过拟合的原因是算法的学习能力过强;一些假设条件(如样本独立同分布)可能是不成立的;训练样本过少不能对整个空间进行分布估计。以下介绍几种常见的处理方法。
1. Dropout
1.1 分布式特征表达
分布式表征(Distributed Representation),是人工神经网络研究的一个核心思想。简单来说,就是当我们表达一个概念时,神经元和概念之间不是一对一对应映射(map)存储的,它们之间的关系是多对多。具体而言,就是一个概念可以用多个神经元共同定义表达,同时一个神经元也可以参与多个不同概念的表达,只不过所占的权重不同罢了。
举例,对于“小红汽车”这个概念,如果用分布式特征地表达,那么就可能是一个神经元代表大小(形状:小),一个神经元代表颜色(颜色:红),还有一个神经元代表车的类别(类别:汽车)。只有当这三个神经元同时被激活时,就可以比较准确地描述我们要表达的物体。
分布式表征表示有很多优点,其中一点是当部分神经元发生故障时,信息的表达不会出现覆灭性的破坏。比如,我们常在影视作品中看到这样的场景,仇人相见分外眼红,一人(A)发狠地说,“你化成灰,我都认识你(B)!”这里是说,当事人B外表变了很多(对于识别人A来说,B在其大脑中的信息存储是残缺的),但没有关系,只要B的部分核心特征还在,那A还是能够把B认得清清楚楚、真真切切!
利用神经网络的分布式特征表达(只要能保留核心特征),既可以实现成功完成任务(例如成功识别图片为猫),还可以用来阻止过拟合的发生,分布式特征表达可称为Dropout的来源。
1.2 Dropout工作原理
在深度学习中广为使用的技巧:丢弃学习(Dropout Learning)。核心思想和前文讲解的分布式特征表达有异曲同工之妙,关键就是保留核心特征。
“丢弃学习(Dropout,也称为“随机失活”)”是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。“丢弃学习”通常分为两个阶段:学习阶段和测试阶段。
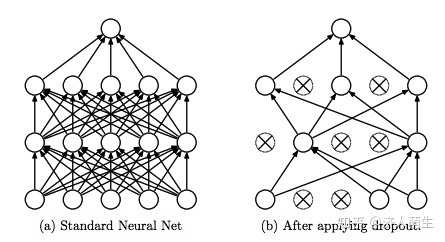
【学习阶段】以概率p主动临时性地忽略掉部分隐藏节点,算法步骤如下:
1. 首先随机删掉网络中的一些隐藏神经元,一般情况下输入输出神经元保持不变
2. 把输入x通过修改后的网络前向传播,删除的神经元不进行前向传播,传给下一层的值是0,然后把得到的损失结果通过修改后的网络反向传播。一小批训练样本执行完这个过程后就按照随机梯度下降法更新没有被删除的神经元对应的参数(w,b)。这样,每一个batch训练之后,只有那些没有被删除的神经元更新了参数,那些被删除的神经元未更新参数。

