文章目录
一、过拟合与欠拟合简述

欠拟合问题,根本的原因是模型复杂度过低,导致拟合的函数无法满足训练集,误差较大。
碰到欠拟合问题可以尝试将模型复杂度增加一下,例如:堆叠更多的层数,增加每一层的单元数量,如果有所改善,说明需要增加模型的复杂度
过拟合问题,根本原因是模型复杂度过高,导致拟合函数接近完美拟合训练集,误差很小。
但是由于使用的模型复杂度大于合理的模型复杂度,过拟合训练集,会使得模型在训练集上效果特别好,但是在测试集上效果变差。

模型的次方越高,模型的表达能力越强。
reduce overfitting 手段
-
More Data—更多的数据
对于图片来讲,可以通过增加噪声、数据增强(旋转、裁剪、光照、翻转)等来增加训练数据量 -
降低模型复杂度 (一般不这么做)
shadow——衡量数据量与网络 regularation——正则化 正则化网络能够对训练数据中的常见数据构造出相对简单的模型,并且对训练数据中各种各样的噪声有良好的抵抗能力, 提升了模型的泛化能力。可以理解为一种能使噪声数据不会过多影响网络输出的方法 -
Dropout—增加鲁棒性
-
data argumentation—数据增强
-
Early Stopping—使用验证集做早停
二、降低过拟合—交叉验证
1.train_val划分


# train_val
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
def preprocess(x, y):
"""
x is a simple image, not a batch
"""
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, [28 * 28])
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
batchsz = 128
(x, y), (x_val, y_val) = datasets.mnist.load_data()
print('datasets:', x.shape, y.shape, x.min(), x.max())
db = tf.data.Dataset.from_tensor_slices((x, y))
db = db.map(preprocess).shuffle(60000).batch(batchsz)
ds_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
ds_val = ds_val.map(preprocess).batch(batchsz)
sample = next(iter(db))
print(sample[0].shape, sample[1].shape)
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.build(input_shape=(None, 28 * 28))
network.summary()
network.compile(optimizer=optimizers.Adam(lr=0.01),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
network.fit(db, epochs=5, validation_data=ds_val,
validation_steps=2)
network.evaluate(ds_val)
sample = next(iter(ds_val))
x = sample[0]
y = sample[1] # one-hot
pred = network.predict(x) # [b, 10]
# convert back to number
y = tf.argmax(y, axis=1)
pred = tf.argmax(pred, axis=1)
print(pred)
print(y)
2.train_val_test划分
利用train set来训练模型参数,利用val set来选择在哪个时间上停止掉,选择哪个时间戳上的参数,利用test set来做一个测试。
不能利用test set来挑选val set上的参数,会造成数据污染,即利用先验知识来挑选参数。
# train_val_test
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
def preprocess(x, y):
"""
x is a simple image, not a batch
"""
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, [28 * 28])
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
batchsz = 128
(x, y), (x_test, y_test) = datasets.mnist.load_data()
print('datasets:', x.shape, y.shape, x.min(), x.max())
# 可以直接分割数据集
# x_train, x_val = tf.split(x, num_or_size_splits=[50000, 10000])
# y_train, y_val = tf.split(y, num_or_size_splits=[50000, 10000])
idx = tf.range(60000)
idx = tf.random.shuffle(idx)
x_train, y_train = tf.gather(x, idx[:50000]), tf.gather(y, idx[:50000])
x_val, y_val = tf.gather(x, idx[-10000:]), tf.gather(y, idx[-10000:])
print(x_train.shape, y_train.shape, x_val.shape, y_val.shape)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.map(preprocess).shuffle(50000).batch(batchsz)
db_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
db_val = db_val.map(preprocess).shuffle(10000).batch(batchsz)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(preprocess).batch(batchsz)
sample = next(iter(db_train))
print(sample[0].shape, sample[1].shape)
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.build(input_shape=(None, 28 * 28))
network.summary()
network.compile(optimizer=optimizers.Adam(lr=0.01),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
network.fit(db_train, epochs=6, validation_data=db_val, validation_freq=2)
print('Test performance:')
network.evaluate(db_test)
sample = next(iter(db_test))
x = sample[0]
y = sample[1] # one-hot
pred = network.predict(x) # [b, 10]
# convert back to number
y = tf.argmax(y, axis=1)
pred = tf.argmax(pred, axis=1)
print(pred)
print(y)
3.K—fold 交叉验证
既防止了死记硬背,又将数据充分利用了起来。

