一、絮叨两句
新的一年又来了,不知道大家有没有立几个每年都完不成的 FLAG ?
反正我立了,我今年给自己立的 FLAG 是大致阅读大数据几个框架的源码。
为什么要“大致”阅读,因为这些牛逼的框架都是层层封装,搞懂核心原理已经是很不易,更别谈熟读源码了。
但是目标还是要有的,我也不要当一条咸鱼。
之前几篇源码阅读的文章,不知道大家有没有亲自动手打开 Idea 去试一试,这里我再贴一下文章链接,大家可以再回顾一下。
本次,我们来聊一聊,我们自己写的代码是如何变成 StreamGraph 的。
二、引出问题
开始之前,不妨稍微回顾一下…
一般我们执行一个 Flink 程序,都是使用命令行 flink run(flink 界面上执行的时候,也是在调用 flink run 命令来执行的)来执行,然后shell 会使用 java 命令,执行到 CliFrontend 类的 main 方法。
main 方法里面,首先会解析用户的输入参数,解析 flink-conf.yml 配置文件,解压出用户 jar 包里的依赖,以及其他的信息,都封装到 PackagedProgram 对象中。然后切换当前线程的类加载器为 UserCodeClassLoader,这个类加载器自定义了一些策略(Child-First 或者 Parent-First),使用这个类加载器去反射执行用户代码的 main 方法。
然后今天的故事就从这里开始。
首先我们贴一段 Flink 自带的 Example 里的代码(稍稍简化了代码,去掉了无关的逻辑):
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.fromElements(WordCountData.WORDS);
DataStream<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer())
.keyBy(value -> value.f0).sum(1);
counts.print();
它是如何变成这张图的:
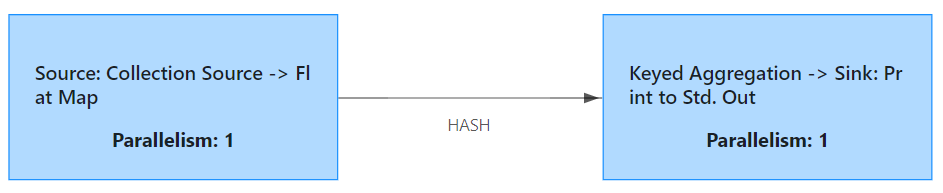
这张图是一个有向无环图,组成有向无环图的就是顶点信息,以及边的信息。
这些信息被封装在 StreamGraph 类之中,这个类中有三个非常重要的属性:
private Map<Integer, StreamNode> streamNodes;
private Set<Integer> sources;
private Set<Integer> sinks;
可以看到这几个属性记录了这个 Graph 中有几个节点,几个是 sources,几个是 sinks。
其中 StreamNode 是对节点的封装,节点上有几个重要的属性如下:
private final String operatorName;
private List<StreamEdge> inEdges = new ArrayList<StreamEdge>();
private List<StreamEdge> outEdges = new ArrayList<StreamEdge>();
operatorName 表示节点的名字,inEdges 表示这个节点上游的边,outEdges 表示这个节点下游的边。
然后,StreamEdge 是对边的封装,只有输入节点 id 和目标节点 id:
private final int sourceId;
private final int targetId;
这三个类的这几个属性就描述了刚刚的那张图。
三、记住一个非常重要的属性
它就是 StreamExecutionEnvironment 类的 transformations 属性:
protected final List<Transformation<?>> transformations = new ArrayList<>();
什么是 Transformation,Transformation 就是 Flink 对我们写的算子的额外信息的封装,比如算子的名字,id,输出类型,输入,并行度等等这些信息。
有些算子最终会调用 this.tranformations.add() 加入到列表里来,而有的不会。
四、从 env.fromElements() 开始
env.fromElements(),这是一个算子,这个算子定义了 source 信息,这个算子对应的 transformation 是 LegacySourceTransformation,里面记录了算子的id,名字,输出类型,并行度,有界还是无界等等信息。
最后这个方法返回的是一个 DataStreamSource 对象,这个对象的基类是 DataStream。DataStream 里有一个 transformation 属性。
也就是说 env.fromElements() 返回了一个 DataStream 对象,并且把它自身的 transformation 信息放到这个 DataStream 实例的属性里面了。
env.fromElements 这个算子是没有加入到 上面的 transformations 列表中去的。
四、FlatMap 算子源码分析
紧接着,上面的 env.fromElements 的返回值: DataStream 实例,调用了它自己的 flatMap 方法,flatMap 最终又调用了 doTransform 方法。
FlatMap 算子也是要构造一个 transformation 的,FlatMap 对应的 transformation 是 OneInputTransformation,这个类里有一个属性是 input,也就是 FlatMap 算子的输入信息。我们看一下它的构造方法
public OneInputTransformation(
Transformation<IN> input,
String name,
StreamOperatorFactory<OUT> operatorFactory,
TypeInformation<OUT> outputType,
int parallelism) {
super(name, outputType, parallelism);
this.input = input;
this.operatorFactory = operatorFactory;
}
再看一下调用信息
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism());
也就是说,FlatMap 的 transformation 信息中,有一个 input 属性,其值是 env.fromElements 的 transformation。
通俗点讲就是,FlatMap 的 transformation 中记录了它的输入是 env.fromElements() 。
最后返回了 SingleOutputStreamOperator 对象,这里面封装了 FlatMap 的 transformation 信息。
我们可以 debug 到这里来看看它的返回值:

然后需要关注的事情是,它最终调用了这个方法:
getExecutionEnvironment().addOperator(resultTransform);
public void addOperator(Transformation<?> transformation) {
Preconditions.checkNotNull(transformation, "transformation must not be null.");
this.transformations.add(transformation);
}
也就是加入到了 transformations 列表中去。
FlatMap 最后返回了一个 SingleOutputStreamOperator 类,这个类也是 DataStream 的子类。
所以,看到这基本能够理解,我们写的代码,其实本质都是 Flink 封装后对外暴露的简单易用的 api,Flink 在背后做了大部分事情。
五、KeyBy 算子源码分析
keyBy 也是 DataStream 的一个方法,它 new 了一个 KeyedStream,并且把 this 传入了构造函数中,this 是什么?this 就是刚刚 FlatMap 的返回值,还记得吗?里面记录了 FlatMap 的 transformation。
keyBy 对应的 transformation 是 PartitionTransformation,里面也有 input 属性,直接把 this.getTransformation() 传给了 input 了。
我们来 debug 看一下返回值:

有点像套娃,一层又一层的。
需要注意的是,KeyBy 只是一个虚拟的节点,它并没有加入到 transformations 列表中来。
六、sum 算子的源码分析
这个我们就不细看了,套路都差不多了,直接 debug 看一下返回值:
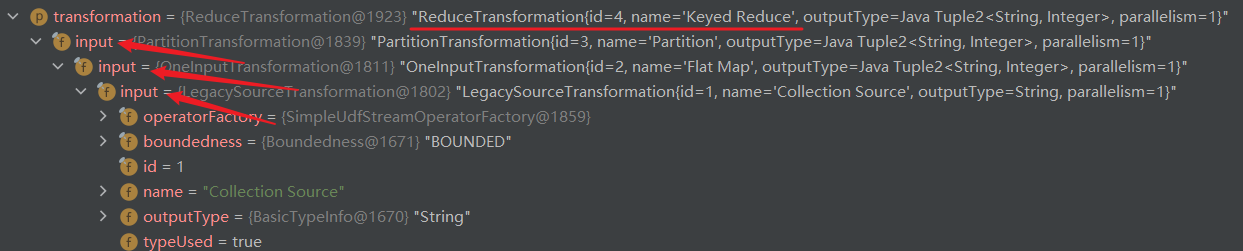
sum 算子有调用这个方法:
getExecutionEnvironment().addOperator(reduce);
加入到了 transformations 属性中来。
七、sink 算子的源码分析
和 sum 一样,我们直接 debug 一下最终的结果:

