Flink基本概念
1.The history of Flink?
2.What is Flink?
Apache Flink是一个开源的分布式、高性能、高可用、准确的流处理框架,主要由Java代码实现,支持实时流(stream)处理和批(batch)处理,批数据只是流数据的一个极限的特例。原生支持了迭代管理、内存计算和程序优化。
3.The Feature of Flink?
流式优先(streaming-first:连续处理),容错(fault-tolerant:有状态的计算),可伸缩(scalable:可支持上千个节点),性能(performance:高吞吐-每秒处理的数据量很大、低延迟-数据产生时Flink立刻可以处理掉 数据的产生到处理间隔的时间很短)。
4.The Architecture of Flink?
(1)部署deploy : 支持local(single jvm)、支持cluster(standalone、yarn)、支持cloud(GCE、EC2) (2)核心core : 分布式流处理框架 (3)APIs : DataStream API、DataSet API (4)Libraries : DataStream API -- CEP、Table,DataSet API -- FLinkML、Gelly、Table

5.The basic components of Flink?
Data Source、Transformations、Data Sink
6.The Distributed Execution about Flink?
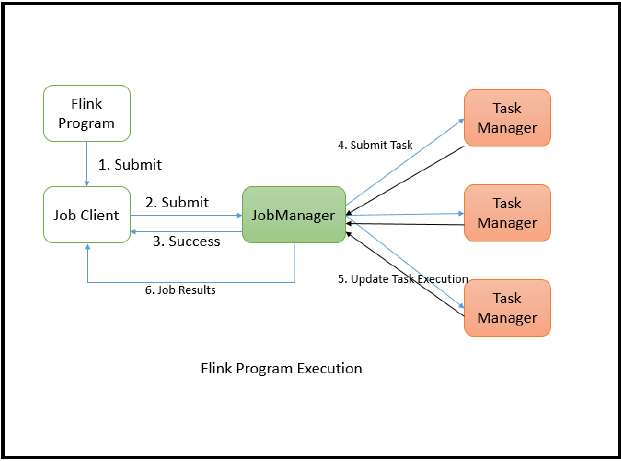
7.The different between Batch Processing and Streaming Processing?
流处理是一个节点把一条记录处理完后序列化到缓存里另一个节点立刻把数据从缓存中拉过去进行处理,批处理是一个节点处理一条记录放入缓存中另一个节点不会立刻从缓存中拉取记录直到所有的记录都执行完为止在统一从缓存里拉取数据。
8.The diagram of Flink Cluster?

9.The application scene of Flink?
优化电商网站的实时搜索结果如阿里巴巴的实时更新产品细节使用Flink,实时更新库存细节使用Blink。
10.Flink vs Storm vs Spark Streaming vs Trident?
Flink可以通过设置阈值来实现流处理或批处理,如果将阈值设为0那么就相和Storm一样的实时流处理来一条数据处理一条,真正的实现了低延迟但是相对的吞吐量会降低,如果阈值设为无限大相当于批处理一样那么吞吐量会提高却无法实现低延迟的效果,当然根据实际情况可以吧把值设为合适的值。Storm就是实时流处理来一条数据处理一条,保证数据至少被处理一次,所以可能会处理重复,其他三者都是保证了仅一次的处理。Spark Streaming是微批处理(mirco-batching),本质上不属于实时流处理,而是每隔一定的时间段会处理一次数据,一批一批的小批量处理。Trident是基于Storm的一个封装,是一批一批的小批量处理。