from sklearn.model_selection import KFold
for train_idx, val_idx in KFold(n_splits=5,random_state=0,shuffle=False).split(x):
#print(train, test)
print(train_idx)
print(val_idx)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
from sklearn.model_selection import KFold
import numpy as np
def preprocess(x, y):
"""
x is a simple image, not a batch
"""
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, [28 * 28])
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
batchsz = 128
(x, y), (x_test, y_test) = datasets.mnist.load_data()
print('datasets:', x.shape, y.shape, x.min(), x.max())
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(preprocess).batch(batchsz)
accuracy = []
for train_idx, val_idx in KFold(n_splits=5, random_state=0,shuffle=True).split(x, y):
db_train = tf.data.Dataset.from_tensor_slices((x[train_idx, ...], y[train_idx, ...]))
db_train = db_train.map(preprocess).shuffle(40000).batch(batchsz)
db_val = tf.data.Dataset.from_tensor_slices((x[val_idx, ...], y[val_idx, ...]))
db_val = db_val.map(preprocess).shuffle(10000).batch(batchsz)
sample = next(iter(db_train))
# print(sample[0].shape, sample[1].shape)
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.build(input_shape=(None, 28 * 28))
network.compile(optimizer=optimizers.Adam(lr=0.01),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
# 早停
early_stop = keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=5)
network.fit(db_train, epochs=6, validation_data=db_val, validation_freq=1, verbose=1, callbacks=[early_stop])
network.evaluate(db_test)
print('model evaluation', network.evaluate(db_test))
accuracy.append(network.evaluate(db_test)[1])
print('交叉验证的平均准确率为', np.mean(accuracy))
datasets: (60000, 28, 28) (60000,) 0 255
Epoch 1/6
375/375 [==============================] - 1s 3ms/step - loss: 0.3016 - accuracy: 0.9095 - val_loss: 0.1987 - val_accuracy: 0.9384
Epoch 2/6
375/375 [==============================] - 1s 3ms/step - loss: 0.1428 - accuracy: 0.9600 - val_loss: 0.1331 - val_accuracy: 0.9638
Epoch 3/6
375/375 [==============================] - 1s 3ms/step - loss: 0.1172 - accuracy: 0.9673 - val_loss: 0.1329 - val_accuracy: 0.9635
Epoch 4/6
375/375 [==============================] - 1s 3ms/step - loss: 0.0994 - accuracy: 0.9725 - val_loss: 0.1307 - val_accuracy: 0.9647
Epoch 5/6
375/375 [==============================] - 1s 3ms/step - loss: 0.0859 - accuracy: 0.9764 - val_loss: 0.1159 - val_accuracy: 0.9705
Epoch 6/6
375/375 [==============================] - 1s 3ms/step - loss: 0.0833 - accuracy: 0.9781 - val_loss: 0.1199 - val_accuracy: 0.9717
79/79 [==============================] - 0s 3ms/step - loss: 0.1254 - accuracy: 0.9704
79/79 [==============================] - 0s 3ms/step - loss: 0.1254 - accuracy: 0.9704
model evaluation [0.12543930113315582, 0.9703999757766724]
79/79 [==============================] - 0s 3ms/step - loss: 0.1254 - accuracy: 0.9704
Epoch 1/6
375/375 [==============================] - 1s 3ms/step - loss: 0.3053 - accuracy: 0.9087 - val_loss: 0.1657 - val_accuracy: 0.9520
Epoch 2/6
375/375 [==============================] - 1s 3ms/step - loss: 0.1468 - accuracy: 0.9587 - val_loss: 0.1342 - val_accuracy: 0.9623
Epoch 3/6
375/375 [==============================] - 1s 3ms/step - loss: 0.1126 - accuracy: 0.9686 - val_loss: 0.1685 - val_accuracy: 0.9569
Epoch 4/6
375/375 [==============================] - 1s 4ms/step - loss: 0.0976 - accuracy: 0.9727 - val_loss: 0.1656 - val_accuracy: 0.9636
Epoch 5/6
375/375 [==============================] - 1s 3ms/step - loss: 0.0857 - accuracy: 0.9763 - val_loss: 0.1443 - val_accuracy: 0.9643
Epoch 6/6
375/375 [==============================] - 1s 3ms/step - loss: 0.0840 - accuracy: 0.9772 - val_loss: 0.1482 - val_accuracy: 0.9668
79/79 [==============================] - 0s 3ms/step - loss: 0.1467 - accuracy: 0.9649
79/79 [==============================] - 0s 3ms/step - loss: 0.1467 - accuracy: 0.9649
model evaluation [0.14668044447898865, 0.964900016784668]
79/79 [==============================] - 0s 3ms/step - loss: 0.1467 - accuracy: 0.9649
Epoch 1/6
375/375 [==============================] - 1s 3ms/step - loss: 0.3006 - accuracy: 0.9091 - val_loss: 0.1962 - val_accuracy: 0.9427
Epoch 2/6
375/375 [==============================] - 1s 3ms/step - loss: 0.1410 - accuracy: 0.9594 - val_loss: 0.1590 - val_accuracy: 0.9565
Epoch 3/6
375/375 [==============================] - 1s 4ms/step - loss: 0.1089 - accuracy: 0.9690 - val_loss: 0.1486 - val_accuracy: 0.9612
Epoch 4/6
375/375 [==============================] - 1s 4ms/step - loss: 0.1002 - accuracy: 0.9725 - val_loss: 0.1412 - val_accuracy: 0.9649
Epoch 5/6
375/375 [==============================] - 1s 3ms/step - loss: 0.0892 - accuracy: 0.9755 - val_loss: 0.1465 - val_accuracy: 0.9657
Epoch 6/6
375/375 [==============================] - 1s 3ms/step - loss: 0.0866 - accuracy: 0.9768 - val_loss: 0.1401 - val_accuracy: 0.9644
79/79 [==============================] - 0s 3ms/step - loss: 0.1312 - accuracy: 0.9671
79/79 [==============================] - 0s 3ms/step - loss: 0.1312 - accuracy: 0.9671
