支持流处理,也支持批处理。Flink最大的原则就是,以流处理为根本。Flink认为批处理应该在流处理上实现。通过插入barrier事件来标记微批,收到该事件后,进行checkpoint快照。发现处理失败,就根据快照恢复然后进行流重放。
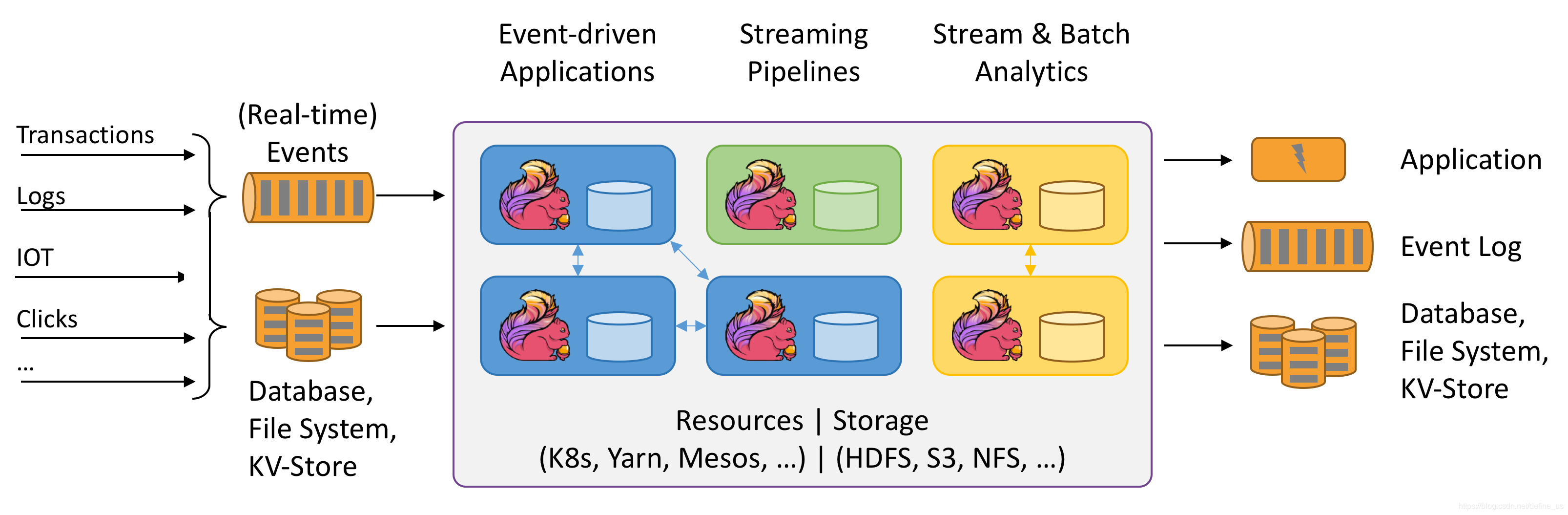
flink的checkpoint机制非常轻量,barrier不会打断streaming的流动,而且做checkpoint操作也是异步的。其次,相比storm需要ack每条data,flink做的是相当于small batch的checkpoint,容错的代价相对要低很多。最重要的是flink的checkpoint机制能保证exactly once。(装作Trident不存在一脸无辜的我)。
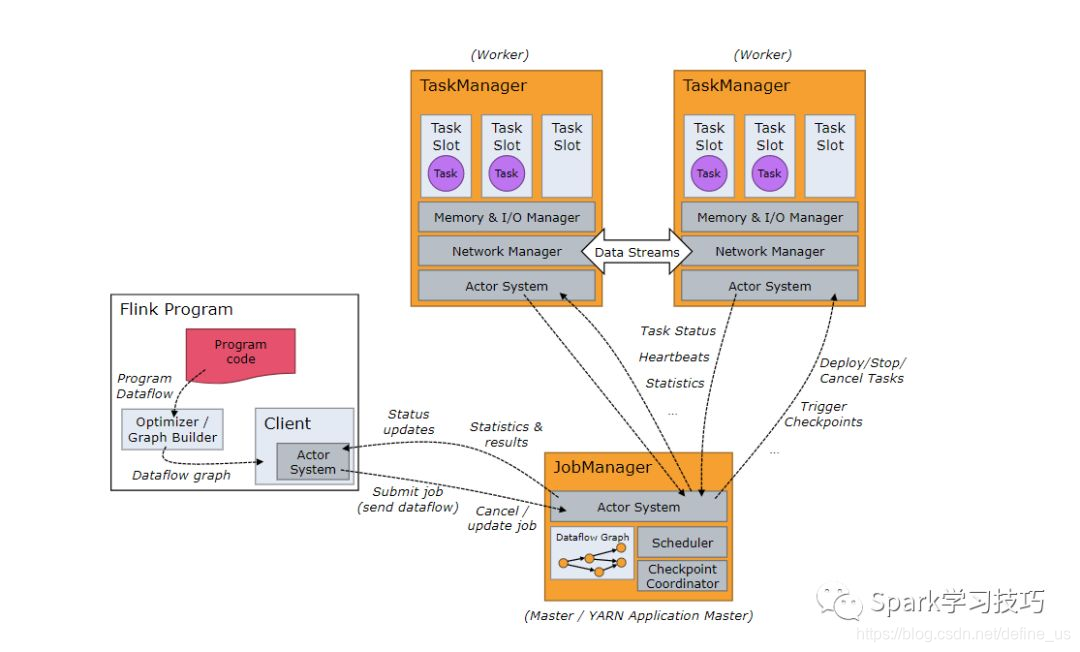
Flink 架构
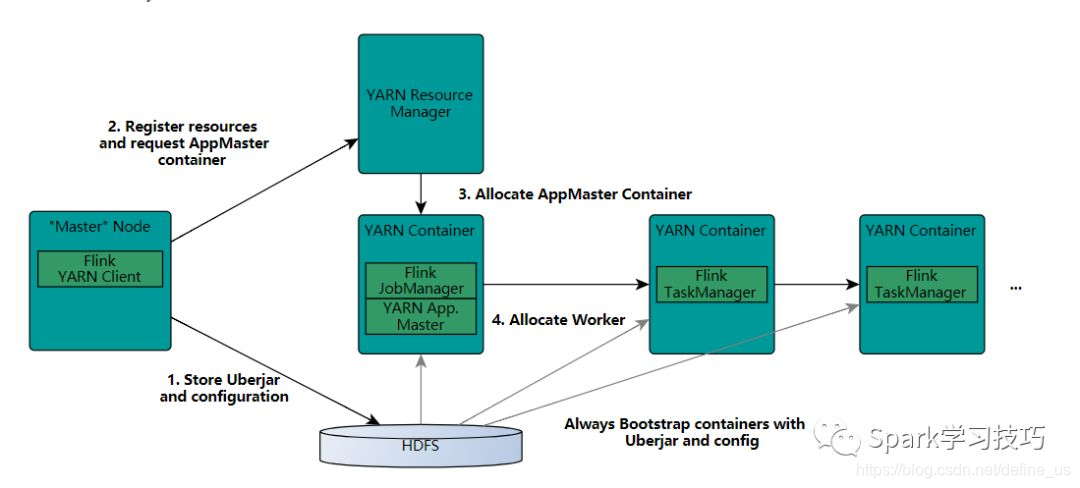
Flink On Yarn
-
FlinkYarnSessionCli 启动的过程中首先会检查Yarn上有没有足够的资源去启动所需要的container,如果有,则上传一些flink的jar和配置文件到HDFS,这里主要是启动AM进程和TaskManager进程的相关依赖jar包和配置文件。
-
