目录
Graph总览
不同的Flink API、不同层次Graph的对应关系如下图所示

1.流计算应用中的Graph转换
对于流计算应用来说,首先要将DataStream API的调用转换为Transformation,然后经过StreamGraph->JobGraph->ExecutionGraph 3层转换(Flink内置的数据结构),最后经过Flink的调度执行,在Flink集群中启动计算任务,形成一个物理执行图,该图是物理执行的Task之间的拓扑关系,但是在Flink中没有对应的Graph数据结构,是运行时的概念。
2.批处理应用的Graph转换
对于批处理应用而言,首先将DataSet API转换成OptimizedPlan,然后转换为JobGraph。批处理和流计算在JobGraph上完成了统一。
3.Table & SQL API 的Graph转换
Table & SQL API是高阶API,在开发时并不区分到底是批处理还是流计算,语法上二者基本上没有区别。目前DataStream API能统一编写批处理计算任务和流处理任务。在Table & SQL 模块使用了新的Blink Table Planner和旧的Flink Table Planner。Flink Table Planner未来会逐渐废弃,最终从Flink移除。
在Blink Table Planner中,批处理和流计算都依赖于流计算体系,所以无论是批处理还是流计算应用的Graph转换过程都是一样的。在旧的Flink Table Planner中,流计算依赖于DataStream API,其Graph转换过程就是流计算应用的Graph转换过程,批处理依赖于DataSet API,所以其转换过程就是批处理应用的Graph转换过程。
未来DataSet API会被废弃,最终从Flink中一处,所以其Graph转换过程将不复存在,下面以流计算的转换过程为例
流图
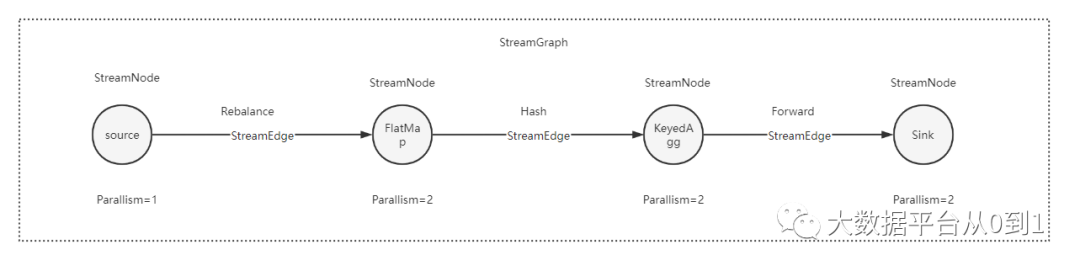
由上图可以看到,StreamGraph由StreamNode和StreamEdge构成
1.StreamNode
StreamNode是StreamGraph中的节点,从Transformation转换而来,可以理解为一个StreamNode表示一个算子,从逻辑上来说,StreamNode在StreamGraph中存在实体和虚拟的StreamNode。StreamNode可以有多个输入,也可以有多个输出。
2.StreamEdge
StreamEdge是StreamGraph中的边,用来连接两个StreamNode,一个StreamNode可以有多个出边、入边。StreamEdge中包含了旁路输出、分区器、字段筛选输出(与SQL Select中选择字段的逻辑一样)等信息。
3.StreamGraph生成源码解析
生成StreamGraph的入口在StreamExecutionEnvironment中
public JobExecutionResult execute(String jobName) throws Exception {
Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");
return execute(getStreamGraph(jobName));
}进入到getStreamGraph()方法中
@Internal
public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) {
StreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate();
if (clearTransformations) {
this.transformations.clear();
}
return streamGraph;
}StreamGraph在StreamGraphGenerator中生成,从SinkTransformation(输出)向前追溯到SourceTransformation。在遍历过程中一边遍历一边构建StreamGraph
进入到generate()方法中
public StreamGraph generate() {
streamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);
...