model evaluation [0.1311722695827484, 0.9671000242233276]
79/79 [==============================] - 0s 3ms/step - loss: 0.1312 - accuracy: 0.9671
Epoch 1/6
375/375 [==============================] - 1s 3ms/step - loss: 0.3089 - accuracy: 0.9053 - val_loss: 0.2054 - val_accuracy: 0.9437
Epoch 2/6
375/375 [==============================] - 1s 3ms/step - loss: 0.1503 - accuracy: 0.9585 - val_loss: 0.1736 - val_accuracy: 0.9521
Epoch 3/6
375/375 [==============================] - 1s 3ms/step - loss: 0.1128 - accuracy: 0.9677 - val_loss: 0.1342 - val_accuracy: 0.9635
Epoch 4/6
375/375 [==============================] - 1s 3ms/step - loss: 0.0983 - accuracy: 0.9725 - val_loss: 0.1311 - val_accuracy: 0.9649
Epoch 5/6
375/375 [==============================] - 1s 4ms/step - loss: 0.0895 - accuracy: 0.9750 - val_loss: 0.1381 - val_accuracy: 0.9647
Epoch 6/6
375/375 [==============================] - 1s 3ms/step - loss: 0.0804 - accuracy: 0.9786 - val_loss: 0.1299 - val_accuracy: 0.9668
79/79 [==============================] - 0s 3ms/step - loss: 0.1330 - accuracy: 0.9673
79/79 [==============================] - 0s 3ms/step - loss: 0.1330 - accuracy: 0.9673
model evaluation [0.13295502960681915, 0.9672999978065491]
79/79 [==============================] - 0s 3ms/step - loss: 0.1330 - accuracy: 0.9673
Epoch 1/6
375/375 [==============================] - 1s 3ms/step - loss: 0.2961 - accuracy: 0.9103 - val_loss: 0.1545 - val_accuracy: 0.9562
Epoch 2/6
375/375 [==============================] - 1s 3ms/step - loss: 0.1474 - accuracy: 0.9589 - val_loss: 0.1576 - val_accuracy: 0.9586
Epoch 3/6
375/375 [==============================] - 1s 3ms/step - loss: 0.1143 - accuracy: 0.9680 - val_loss: 0.1690 - val_accuracy: 0.9553
Epoch 4/6
375/375 [==============================] - 1s 4ms/step - loss: 0.1025 - accuracy: 0.9725 - val_loss: 0.1304 - val_accuracy: 0.9694
Epoch 5/6
375/375 [==============================] - 1s 4ms/step - loss: 0.0857 - accuracy: 0.9770 - val_loss: 0.1437 - val_accuracy: 0.9668
Epoch 6/6
375/375 [==============================] - 1s 3ms/step - loss: 0.0846 - accuracy: 0.9768 - val_loss: 0.1436 - val_accuracy: 0.9675
79/79 [==============================] - 0s 3ms/step - loss: 0.1387 - accuracy: 0.9658
79/79 [==============================] - 0s 3ms/step - loss: 0.1387 - accuracy: 0.9658
model evaluation [0.13874870538711548, 0.9657999873161316]
79/79 [==============================] - 0s 3ms/step - loss: 0.1387 - accuracy: 0.9658
交叉验证的平均准确率为 0.96709996
4.StratifiedKFold—分层的K折交叉和验证
对于数据集有偏的分类问题,即样中某些类样本比较多,某些类样本特别少,传统的k折交叉验证会造成训练时该样本的比例远小于测试集中该样本比例的极端情况。
StratifiedKFold是KFold的变体,它是分层采样,确保训练集,测试集中各类别样本的比例与原始数据集中相同
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: admin
@file: k折交叉验证.py
@time: 2021/02/24
@desc:
"""
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
from sklearn.model_selection import KFold,StratifiedKFold
def preprocess(x, y):
"""
x is a simple image, not a batch
"""
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, [28 * 28])
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
batchsz = 128
(x, y), (x_test, y_test) = datasets.mnist.load_data()
print('datasets:', x.shape, y.shape, x.min(), x.max())
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(preprocess).batch(batchsz)
accuracy = []
for train_idx, val_idx in StratifiedKFold(n_splits=5, random_state=0,shuffle=True).split(x, y):
db_train = tf.data.Dataset.from_tensor_slices((x[train_idx, ...], y[train_idx, ...]))
db_train = db_train.map(preprocess).shuffle(40000).batch(batchsz)
db_val = tf.data.Dataset.from_tensor_slices((x[val_idx, ...], y[val_idx, ...]))
db_val = db_val.map(preprocess).shuffle(10000).batch(batchsz)
sample = next(iter(db_train))
# print(sample[0].shape, sample[1].shape)
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.build(input_shape=(None, 28 * 28))
network.compile(optimizer=optimizers.Adam(lr=0.01),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
# 早停
early_stop = keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=5)
network.fit(db_train, epochs=6, validation_data=db_val, validation_freq=1, verbose=1, callbacks=[early_stop])
network.evaluate(db_test)
print('model evaluation', network.evaluate(db_test))
accuracy.append(network.evaluate(db_test)[1])
print('交叉验证的平均准确率为', np.mean(accuracy))
交叉验证的平均准确率为0.96938, shape=()
5.TimeSeriesSplit—时序数据分割
针对时序数据,KFold分割会出现以未来的数据来预测过去的数据的特殊情况,这种情况会造成数据泄露;TimeSeriesSplit就是专门解决这种问题的
 >但是在TimeSeriesSplit中,一个组可以部分地落在训练集中,部分地落在测试集中
>但是在TimeSeriesSplit中,一个组可以部分地落在训练集中,部分地落在测试集中
from sklearn.model_selection import TimeSeriesSplit
for train_idx, test_idx in TimeSeriesSplit().split(x_train):
print(x_train.loc[train_idx, 'date'].unique())
print(x_train.loc[test_idx, 'date'].unique())
break
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44]
[ 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61
62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97
98 99 100 101 102 103 104]
可以看到第44天数据同时落到训练集与测试集中,也会造成数据泄露
三、正则化减轻过拟合
正则化的目的:迫使参数的范数接近于0,此时,模型的复杂度会减小,同时也保存了模型的性能
如下图,在未经过正则化时,学习到很多噪声数据,模型复杂度高,经过L2正则化后,减轻了过拟合