可见 sink 中,也套娃式的记录了所有的 input。
最后,sink 也调用了
getExecutionEnvironment().addOperator(sink.getTransformation());
九、一小段源码
上次说到了所有的算子都会转化成 transformation ,并放到一个 List 列表中,那么今天我们开始遍历这个列表,来生成 StreamGraph。
打开这个类 StreamGraphGenerator,generate() 方法(252行),StreamGraph 生成的逻辑就是从这里开始的。
里面有一个 for 循环,遍历的就是上次说到的那个非常重要的 transformations 列表:
for (Transformation<?> transformation: transformations) {
transform(transformation);
}
然后看 transform 方法(无关的逻辑被我精简掉了),这个方法的作用是,使用不同的转换器,把算子生成的 transformations,转换成 StreamGraph 。
private Collection<Integer> transform(Transformation<?> transform) {
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
@SuppressWarnings("unchecked")
final TransformationTranslator<?, Transformation<?>> translator =
(TransformationTranslator<?, Transformation<?>>) translatorMap.get(transform.getClass());
Collection<Integer> transformedIds;
if (translator != null) {
transformedIds = translate(translator, transform);
} else {
transformedIds = legacyTransform(transform);
}
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
return transformedIds;
}
首先,看下这个方法的返回值,是一个 Collection<Integer> 类型,也就是说,转换完之后,会返回本次转换的 id。
首先,要获得一个 translator 转换器,可以看到在 static 静态块里,为每一种不同的 transformation 设置了不同的 translator。
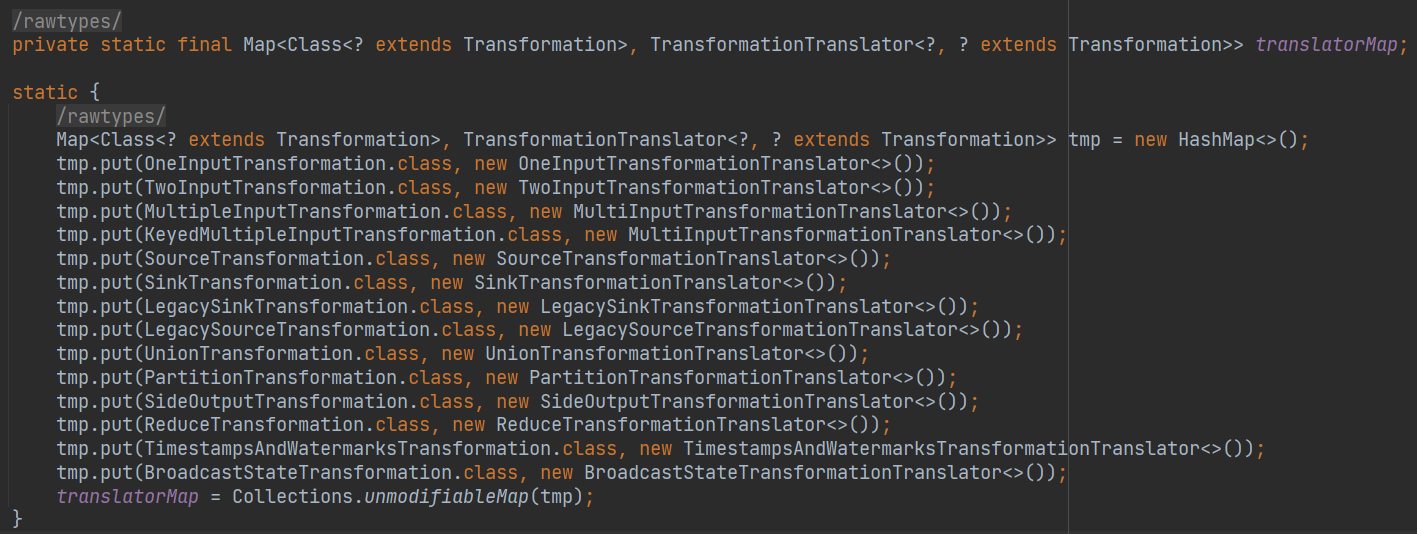
获取到转换器之后,进入 translate 方法中,translate 方法有这样一个方法,getParentInputIds(),这是一个很神奇的方法,他是在递归。
final List<Collection<Integer>> allInputIds = getParentInputIds(transform.getInputs());
赶紧点进去看看:
private List<Collection<Integer>> getParentInputIds(
@Nullable final Collection<Transformation<?>> parentTransformations) {
final List<Collection<Integer>> allInputIds = new ArrayList<>();
if (parentTransformations == null) {
return allInputIds;
}
for (Transformation<?> transformation : parentTransformations) {
allInputIds.add(transform(transformation));
}
return allInputIds;
}
可以看到,它的输入参数是这个 transformation 的 input,然后 for 循环遍历这个 input,for 循环里面又在调用 transform 方法。这就是在递归调用了。
既然是递归调用,那么递归的终止条件是什么呢?
我一开始也很懵啊,debug 的时候,一直在循环往复,头有点大。静下来仔细 debug 了一下,发现终止条件就是:如果没有 input,那就不走到 for 循环里面来,也就直接返回了,这就是终止条件了。
那么,为什么要搞这样的递归调用?
目的就是,在转换一个算子的 transformation 的时候,要把它的上游先转换掉,也就是要从最开始的那个输入开始转换,这样才能顺利的构造出 DAG。
可能看到这,还是很迷茫,没关系,我们拿出具体的数据说话。
十、我们来 debug 一下
下面这个图是当前 transformations 的三个元素

