目录
- 1、Flink简介
- 2、Flink架构图
- 3、Flink基本组件介绍
- 4、Flink的流处理与批处理
- 5、Flink应用场景分析
- 6、Flink\Storm\SparkStreaming的比较
- 7、Flink入门案例 – WordCount
- 8、Flink scala shell代码调试
1、Flink简介

Flink是一个分布式大数据计算引擎,可对有限流和无限流进行有状态的计算,支持Java API和Scala API、高吞吐量低延迟、支持事件处理和无序处理、支持一次且仅一次的容错担保、支持自动反压机制、兼容Hadoop、Storm、HDFS和YARN。

2、Flink架构图

越底层API越灵活、越上层越轻便。
| low level | Stateful stream Processing(Core API的底层实现,开发较为复杂) |
|---|---|
| ↓ | Core API(DataStream\DataSet API) |
| ↓ | Table API |
| high level | SQL |

3、Flink基本组件介绍

(1) DataSource是指数据处理的数据源,可以是HDFS\Kafka\Hive等;
(2) Transformations是指对数据的处理转换的函数方法;
(3) DataSink指数据处理完成之后处理结果的输出目的地,可以是MySQL\HBase\HBFS等;
4、Flink的流处理与批处理
在大数据处理领域,批处理任务与流处理任务一般被认为是两种不同的任务,一个大数据框架一般会被设计为只能处理其中一种任务,例如Storm只支持流处理任务,而MapReduce、Spark只支持批处理任务。Spark Streaming是Apache Spark之上支持流处理任务的子系统,看似是一个特例,其实并不是——Spark Streaming采用了一种micro-batch的架构,即把输入的数据流切分成细粒度的batch,并为每一个batch数据提交一个批处理的Spark任务,所以Spark Streaming本质上还是基于Spark批处理系统对流式数据进行处理,和Storm等完全流式的数据处理方式完全不同。
Flink通过灵活的执行引擎,能够同时支持批处理任务与流处理任务。
在执行引擎这一层,流处理系统与批处理系统最大不同在于节点间的数据传输方式。对于一个流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理;而对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。这两种数据传输模式是两个极端,对应的是流处理系统对低延迟的要求和批处理系统对高吞吐量的要求。 Flink的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型。
Flink以固定的缓存块为单位进行网络数据传输,用户可以通过设置缓存块超时值指定缓存块的传输时机。如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟;如果缓存块的超时值为无限大,则Flink的数据传输方式类似上文所提到批处理系统的标准模型,此时系统可以获得最高的吞吐量;同时缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阈值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量。

5、Flink应用场景分析
Ⅰ、优化电商网站的实时搜索结果
Ⅱ、阿里巴巴的所有基础设施团队使用flink实时更新产品细节和库存信息(Blink)
Ⅲ、针对数据分析团队提供实时流处理服务
Ⅳ、通过flink数据分析平台提供实时数据分析服务,及时发现问题
Ⅴ、网络/传感器检测和错误检测
Ⅵ、Bouygues电信公司,是法国最大的电信供应商之一,使用flink监控其有线和无线网络,实现快速故障响应
Ⅶ、商业智能分析ETL
Ⅷ、Zalando使用flink转换数据以便于加载到数据仓库,将复杂的转换操作转化为相对简单的并确保分析终端用户可以更快的访问数据(实时ETL)
6、Flink\Storm\SparkStreaming的比较


实时框架该如何选择?
1:需要关注流数据是否需要进行状态管理;
2:At-least-once或者Exectly-once消息投递模式是否有特殊要求;
3:对于小型独立的项目,并且需要低延迟的场景,建议使用storm;
4:如果你的项目已经使用了spark,并且秒级别的实时处理可以满足需求的话,建议使用sparkStreaming;
5:要求消息投递语义为 Exactly Once 的场景;数据量较大,要求高吞吐低延迟的场景;需要进行状态管理或窗口统计的场景,建议使用flink。
7、Flink入门案例 -- WordCount