-
L1正则化
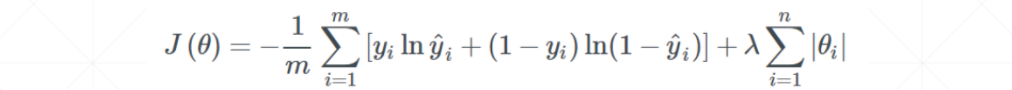
-
L2正则化
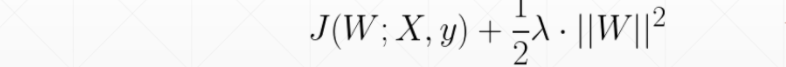
1.one-by-one regularization
network = Sequential([layers.Dense(256, activation='relu',
kernel_regularizer=keras.regularizers.l2(0.001)),
layers.Dense(128, activation='relu',
kernel_regularizer=keras.regularizers.l2(0.001)),
layers.Dense(64, activation='relu',
kernel_regularizer=keras.regularizers.l2(0.001)),
layers.Dense(32, activation='relu',
kernel_regularizer=keras.regularizers.l2(0.001)),
layers.Dense(10)])
2.Flexible regularization
for step, (x, y) in enumerate(db):
with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28 * 28))
# [b, 784] => [b, 10]
out = network(x)
# [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# [b]
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y_onehot, out, from_logits=True))
# regularization
loss_regularization = []
for p in network.trainable_variables:
# tf.nn.l2_loss(p)表示计算对应参数的L2正则
loss_regularization.append(tf.nn.l2_loss(p))
loss_regularization = tf.reduce_sum(tf.stack(loss_regularization))
loss = loss + 0.0001 * loss_regularization
grads = tape.gradient(loss, network.trainable_variables)
optimizer.apply_gradients(zip(grads, network.trainable_variables))
3.mnist数据集实战
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x, y
batchsz = 128
(x, y), (x_val, y_val) = datasets.mnist.load_data()
print('datasets:', x.shape, y.shape, x.min(), x.max())
db = tf.data.Dataset.from_tensor_slices((x, y))
db = db.map(preprocess).shuffle(60000).batch(batchsz).repeat(10)
ds_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
ds_val = ds_val.map(preprocess).batch(batchsz)
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.build(input_shape=(None, 28 * 28))
network.summary()
optimizer = optimizers.Adam(lr=0.01)
for step, (x, y) in enumerate(db):
with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28 * 28))
# [b, 784] => [b, 10]
out = network(x)
# [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# [b]
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y_onehot, out, from_logits=True))
# regularization
loss_regularization = []
for p in network.trainable_variables:
# tf.nn.l2_loss(p)表示计算对应参数的L2正则
loss_regularization.append(tf.nn.l2_loss(p))
loss_regularization = tf.reduce_sum(tf.stack(loss_regularization))
loss = loss + 0.0001 * loss_regularization
grads = tape.gradient(loss, network.trainable_variables)
optimizer.apply_gradients(zip(grads, network.trainable_variables))
if step % 100 == 0:
print(step, 'loss:', float(loss), 'loss_regularization:', float(loss_regularization))
# evaluate
if step % 500 == 0:
total, total_correct = 0., 0
for _, (x, y) in enumerate(ds_val):
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28 * 28))
# [b, 784] => [b, 10]
out = network(x)
# [b, 10] => [b]
pred = tf.argmax(out, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
# bool type
correct = tf.equal(pred, y)
# bool tensor => int tensor => numpy
total_correct += tf.reduce_sum(tf.cast(correct, dtype=tf.int32)).numpy()
total += x.shape[0]
print(step, 'Evaluate Acc:', total_correct / total)
datasets: (60000, 28, 28) (60000,) 0 255
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 256) 200960
_________________________________________________________________
dense_1 (Dense) (None, 128) 32896
_________________________________________________________________
dense_2 (Dense) (None, 64) 8256
_________________________________________________________________
dense_3 (Dense) (None, 32) 2080
_________________________________________________________________
dense_4 (Dense) (None, 10) 330
=================================================================
Total params: 244,522
Trainable params: 244,522
