事件驱动型应用
核心目标:数据流上的有状态计算
Apache Flink是一个框架和分布式处理引擎,用于对无界或有界数据流进行有状态计算。
运行逻辑
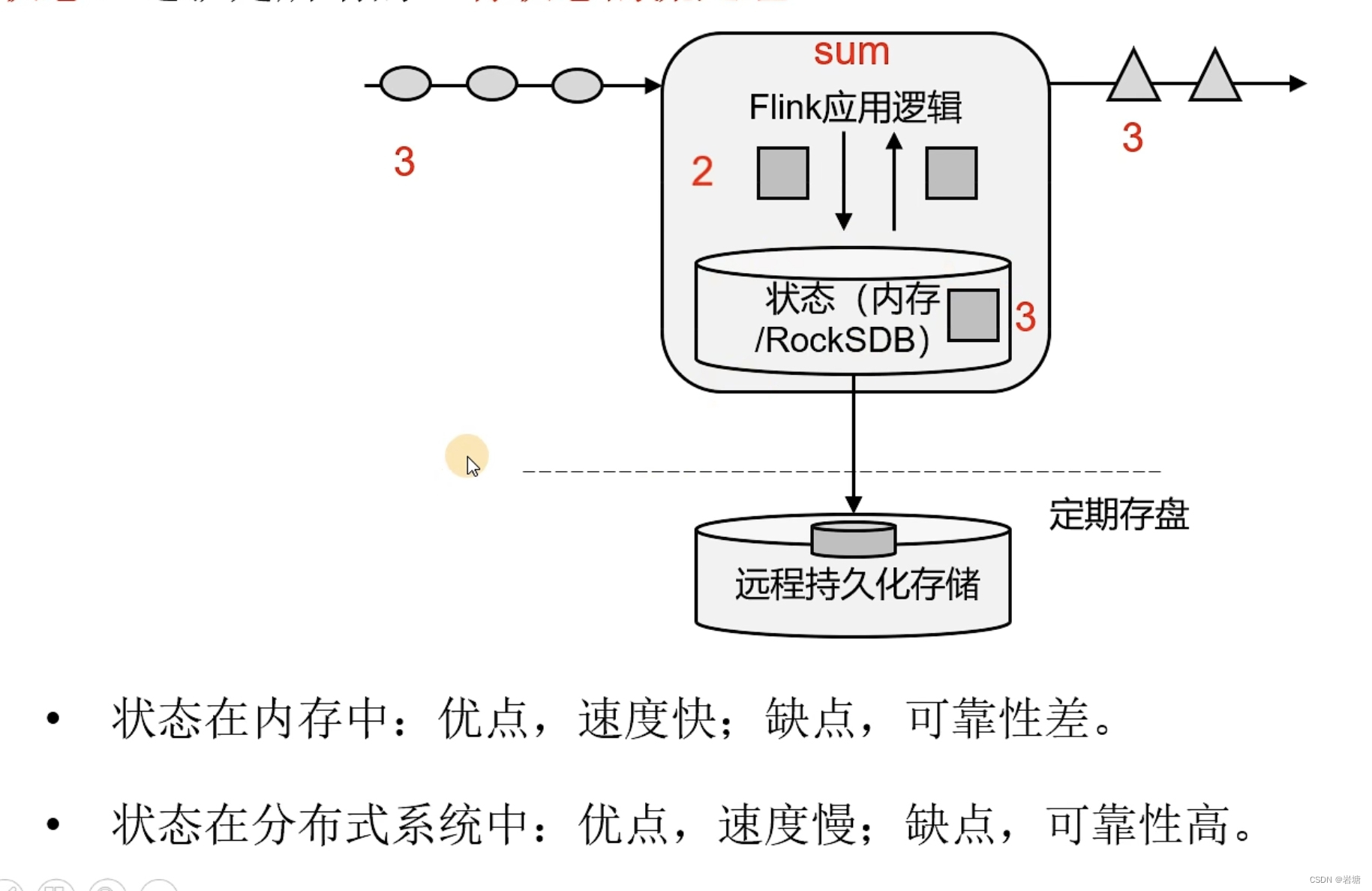
状态
把流处理需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态。这就是所谓的“有状态的流处理”。
无界数据和有界数据
无界数据流
有定义流的开始,但没有定义流的结束
它们会无休止的产生数据
无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的。
有界数据流
有定义流的开始,也有定义流的结束;
有界流可以在摄取所有数据后再进行计算;
有界流所有数据可以被排序,所以并不需要有序摄取;
有界流处理通常被称为批处理。
Flink主要特点
高吞吐和低延迟:每秒处理数百万个事件,毫秒级延迟。
结果的准确性:Flink提供了事件时间(event-time )和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
精确一次(exactly-once)的状态一致性保证。
可以连接到最常用的存储系统,如Kafka、 Hive、JDBC、HDFS、 Redis等。
高可用:本身高可用的设置,加上与K8s, YARN和Mesos的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的停机时间7×24全天候运行。
Flink VS Spark
spark以批处理为根本
flink以流处理为根本
应用场景
1)电商和市场营销
举例:实时数据报表、广告投放、实时推荐
2)物联网( IOT )
举例:传感器实时数据采集和显示、实时报警,交通运输业
3)物流配送和服务业
举例:订单状态实时更新、通知信息推送
4)银行和金融业
举例:实时结算和通知推送,实时检测异常行为