1 Flink 的角色
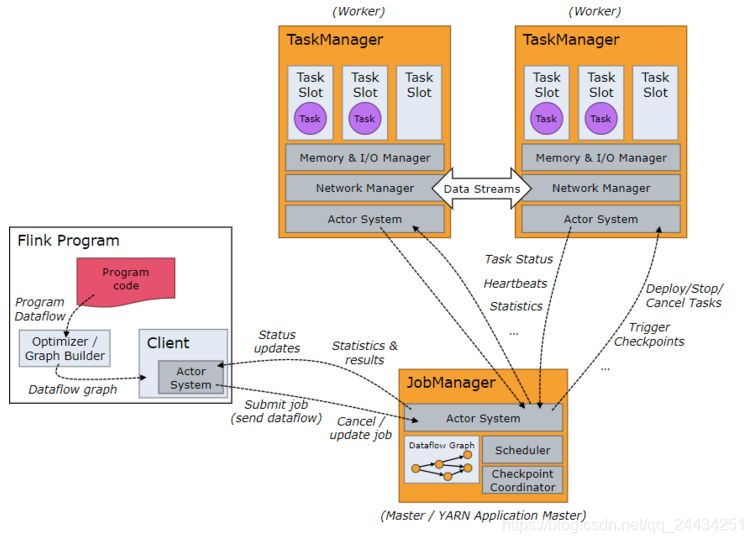
Flink 在运行时,主要由两种角色组成 JobManager 和 TaskManager。
JobManager主要是负责接受客户端的 Job,调度 Job,协调 checkpoints,故障恢复等。
TaskManager主要是负责执行具体的 Task。JobManager 和 TaskManager 的通信类似于 Spark 早期版本使用的 actor系统。
如下图:
2 任务链
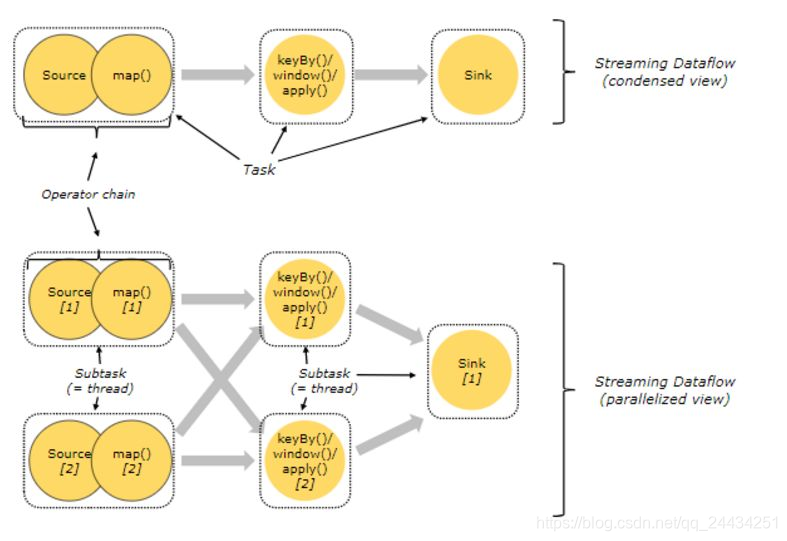
首先,Flink 中的 Task 是什么?