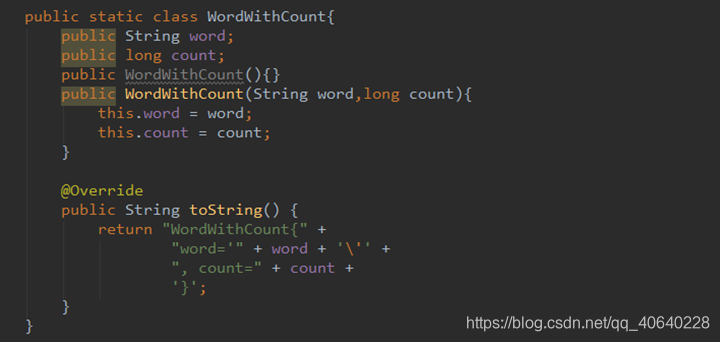
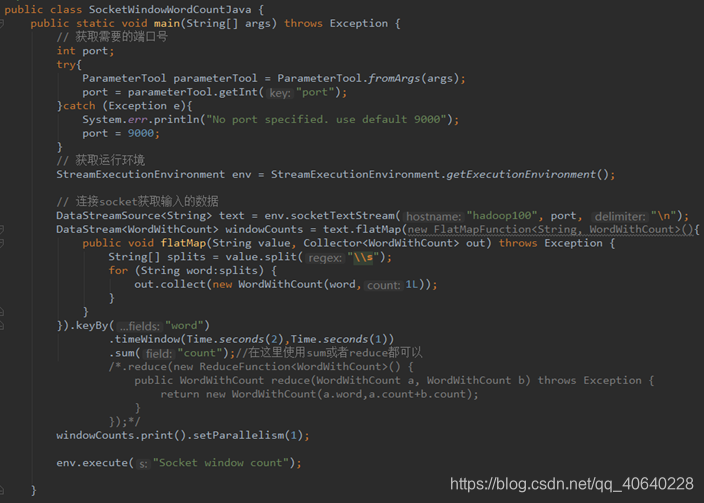
Flink WordCount 实时处理 Java版本代码:
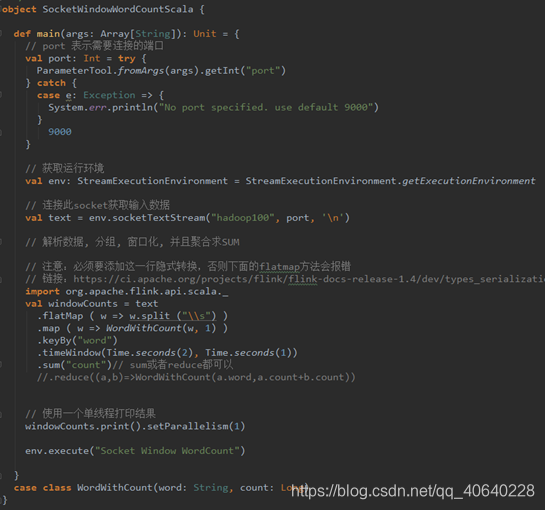
Flink WordCount 实时处理 Scala版本代码:
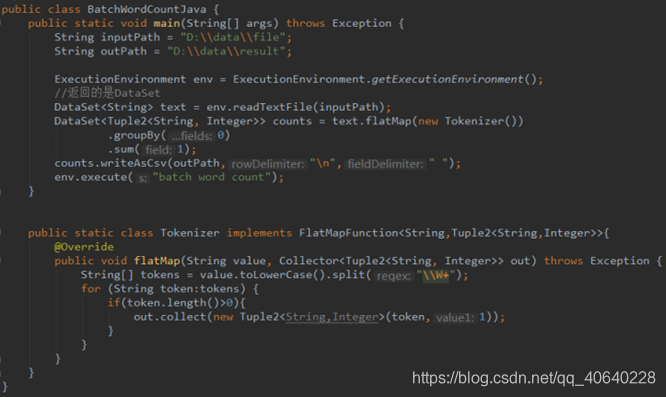
Flink WordCount 批处理 Java版本代码:
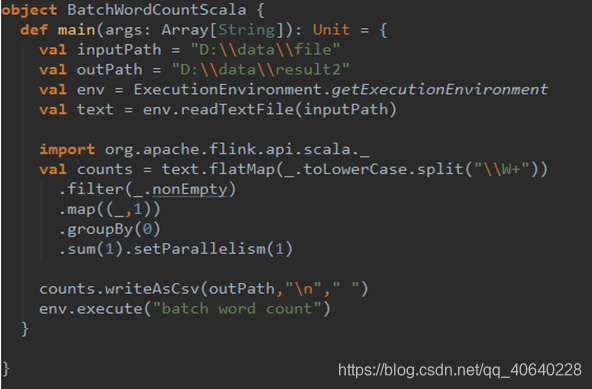
Flink WordCount 批处理 Scala版本代码:

8、Flink scala shell代码调试
针对初学者,开发的时候容易出错,如果每次都打包进行调试,比较麻烦,并且也不好定位问题,可以在scala shell命令行下进行调试;
scala shell方式支持流处理和批处理。当启动shell命令行之后,两个不同的ExecutionEnvironments会被自动创建。使用senv(Stream)和benv(Batch)分别去处理流处理和批处理程序。(类似于spark-shell中sc变量)
bin/start-scala-shell.sh [local|remote|yarn] [options]

看到这里的,需要深入学习的可以看剩下的帖子,总共有八章节。
