Apriori 算法
1. 先验原理
1. 性质
上次说到,Apriori算法有两个重要特性。
- 频繁项集的非空子集一定是频繁的
- 非频繁项集的超集一定是非频繁的
这两个性质就是Apriori算法的基础,插图解释。(插图用PPT画的,有好的画图方法,请大佬赐教)。
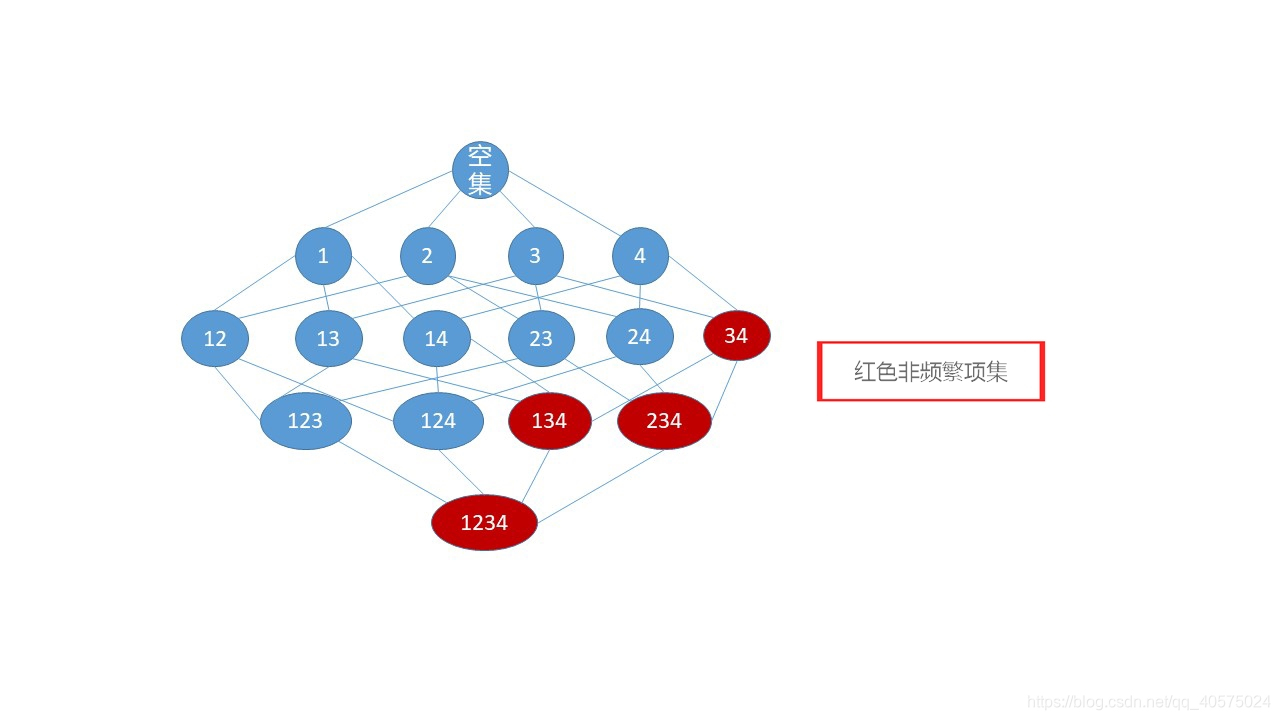
都从1-项集开始分析的,假设1,2,3,4都满足最小支持度,那么它们都是频繁1-项集。
2-项集分析时,发现34不是频繁项集,标红。其余为频繁2-项集。
3-项集分析时,134,234 都不是频繁项集,标红。
4-项集分析时,1234不是频繁4-项集。
性质1 ,频繁项集的非空子集一定是频繁的。知道123 是频繁项集,就可以得出结论,12,13,23,1,2,3肯定都是频繁项集。234同理。
性质2 ,非频繁项集的超集一定是非频繁的。分析过程中,得知34是非频繁的,那么就可以知道134,234一定也是非频繁的。
2. 算法流程
流程是死的,就不解释什么了。感兴趣的还可以看看伪代码。
输入:数据集合D,支持度阈值αα
输出:最大的频繁k项集
- 扫描整个数据集,得到所有出现过的数据,作为候选频繁1项集。k=1,频繁0项集为空集。
- 挖掘频繁k项集
a) 扫描数据计算候选频繁k项集的支持度
b) 去除候选频繁k项集中支持度低于阈值的数据集,得到频繁k项集。如果得到的频繁k项集为空,则直接返回频繁k-1项集的集合作为算法 结果,算法结束。如果得到的频繁k项集只有一项,则直接返回频繁k项集的集合作为算法结果,算法结束。
c) 基于频繁k项集,连接生成候选频繁k+1项集。 - 令k=k+1,转入步骤2。
3. 剪枝和连接
剪枝和连接是算法的核心。通过当项集不满足支持度的时候,我们删除。
1-项集都满足最小支持度,不需要剪枝,只要连接。因此,1,2,3,4 被连接成12,13,14,23,24,34。
2-项集时,34 不满足最小支持度,因此删除。这一步删除就是剪枝,删除之后,234,134,1234 都不会再出现。而12,13,14,23,24连接成123,124。
3-项集时,123,124 运行结束。
如果数据比较多,则算法就会4-项集,5-项集,,,n-项集一直这样下去。
2. python 代码分析
from numpy import *
def loadDataSet(): ## 定义的数据集,选数字还是选字母自行选择,也可以用其他的数据集代替。
#return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
return [['A','B','D','E'],['E','B','D'],['B','D','E'],['E','D'],['A','B','D'],['D'],['B','E'],['E'],['A','C','D','E'],['A','B','C','D','E']]
def createC1(dataSet): # 创造候选项集C1,C1是大小为1的所有候选项集的集合
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
# C1.sort() # 从大到小排序 本想用排序删除重复项,放弃了。
#print("CCC=",C1)
return list(map(frozenset, C1)) #这里采用不可改变的集合(frozenset函数决定)删除重复项,然后返回去重的列表。
def scanD(D, Ck, minSupport): # 此函数计算支持度,筛选满足要求的项集成为频繁项集Lk,D是数据集,Ck为候选项集C1或C2或C3 ...
ssCnt = {} # 你会发现,就是计数,求概率。毕竟是条件概率,先验概率。
#print("CK==",Ck)
for tid in D:
for can in Ck:
if can.issubset(tid):
if not can in ssCnt:
ssCnt[can] = 1
else:
ssCnt[can] += 1
numItems = float(len(D))
retList = []
supportData = {
for key in ssCnt:
support = ssCnt[key] / numItems # 计算支持度
if support >= minSupport: # 如果支持度大于设定的最小支持度
# retList.insert(0,key)
retList.append(key)
supportData[key] = support
return retList, supportData
def aprioriGen(Lk, k): # 这里是利用了性质的aproriGen
#print("lk==",Lk)
lenLk = len(Lk)
temp_dict = {} # 临时字典,存储
for i in range(lenLk):
for j in range(i + 1, lenLk):
L1 = Lk[i] | Lk[j] # 两两合并,执行了 lenLk!次 #算法时间复杂度高的原因
#print("L1==",L1)
#print("sss",Lk[i])
if len(L1) == k: # 如果合并后的子项元素有k个,满足要求
if not L1 in temp_dict: # 把符合的新项存到字典的键中,使用字典可以去重复,比如{1,2,3}和{3,1,2}是一样的项,使用了字典就可以达到去重的作用
temp_dict[L1] = 1
return list(temp_dict) # 把字典的键转化为列表
# def aprioriGen(Lk, k): # 没有改变之前的函数,根据频繁项集Lk-1创造候选项集Ck 。你会发现连接步非常繁琐。
# retList = []
# lenLk = len(Lk)
# for i in range(lenLk):
# for j in range(i+1, lenLk):
# L1 = list(Lk[i])[:k-2]
# L2 = list(Lk[j])[:k-2]
# L1.sort() # 排序
# L2.sort()
# if L1 == L2: # 比较前Lk-1中的两个项的k-2个元素是否相同,这样才能保证合成后只有k个元素
# retList.append(Lk[i]|Lk[j])
# return retList
def apriori(dataSet, minSupport=0.2): # 通过循环得出[L1,L2,L3..]频繁项集列表
C1 = createC1(dataSet) # 创造C1
D = list(map(set, dataSet))
#print("DDD=",D)
L1, supportData = scanD(D, C1, minSupport)
# 筛选出L1
L = [L1]
print(L)
k = 2
while (len(L[k - 2]) > 0): # 创造Ck
print("k==",k,L[k-2])
Ck = aprioriGen(L[k - 2], k)
Lk, supK = scanD(D, Ck, minSupport)
supportData.update(supK)
L.append(Lk)
k += 1
return L, supportData
if __name__ == "__main__":
dataSet = loadDataSet()
L, suppData = apriori(dataSet)
代码注释写在了程序里,有两个版本的aprioriGen()函数供选择,数据集可以自己制作,也可以用给出的例子。注意apriori()算法的逻辑。