下面的这个是每一个 transformation 的父子关系,括号里是算子的 id,右边是它的 input。
-
Flat Map(2) - Collection Source(1)
-
Keyed Aggregation(4) - Partition(3) - Flat Map(2) - Collection Source(1)
-
Print to Std. out(5) - Keyed Aggregation(4) - Partition(3) - Flat Map(2) - Collection Source(1)
我们从这个 for 循环开始:

当前 transform 方法中,Flat Map 算子作为入参。
它的调用链是:transform -> translate -> getParentInputs -> 遍历 Flat Map 的 inputs ,然后调用 transform 方法

可以看到当前又是在 transform 方法中,但是输入参数是 Collection Source,也就是 Flat Map 的 input。
然后又是依次进入:transform -> translate -> getParentInputs -> 遍历 Collection Source 的 inputs
这个时候,Collection Source 是没有 input 的,所以本次递归就返回了,开始转换 Collection Source。
是用的 LegacySourceTransformationTranslator 这个转换器来转换的,最终就是做了这么一件事,new 了一个 StreamNode,放入了 StreamNodes 的 Map 中。
StreamNode vertex = new StreamNode(
vertexID,
slotSharingGroup,
coLocationGroup,
operatorFactory,
operatorName,
vertexClass);
streamNodes.put(vertexID, vertex);
那么 Collection Source 就处理完了,由于是递归遍历到根节点,那么肯定是会有重复的,所以,已经转换过的,要缓存起来,放到一个 Map 中,下次遇到同样的,就直接跳过了。
Collection Source 处理完了之后,也就是 Flat Map 的 input 处理完了

下面要回来进入 FlatMap 的 translate 方法了(这就是在递归,处理 Flat Map 时,要先处理 Collection Source,等到把 Collection Source 处理完了,再继续回来处理 Flat Map)
FlatMap 是用的 OneInputTransformationTranslator 转换器来转换的。
可以看到它也是一样,new 了一个 StreamNode ,加入到了 streamNodes 列表中。
但是!它还做了另外一件事,那就是:

它还要处理自己的 ParentTransformation,也就是 Collection Source,来构造一个边 Edge。

可以看到这个边,是有方向的,从 Collection Source 到 FlatMap。
然后把这个边放到 Collection Source 的 outEdge 中;再放到 FlatMap 的 inEdge 中。
这样就记录了算子的流向。
这样,FlatMap 就算转换完成了。放入缓存中。
这样对于 transformations 的 一次 for 循环就结束了。
然后开始处理 Keyed Aggregation ,也是一样的流程,先处理它的 input,从最上面一层层往下处理,这里我们就不细说了。

十一、最终结果
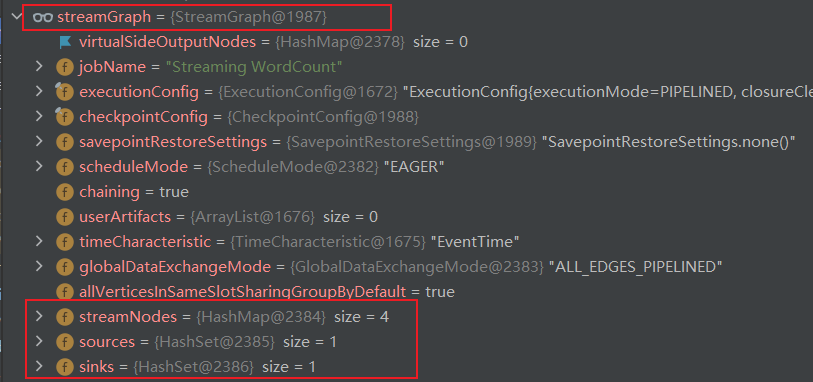
最终生成的 StreamGraph中,重要的就是这个 StreamNodes,一共有四个:

每一个 Node 里面有 InEdge,表示这个节点的上游节点是哪个;有 outEdge,表示这个节点的下游节点是哪个。
还有 sources 表示是源,sinks 表示是目标。
十二、小结
好了,本次的 StreamGraph 的 debug 就到这了。
阅读这部分的代码,给我感触最深的就是,要关注主要矛盾,忽略次要分支,才能把脉络梳理清楚,否则就会深陷泥潭,不仅自己没有成就感,而且还耽误了时间。
当然,生成 StreamGraph 的过程中,还有诸多细节,这里我不打算再深究了,如果日后有什么需要,再来看这块其他的代码。
下一次,就是具体的提交任务的过程了,这个过程需要涉及到 Java 的异步编程,所以再安排一次阅读源码必备知识之 Java 异步编程,拭目以待!
更多源码解析,关注公众号【kkbigdata】