Non-trainable params: 0
_________________________________________________________________
0 loss: 2.3612353801727295 loss_regularization: 351.4171142578125
0 Evaluate Acc: 0.1533
100 loss: 0.243253692984581 loss_regularization: 578.9249267578125
200 loss: 0.26757124066352844 loss_regularization: 677.219970703125
300 loss: 0.19848859310150146 loss_regularization: 751.2823486328125
400 loss: 0.3406767249107361 loss_regularization: 811.97607421875
500 loss: 0.24017608165740967 loss_regularization: 896.7379760742188
500 Evaluate Acc: 0.9504
600 loss: 0.2751826047897339 loss_regularization: 944.6239624023438
700 loss: 0.21028143167495728 loss_regularization: 956.2200927734375
800 loss: 0.17245107889175415 loss_regularization: 997.5314331054688
900 loss: 0.22511816024780273 loss_regularization: 1025.3837890625
1000 loss: 0.20448143780231476 loss_regularization: 1024.01953125
1000 Evaluate Acc: 0.9604
1100 loss: 0.24897146224975586 loss_regularization: 1096.2596435546875
1200 loss: 0.25465214252471924 loss_regularization: 1084.11669921875
1300 loss: 0.23338088393211365 loss_regularization: 1066.907470703125
1400 loss: 0.2602844536304474 loss_regularization: 1050.3699951171875
1500 loss: 0.2058088779449463 loss_regularization: 1061.3245849609375
1500 Evaluate Acc: 0.9645
1600 loss: 0.13793328404426575 loss_regularization: 1071.851318359375
1700 loss: 0.20127150416374207 loss_regularization: 1049.2301025390625
1800 loss: 0.17058312892913818 loss_regularization: 1067.008056640625
1900 loss: 0.21312902867794037 loss_regularization: 1086.29052734375
2000 loss: 0.22994248569011688 loss_regularization: 1066.2252197265625
2000 Evaluate Acc: 0.9664
2100 loss: 0.22360754013061523 loss_regularization: 1107.987060546875
2200 loss: 0.3135825991630554 loss_regularization: 1119.5650634765625
2300 loss: 0.18278977274894714 loss_regularization: 1114.526611328125
2400 loss: 0.16066262125968933 loss_regularization: 1123.906005859375
2500 loss: 0.2407676875591278 loss_regularization: 1106.83203125
2500 Evaluate Acc: 0.9623
2600 loss: 0.26913684606552124 loss_regularization: 1135.7880859375
2700 loss: 0.1738978922367096 loss_regularization: 1145.8050537109375
2800 loss: 0.2006189525127411 loss_regularization: 1140.5020751953125
2900 loss: 0.3258235454559326 loss_regularization: 1133.76025390625
3000 loss: 0.20897530019283295 loss_regularization: 1149.9239501953125
3000 Evaluate Acc: 0.9678
3100 loss: 0.17655840516090393 loss_regularization: 1141.9337158203125
3200 loss: 0.33562344312667847 loss_regularization: 1120.0029296875
3300 loss: 0.26524966955184937 loss_regularization: 1103.284912109375
3400 loss: 0.21671968698501587 loss_regularization: 1075.7874755859375
3500 loss: 0.22501051425933838 loss_regularization: 1118.5203857421875
3500 Evaluate Acc: 0.9709
3600 loss: 0.16137506067752838 loss_regularization: 1110.3411865234375
3700 loss: 0.1805180013179779 loss_regularization: 1111.150390625
3800 loss: 0.13627690076828003 loss_regularization: 1097.7681884765625
3900 loss: 0.3311278223991394 loss_regularization: 1080.1058349609375
4000 loss: 0.1829344630241394 loss_regularization: 1128.781494140625
4000 Evaluate Acc: 0.9628
4100 loss: 0.13623860478401184 loss_regularization: 1113.8087158203125
4200 loss: 0.1975753903388977 loss_regularization: 1114.877685546875
4300 loss: 0.2189168781042099 loss_regularization: 1073.1143798828125
4400 loss: 0.20399484038352966 loss_regularization: 1096.3868408203125
4500 loss: 0.19384512305259705 loss_regularization: 1046.4239501953125
4500 Evaluate Acc: 0.9697
四、动量与学习率衰减
1.momentum—动量
有一些优化器诸如Adam没有momentum参数,因为这些优化器本身就利用momentum做了一些优化,不再需要额外管理这些变量,内部已经设置好如何设置momentum。
SGD、RMSprop没有设置momentum