Flink 中的每个算子都可以设置并行度,每个算子的一个并行度实例就是一个 subTask。
由于 Flink 的 TaskManager 运行 Task 的时候是每个 Task 采用一个单独的线程,这会带来很多线程切换和数据交换的开销,进而影响吞吐量。
为了减轻这种情况,Flink 会在 JobGraph 阶段,将代码中可以优化的算子优化成一个算子链(Operator Chains)以放到一个 Task 中执行。
用户也可以自己指定相应的链条,将相关性非常强的转换操作绑定在一起,这样能够让转换过程中上下游的 Task 在同一个 Pipeline 中执行,进而避免因为数据在网络或者线程间传输导致的开销,提高整体的吞吐量和延迟。
一般情况下,Flink 在 Map 操作中默认开启 TaskChain,以提高 Flink 作业的整体性能。
如图1,Source 和 Map 在优化后,组成一个算子链,作为一个 task 运行在一个线程上,其简图如 Condensed view 所示,并行图如 parellelized view 所示。
3 Task Slots (任务槽)和 Resources (资源)
每一个 TaskManager 都是 JVM 进程,可以执行一个或者多个 Task 在不同的线程中。
为了能控制一个 TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念。
每一个 Task Slot 代表着 TaskManager 的一个固定的资源子集,是提供资源的最小单元。
例如一个拥有3个 Task Slot 的 TaskManager 将为每个 Task Slot 分配 1/3 的托管内存。
将资源 slot 化意味着来自不同 job 的 task 不会为了内存而竞争,而是每个 task 都拥有一定数量的内存储备。
注意这里不会涉及到 CPU 的隔离,仅仅用来隔离内存。
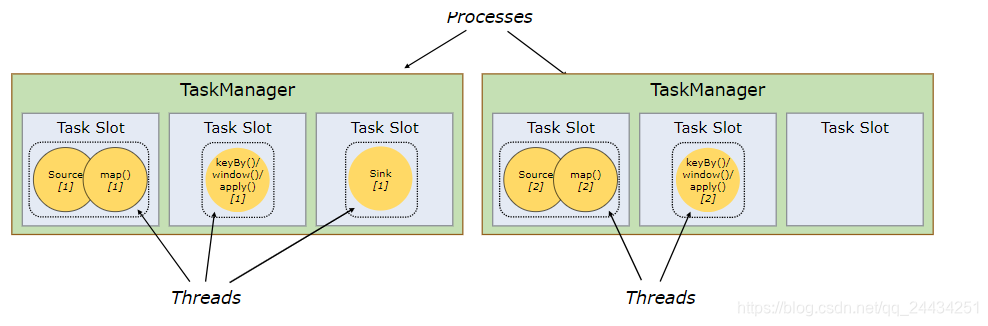
如图2,有两个节点(TaskManager),每个节点3个 slot,每一个 Task (一个 Thread)均跑在一个 slot 中。
但实际上,Flink 在默认情况下,只要子任务是来自同一个 job,是允许子任务(类似 source/map,Window)共享一个 slot 的。
这样有两个好处:
1)不用计算一个程序中有多少个 task ,因为一个 Job 的最高并行度就是 Flink 集群中 slot 的个数;
2)可以获得更好的资源利用率。
若没有 slot 共享,像 source/map 这种不是非常耗费资源的算子 会和 window 这种非常耗资源的算子占用相同的多的资源(1个slot)。
若允许 slot 共享,集群最大的并行度可为6。如下图3所示:
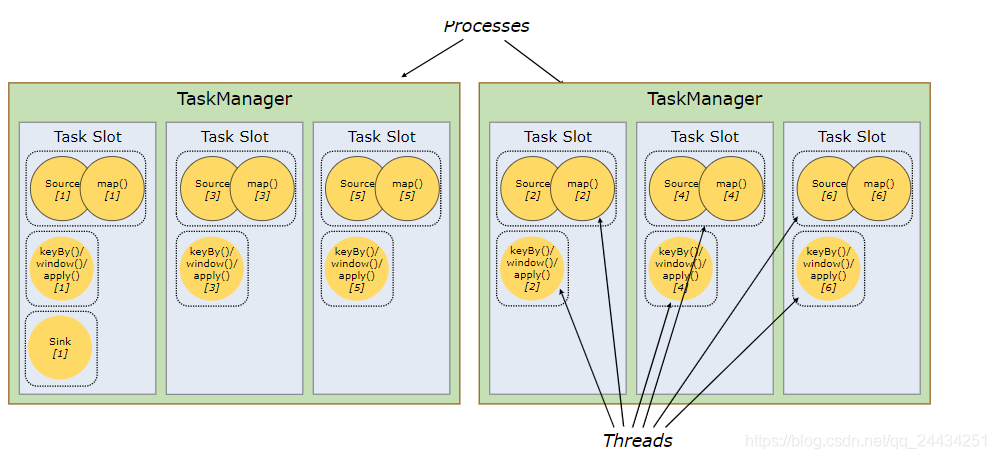
较耗费资源的 subtasks 比较均匀的分布在 flink 集群的 taskManager 上
如图2,window 仅仅在2个 slot 中;
而图3中,window 均匀分布在每个算子中;
从图3,也可以看出,一个 slot 中,可以运行多个 thread 的。
关注公众号,获得更多实时计算架构的文章