接着yarn client会首先向RM申请一个container来启动ApplicationMaster(YarnApplicationMasterRunner进程),然后RM会通知其中一个NM(node manager)启动这个container,被分配到启动AM的NM会首先去HDFS上下载第一步上传的jar包和配置文件到本地,接着启动AM;在这个过程中会启动JobManager,因为JobManager和AM在同一进程里面,它会把JobManager的地址重新作为一个文件上传到HDFS上去,TaskManager在启动的过程中也会去下载这个文件获取JobManager的地址,然后与其进行通信;AM还负责Flink的web 服务,Flink里面用到的都是随机端口,这样就允许了用户能够启动多个yarn session。
-
AM 启动完成以后,就会向AM申请container去启动TaskManager,启动的过程中也是首先从HDFS上去下载一些包含TaskManager(yarn模式的话这里就是YarnTaskManager )主类 的jar和启动过程依赖的配置文件,如JobManager地址所在的文件,然后利用java cp的方式去启动YarnTaskManager ,一旦这些准备好,就可以接受任务了。这个和spark on yarn的yarn cluster模式其实差不多,也是分为两个部分,一个是准备工人和工具(spark是启动sc的过程,flink是初始化ENV的过程),另外一个就是给工人分配具体工作(都是执行具体的操作,action什么的触发)