因此现在的梯度方向zk+1是当前梯度方向与历史惯性的结合,取决于β怎么选取,当β=0时,不考虑历史惯性


optimizers = optimizers.SGD(learning_rate=0.01,momentum=0.9)
optimizers = optimizers.RMSprop(learning_rate=0.01,momentum=0.9)
2.learning rate Decay—学习率衰减


optimizer = optimizers.Adam(lr=0.01)
for epoch in range(100):
# 改变学习率
optimizers.learning_rate = 0.01*(100-epoch)/epoch
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, [28 * 28])
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y,depth=10)
return x, y
batchsz = 128
(x, y), (x_val, y_val) = datasets.mnist.load_data()
print('datasets:', x.shape, y.shape, x.min(), x.max())
db = tf.data.Dataset.from_tensor_slices((x, y))
db = db.map(preprocess).shuffle(60000).batch(batchsz).repeat(10)
ds_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
ds_val = ds_val.map(preprocess).batch(batchsz)
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.build(input_shape=(None, 28 * 28))
network.summary()
optimizer = optimizers.Adam(learning_rate=0.01)
for epoch in range(100):
optimizer.learning_rate = 0.01 * (100-epoch)/100
network.compile(optimizer=optimizer,
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
network.fit(db,validation_data=ds_val)
五、Early Stopping & Dropout & SGD
1. Early Stopping
- 验证集选择参数
- 监视验证集的表现
- 在验证集表现最好处停止

import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
import numpy as np
import matplotlib.pyplot as plt
def preprocess(x, y):
"""
x is a simple image, not a batch
"""
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, [28 * 28])
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
batchsz = 128
(x, y), (x_val, y_val) = datasets.mnist.load_data()
print('datasets:', x.shape, y.shape, x.min(), x.max())
db = tf.data.Dataset.from_tensor_slices((x, y))
db = db.map(preprocess).shuffle(60000).batch(batchsz)
ds_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
ds_val = ds_val.map(preprocess).batch(batchsz)
sample = next(iter(db))
print(sample[0].shape, sample[1].shape)
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.build(input_shape=(None, 28 * 28))
network.summary()
network.compile(optimizer=optimizers.Adam(lr=0.01),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
early_stop = keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=4)
history = network.fit(db, epochs=30, validation_data=ds_val,
validation_steps=2,callbacks=[early_stop])
# 构建迭代loss变化图像
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs_range = np.arange(len(acc))
fig = plt.figure(figsize=(15, 5))
fig.add_subplot()
plt.plot(epochs_range, acc, label='Train acc')
plt.plot(epochs_range, val_acc, label='Val_acc')
plt.legend(loc='upper right')
plt.title('Train and Val acc')
plt.show()
network.evaluate(ds_val)
# sample = next(iter(ds_val))
# x = sample[0]
# y = sample[1] # one-hot
# pred = network.predict(x) # [b, 10]
# # convert back to number
# y = tf.argmax(y, axis=1)
# pred = tf.argmax(pred, axis=1)
#
# print(pred)
# print(y)
datasets: (60000, 28, 28) (60000,) 0 255
(128, 784) (128, 10)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 256) 200960
_________________________________________________________________
dense_1 (Dense) (None, 128) 32896
_________________________________________________________________
dense_2 (Dense) (None, 64) 8256
_________________________________________________________________
dense_3 (Dense) (None, 32) 2080
_________________________________________________________________
dense_4 (Dense) (None, 10) 330
=================================================================
Total params: 244,522
Trainable params: 244,522
Non-trainable params: 0
_________________________________________________________________
Epoch 1/30
469/469 [==============================] - 1s 2ms/step - loss: 0.2845 - accuracy: 0.9157 - val_loss: 0.1236 - val_accuracy: 0.9648
Epoch 2/30
469/469 [==============================] - 1s 2ms/step - loss: 0.1298 - accuracy: 0.9633 - val_loss: 0.0724 - val_accuracy: 0.9844
Epoch 3/30
469/469 [==============================] - 1s 2ms/step - loss: 0.1095 - accuracy: 0.9694 - val_loss: 0.0648 - val_accuracy: 0.9805
Epoch 4/30
469/469 [==============================] - 1s 2ms/step - loss: 0.0964 - accuracy: 0.9740 - val_loss: 0.0997 - val_accuracy: 0.9766
Epoch 5/30
469/469 [==============================] - 1s 2ms/step - loss: 0.0856 - accuracy: 0.9771 - val_loss: 0.0547 - val_accuracy: 0.9883
Epoch 6/30
469/469 [==============================] - 1s 2ms/step - loss: 0.0858 - accuracy: 0.9769 - val_loss: 0.0618 - val_accuracy: 0.9844
Epoch 7/30
469/469 [==============================] - 1s 2ms/step - loss: 0.0754 - accuracy: 0.9802 - val_loss: 0.0828 - val_accuracy: 0.9766
Epoch 8/30
469/469 [==============================] - 1s 2ms/step - loss: 0.0746 - accuracy: 0.9804 - val_loss: 0.1324 - val_accuracy: 0.9688
Epoch 9/30
469/469 [==============================] - 1s 2ms/step - loss: 0.0708 - accuracy: 0.9822 - val_loss: 0.1227 - val_accuracy: 0.9648
[0.9156666398048401, 0.9632666707038879, 0.9693999886512756, 0.9739833474159241, 0.9771000146865845, 0.9768666625022888, 0.9801666736602783, 0.9803833365440369, 0.9822499752044678]
79/79 [==============================] - 0s 3ms/step - loss: 0.1345 - accuracy: 0.9684