//实际StreamGraph的生成
for (Transformation<?> transformation : transformations) {
transform(transformation);
}
...
final StreamGraph builtStreamGraph = streamGraph;
...
return builtStreamGraph;
}进入到transform(transformation)方法中,会根据translator是否存在进入不同的translate方法
if (translator != null) {
transformedIds = translate(translator, transform);
} else {
transformedIds = legacyTransform(transform);
}进入到translate(translator,transform)方法中,根据是Batch和Streaming调不同的方法
return shouldExecuteInBatchMode
? translator.translateForBatch(transform, context)
: translator.translateForStreaming(transform, context);进入到translateForStreaming(transform,context),根据不同Transformation进入到不同的translateForStreaming(transform,context)方法
这里分析OneInputTransformation.java,最终调用AbstractOneInputTransformationTranslator中的translateInternal()构建StreamGraph
-
首先添加算子到StreamGraph中
streamGraph.addOperator(
transformationId,
slotSharingGroup,
transformation.getCoLocationGroupKey(),
operatorFactory,
inputType,
transformation.getOutputType(),
transformation.getName());-
设置StateKeySelector
if (stateKeySelector != null) {
TypeSerializer<?> keySerializer = stateKeyType.createSerializer(executionConfig);
streamGraph.setOneInputStateKey(transformationId, stateKeySelector, keySerializer);
}- 设置并行度和、最大并行度
streamGraph.setParallelism(transformationId, parallelism);
streamGraph.setMaxParallelism(transformationId, transformation.getMaxParallelism());-
构造StreamEdge的边,关联上下游StreamNode
for (Integer inputId : context.getStreamNodeIds(parentTransformations.get(0))) {
streamGraph.addEdge(inputId, transformationId, 0);
}在PartitionTransformationTranslator.java中的translateInternal()方法中
private Collection<Integer> translateInternal(
final PartitionTransformation<OUT> transformation, final Context context) {
...
final StreamGraph streamGraph = context.getStreamGraph();
...
List<Integer> resultIds = new ArrayList<>();
for (Integer inputId : context.getStreamNodeIds(input)) {
final int virtualId = Transformation.getNewNodeId();
//todo 添加一个虚拟分区节点,不会生成StreamNode
streamGraph.addVirtualPartitionNode(
inputId,
virtualId,
transformation.getPartitioner(),
transformation.getShuffleMode());
resultIds.add(virtualId);
}
return resultIds;
}从上边代码可以看到,对PartitionTransformation的抓换没有生成具体的StreamNode和StreamEdge,而是通过streamGraph.addVirtualPartitionNode()方法添加一个虚拟节点。当数据分区的下游Tramsformation添加StreamEdge时(调用 streamGraph.addEdge()),会把Partitioner分区器封装到StreamEdge中,如下代码所示
private void addEdgeInternal(
Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
List<String> outputNames,
OutputTag outputTag,
ShuffleMode shuffleMode) {
//todo 如果上游是sideOutput时,递归调用,并传入sideOutput 信息
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;
if (outputTag == null) {
outputTag = virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(
upStreamVertexID,
downStreamVertexID,
typeNumber,
partitioner,
null,
outputTag,
shuffleMode);
//todo 如果上游是Partition时,递归调用,并传入Partition信息
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
shuffleMode = virtualPartitionNodes.get(virtualId).f2;
addEdgeInternal(
upStreamVertexID,
downStreamVertexID,
typeNumber,
partitioner,
outputNames,
outputTag,
shuffleMode);
} else {
//todo 不是以上逻辑,构建真正的StreamEdge
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
//todo 没有指定Partition时,会为其选择forwa或者rebalance分区
if (partitioner == null
&& upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
...
if (shuffleMode == null) {
shuffleMode = ShuffleMode.UNDEFINED;
}
//todo 创建StreamEdge,并将该StreamEdge
StreamEdge edge =
new StreamEdge(
upstreamNode,
downstreamNode,
typeNumber,
partitioner,
outputTag,
shuffleMode);
//todo 创建StreamEdge,并将StreamEdge添加到上游的输出、下游的输入
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}
}
关注公众账号,学习更多Flink内容