3. 恢复被删掉的神经元,此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新。
4. 不断重复上述过程1,2,3:
- 从隐藏神经元中随机选择一些神经元临时删除掉(备份被删除神经元的参数)。
- 对小批训练样本,先前向传播,然后反向传播损失并根据随机梯度下降更新参数(w,b)
- 恢复被删掉的神经元,此时被删除的神经元参数不变,而没有被删除的神经元已经有所更新
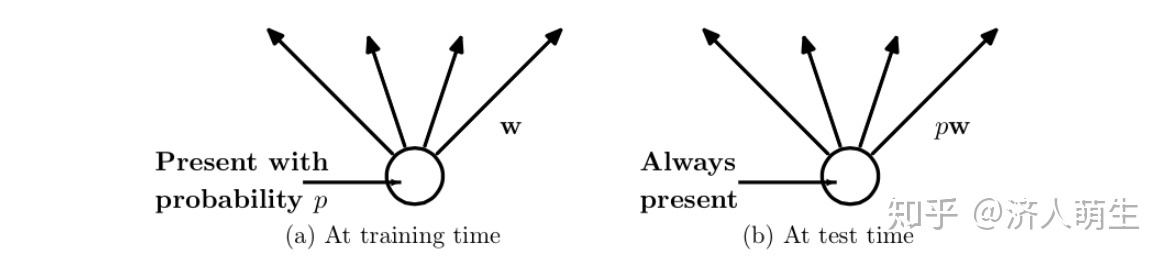
【测试阶段】将参与学习的节点和那些被隐藏的节点以一定的概率p加权求和,综合计算得到网络的输出。预测的时候,每一个单元的参数要预乘以p。
1.3 Dropout如何防止过拟合
(1)数据层面
对于每一个dropout后的网络,进行训练时,相当于做了Data Augmentation。比如,对于某一层,dropout一些单元后,形成的结果是(1.5,0,2.5,0,1,2,0),其中0是被drop的单元。这样每一次dropout其实都相当于增加了样本。
(2)模型层面
i. 在较大程度上减小了网络的大小
在这个“残缺”的网络中,让神经网络学习数据中的局部特征(即部分分布式特征),但这些特征也足以进行输出正确的结果。
ii. Dropout思想类似于集成学习中的Bagging思想 (Bootstrap)
由学习阶段可知,每一次训练都会按keep_probability=p来保留每个神经元,这意味着每次迭代过程中,随机删除一些神经元,这就意味着在多个"残缺"的神经网络中,每次都进行随机的特征选择,这要比仅在单个健全网络上进行特征学习,其泛化能力来得更加健壮。
由此思想可知如下两个作用:
- 取平均的作用: 先回到正常的模型(没有dropout),我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。(例如 3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果)。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。每次训练随机dropout掉不同的隐藏神经元,网络结构已经不同,这就类似在训练不同的网络,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
- 减少神经元之间共适应关系: 因为dropout导致两个神经元不一定每次都在一个网络中出现,这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况, 迫使网络去学习更加鲁棒的特征。换句话说,假如神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的模式(鲁棒性)。(这个角度看 dropout 有点像L1,L2正则,减少权重,使得网络对丢失特定神经元连接的鲁棒性提高)
2. L1 L2 正则化
机器学习中,如果参数过多,模型过于复杂,容易造成overfitting。即模型在训练样本数据上表现的很好,但在实际测试样本上表现的较差,不具备良好的泛化能力。为了避免过拟合,最常用的一种方法是使用使用正则化,例如 L1 和 L2 正则化。

2.1 L2 regularization(ridge regression)
L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和:

其中,Ein 是训练样本loss,λ 是正则化参数. 这样做的好处就是使参数的weight不要太大。例如,使用多项式(polynomial)模型,如果使用 10 阶(order)多项式,模型可能过于复杂,容易发生过拟合。所以,为了防止过拟合,我们可以将其高阶部分的权重 w 限制为 0,这样,就相当于从高阶的形式转换为低阶。
为了达到这一目的,最直观的方法就是限制 w 的个数,但是这类条件属于 NP-hard 问题,求解非常困难。所以,一般的做法是寻找更宽松的限定条件:
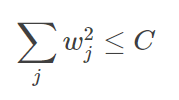
上式是对 w 的平方和做数值上界限定,即所有w 的平方和不超过参数 C。这时候,我们的目标就转换为:最小化训练样本误差 Ein,但是要遵循 w 平方和小于 C 的条件(condition)。
2.2 L1 regularization (lasso regression)
类似的,L1正则化的公式为:
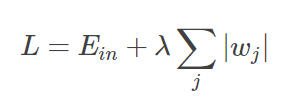
我们的目标就转换为:最小化训练样本误差 Ein,但是要遵循 w 的绝对值和小于 C 的条件。
2.3 L1 和 L2的比较
L1和L2都是为了达到权重的sparsity.

黄色区域是正则化条件(,
). 蓝色的圆圈表示loss的等值线, 同一个圆上的损失函数值相等的,圆的半径越大表示损失值越大。(中心点最小)
如果没有L1和L2正则化约束的话,w1和w2是可以任意取值的,损失函数可以优化到中心的最小值的。
但是填了L1和L2正则化约束就把解空间约束在了黄色的平面内。黄色图像的边缘与损失函数等值线的交点,便是满足约束条件的损失函数最小化的模型的参数的解。 由于L1正则化约束的解空间是一个菱形,所以等值线与菱形端点相交的概率比与线的中间相交的概率要大很多,端点在坐标轴上,一些参数的取值便为0。L2正则化约束的解空间是圆形,所以等值线与圆的任何部分相交的概率都是一样的,所以也就不会产生稀疏的参数。
总结一下:L1 正则化的解具有稀疏性(降维);而L2只是使一些权重更加接近零,但很小的可能会是零。L1范数可以使权值稀疏,方便特征提取; L2范数可以防止过拟合,提升模型的泛化能力。
3. 其他有用的方法
- a.早停止:如在训练中多次迭代后发现模型性能没有显著提高就停止训练
- b.数据集扩增:原有数据增加;原有数据加随机噪声,经过变换生成新的数据(数据增强)
- c.交叉验证:在验证集上准确率开始下降时,停止训练
-
d.特征选择/特征降维
参考资料:
[1] https://www.zhihu.com/question/275788133/answer/384198714