2.Dropout

1.API
- layer.Dropout(rate)
- tf.nn.dropout(x,rate)
起到的作用是不加Dropout就是直连,但加上这一层,在两层之间有一定概率断掉,增加了鲁棒性
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dropout(0.1),
layers.Dense(128, activation='relu'),
layers.Dropout(0.1),
layers.Dense(64, activation='relu'),
layers.Dropout(0.1),
layers.Dense(32, activation='relu'),
layers.Dropout(0.1),
layers.Dense(10)])
2.案例—简街代码
from tensorflow.keras.layers import Input, Dense, BatchNormalization, Dropout, Concatenate, Lambda, GaussianNoise, Activation
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.losses import BinaryCrossentropy
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.layers.experimental.preprocessing import Normalization
import tensorflow as tf
import numpy as np
import pandas as pd
from tqdm import tqdm
from random import choices
# 第一个改变
SEED = 1111
tf.random.set_seed(SEED)
np.random.seed(SEED)
train = pd.read_csv('../input/jane-street-market-prediction/train.csv')
train = train.query('date > 85').reset_index(drop = True)
# 删选了值
train = train[train['weight'] != 0]
# 用均值填充
train.fillna(train.mean(),inplace=True)
# resp>0,则action为1
train['action'] = ((train['resp'].values) > 0).astype(int)
features = [c for c in train.columns if "feature" in c]
f_mean = np.mean(train[features[1:]].values,axis=0)
resp_cols = ['resp_1', 'resp_2', 'resp_3', 'resp', 'resp_4']
X_train = train.loc[:, train.columns.str.contains('feature')]
#y_train = (train.loc[:, 'action'])
y_train = np.stack([(train[c] > 0).astype('int') for c in resp_cols]).T
def create_mlp(
num_columns, num_labels, hidden_units, dropout_rates, label_smoothing, learning_rate
):
inp = tf.keras.layers.Input(shape=(num_columns,))
x = tf.keras.layers.BatchNormalization()(inp)
x = tf.keras.layers.Dropout(dropout_rates[0])(x)
for i in range(len(hidden_units)):
x = tf.keras.layers.Dense(hidden_units[i])(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation(tf.keras.activations.swish)(x)
x = tf.keras.layers.Dropout(dropout_rates[i + 1])(x)
x = tf.keras.layers.Dense(num_labels)(x)
out = tf.keras.layers.Activation("sigmoid")(x)
model = tf.keras.models.Model(inputs=inp, outputs=out)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(label_smoothing=label_smoothing),
metrics=tf.keras.metrics.AUC(name="AUC"),
)
return model
batch_size = 5000
hidden_units = [150, 150, 150]
dropout_rates = [0.2, 0.2, 0.2, 0.2]
label_smoothing = 1e-2
learning_rate = 1e-3
clf = create_mlp(
len(features), 5, hidden_units, dropout_rates, label_smoothing, learning_rate
)
clf.fit(X_train, y_train, epochs=200, batch_size=5000)
3.SGD—随机梯度下降
节省显存
由原来的整个数据集的平均梯度变成一个Batch的平均梯度


六、BatchNormaliation—神经网络优化
该优化策略可分为两步:
第一步:通过零均值化每一层的输入,使每一层拥有服从相同分布的输入样本,因此克服内部协方差偏移的影响
第二步:数据简化,选择每个Batch进行Normaliation
训练深度网络时,神经网络隐藏层参数更新会导致网络输出层输出数据的分布发生变化,而且随着层数的增加,根据链式法则,这种偏移现象会逐渐被放大。BatchNormaliation层每次会input数据归一化,然后在进入输入层。
该优化策略的优势:
- 收敛速度更快,由于控制了x的范围,避免由于x范围过大导致的梯度弥散,更容易搜索到最优解
- 更稳定
案例见简街代码
1.详解

