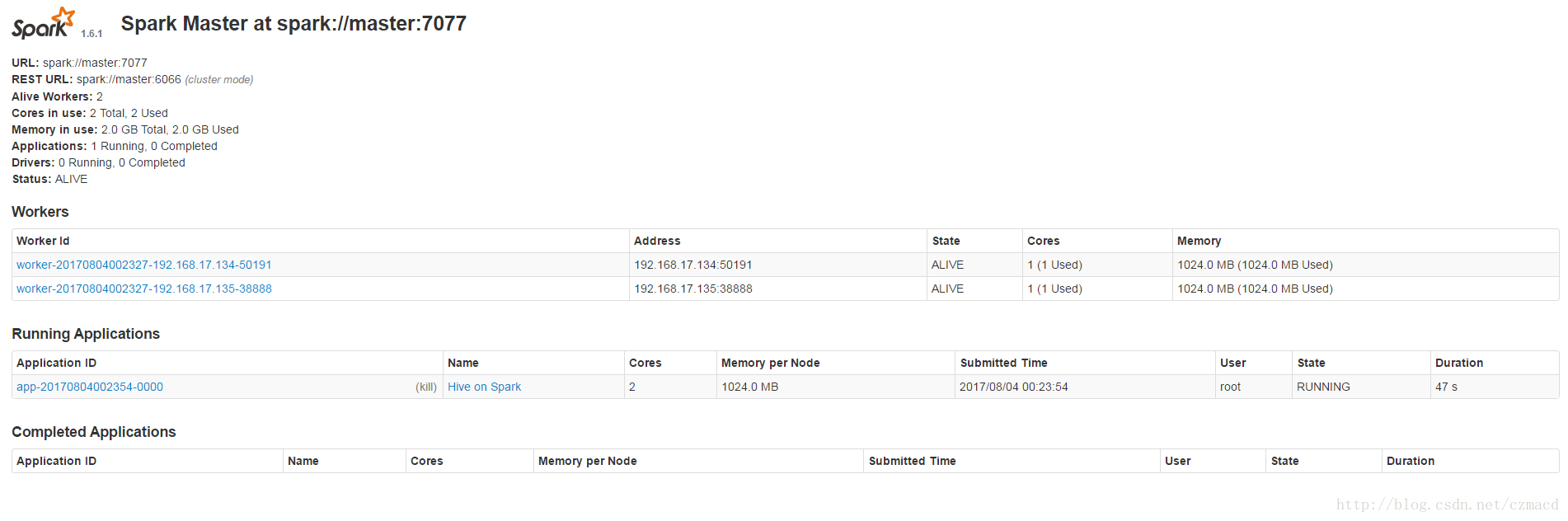
insert into tb_user values(1,'name1',11),(2,'name2',12),(3,'name3',13);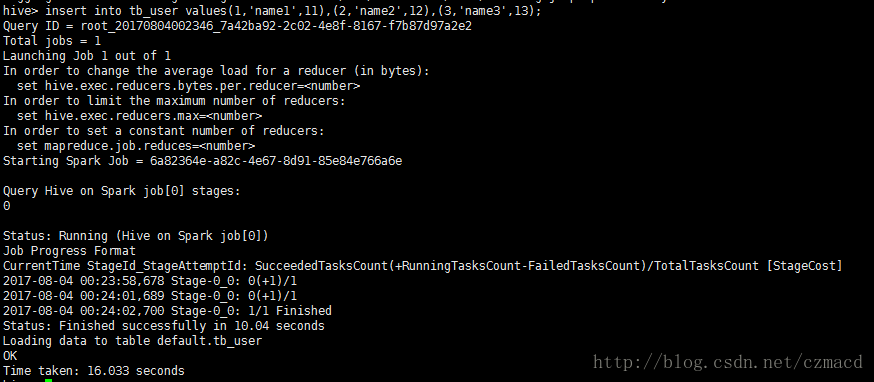
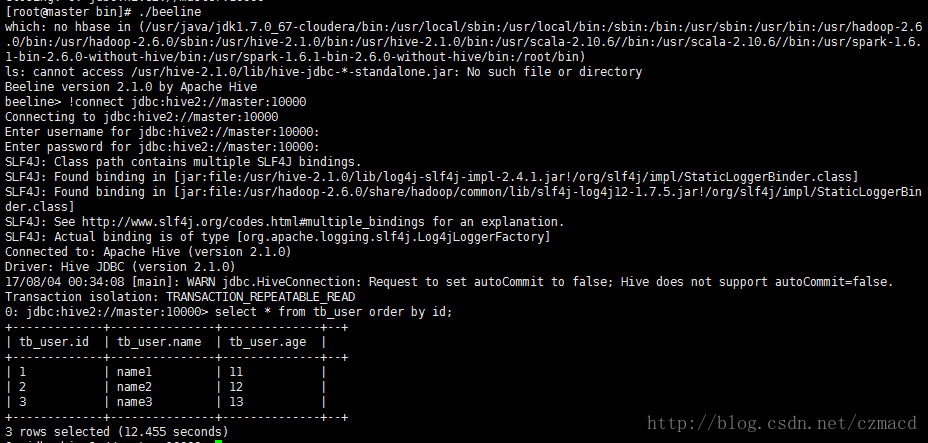
5.6 使用hiveserver2和beline
- 启动hiveserver2服务:$HIVE_HOME/hiveserver2
- 通过beline连接hiveserver2
6.安装配置过程遇到问题
- 问题1
Error: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate anonymous (state=,code=0)在$HODOOP_HOME/hadoop/core-site.xml中添加:
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>- 问题2
Exception in thread "main" java.lang.NoSuchFieldError: SPARK_RPC_SERVER_ADDRESS
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create spark client.)'
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.spark.SparkTaskspark中不能含有hive的依赖,去掉-Phive进行编译spark
参考:
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started