对于Sigmoid函数来说,当激活函数的输出值不在有效范围内时,梯度接近于0,梯度弥散,权值很长时间得不到更新,归一化后,值在较小的范围内变动。

x1为较小值,x2为较大值,当w2发生较小变动时,Loss会发生显著变化,当w1发生较小变动时,Loss变化很小。Normaliation可以更快的找到最优解。

原shape为[N,C,H,W],N表示图片数目,C表示通道数,H表示图片的高,W表示图片的宽
现shape为[N,C,H*W]
Batch Norm表示N张图片单通道的归一化
Layer Norm表示单张图片C通道的归一化
Instance Norm 表示单张图片单通道的归一化
Group Norm 表示单张图片多通道(小于C)的归一化



1.案例
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 解决了UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above. [Op:Conv2D]
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers
# 2 images with 4x4 size, 3 channels
# we explicitly enforce the mean and stddev to N(1, 0.5)
x = tf.random.normal([2, 4, 4, 3], mean=1., stddev=0.5)
net = layers.BatchNormalization(axis=-1, center=True, scale=True,
trainable=True)
out = net(x)
print('forward in test mode:', net.variables)
out1 = net(x, training=True)
print('forward in train mode(1 step):', net.variables)
for i in range(100):
out = net(x, training=True)
print('forward in train mode(100 steps):', net.variables)
optimizer = optimizers.SGD(lr=1e-2)
for i in range(10):
with tf.GradientTape() as tape:
out = net(x, training=True)
loss = tf.reduce_mean(tf.pow(out, 2)) - 1
grads = tape.gradient(loss, net.trainable_variables)
optimizer.apply_gradients(zip(grads, net.trainable_variables))
# 测试集中没有backward-更新β、γ
print('backward(10 steps):', net.variables)
forward in test mode: [<tf.Variable 'batch_normalization/gamma:0' shape=(3,) dtype=float32, numpy=array([1., 1., 1.], dtype=float32)>, <tf.Variable 'batch_normalization/beta:0' shape=(3,) dtype=float32, numpy=array([0., 0., 0.], dtype=float32)>, <tf.Variable 'batch_normalization/moving_mean:0' shape=(3,) dtype=float32, numpy=array([0., 0., 0.], dtype=float32)>, <tf.Variable 'batch_normalization/moving_variance:0' shape=(3,) dtype=float32, numpy=array([1., 1., 1.], dtype=float32)>]
forward in train mode(1 step): [<tf.Variable 'batch_normalization/gamma:0' shape=(3,) dtype=float32, numpy=array([1., 1., 1.], dtype=float32)>, <tf.Variable 'batch_normalization/beta:0' shape=(3,) dtype=float32, numpy=array([0., 0., 0.], dtype=float32)>, <tf.Variable 'batch_normalization/moving_mean:0' shape=(3,) dtype=float32, numpy=array([0.00976992, 0.0118203 , 0.00990692], dtype=float32)>, <tf.Variable 'batch_normalization/moving_variance:0' shape=(3,) dtype=float32, numpy=array([0.9930444, 0.9923902, 0.9919932], dtype=float32)>]
forward in train mode(100 steps): [<tf.Variable 'batch_normalization/gamma:0' shape=(3,) dtype=float32, numpy=array([1., 1., 1.], dtype=float32)>, <tf.Variable 'batch_normalization/beta:0' shape=(3,) dtype=float32, numpy=array([0., 0., 0.], dtype=float32)>, <tf.Variable 'batch_normalization/moving_mean:0' shape=(3,) dtype=float32, numpy=array([0.6229577 , 0.75369585, 0.6316934 ], dtype=float32)>, <tf.Variable 'batch_normalization/moving_variance:0' shape=(3,) dtype=float32, numpy=array([0.55648977, 0.51477736, 0.48946366], dtype=float32)>]
backward(10 steps): [<tf.Variable 'batch_normalization/gamma:0' shape=(3,) dtype=float32, numpy=array([0.9355103, 0.9355681, 0.9356216], dtype=float32)>, <tf.Variable 'batch_normalization/beta:0' shape=(3,) dtype=float32, numpy=array([ 3.4645198e-09, -1.7657877e-08, 1.3411044e-09], dtype=float32)>, <tf.Variable 'batch_normalization/moving_mean:0' shape=(3,) dtype=float32, numpy=array([0.6568097 , 0.7946524 , 0.66602015], dtype=float32)>, <tf.Variable 'batch_normalization/moving_variance:0' shape=(3,) dtype=float32, numpy=array([0.5323891 , 0.4884099 , 0.46172065], dtype=float32)>]