说明TensorFlow的数据流图结构
应用TensorFlow操作图
说明会话在TensorFlow程序中的作用
应用TensorFlow实现张量的创建、形状类型修改操作
应用Variable实现变量op的创建
应用Tensorboard实现图结构以及张量值的显示
应用tf.train.saver实现TensorFlow的模型保存以及加载
应用tf.app.flags实现命令行参数添加和使用
应用TensorFlow实现线性回归2.1 TF数据流图
学习目标
- 目标
- 说明TensorFlow的数据流图结构
- 应用
- 无
- 内容预览
- 2.1.1 案例:TensorFlow实现一个加法运算
- 1 代码
- 2 TensorFlow结构分析
- 2.1.2 数据流图介绍
- 2.1.1 案例:TensorFlow实现一个加法运算
2.1.1 案例:TensorFlow实现一个加法运算
2.1.1.1 代码
def tensorflow_demo():
"""
通过简单案例来了解tensorflow的基础结构
:return: None
"""
# 一、原生python实现加法运算
a = 10
b = 20
c = a + b
print("原生Python实现加法运算方法1:\n", c)
def add(a, b):
return a + b
sum = add(a, b)
print("原生python实现加法运算方法2:\n", sum)
# 二、tensorflow实现加法运算
a_t = tf.constant(10)
b_t = tf.constant(20)
# 不提倡直接运用这种符号运算符进行计算
# 更常用tensorflow提供的函数进行计算
# c_t = a_t + b_t
c_t = tf.add(a_t, b_t)
print("tensorflow实现加法运算:\n", c_t)
# 如何让计算结果出现?
# 开启会话
with tf.Session() as sess:
sum_t = sess.run(c_t)
print("在sess当中的sum_t:\n", sum_t)
return None
注意问题:警告指出你的CPU支持AVX运算加速了线性代数计算,即点积,矩阵乘法,卷积等。可以从源代码安装TensorFlow来编译,当然也可以选择关闭
import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
2.1.1.2 TensorFlow结构分析
TensorFlow 程序通常被组织成一个构建图阶段和一个执行图阶段。
在构建阶段,数据与操作的执行步骤被描述成一个图。
在执行阶段,使用会话执行构建好的图中的操作。
- 图和会话 :
- 图:这是 TensorFlow 将计算表示为指令之间的依赖关系的一种表示法
- 会话:TensorFlow 跨一个或多个本地或远程设备运行数据流图的机制
- 张量:TensorFlow 中的基本数据对象
- 节点:提供图当中执行的操作
2.1.2 数据流图介绍

TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源框架。
节点(Operation)在图中表示数学操作,线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。
2.2 图与TensorBoard
学习目标
- 目标
- 说明图的基本使用
- 应用tf.Graph创建图、tf.get_default_graph获取默认图
- 知道开启TensorBoard过程
- 知道图当中op的名字以及命名空间
- 应用
- 无
- 内容预览
- 2.2.1 什么是图结构
- 2.2.2 图相关操作
- 1 默认图
- 2 创建图
- 2.2.3 TensorBoard:可视化学习
- 1 数据序列化-events文件
- 2 启动TensorBoard
- 2.2.4 OP
- 1 常见OP
- 2 指令名称
2.2.1 什么是图结构
图包含了一组tf.Operation代表的计算单元对象和tf.Tensor代表的计算单元之间流动的数据。
2.2.2 图相关操作
1 默认图
通常TensorFlow会默认帮我们创建一张图。
查看默认图的两种方法:
- 通过调用tf.get_default_graph()访问 ,要将操作添加到默认图形中,直接创建OP即可。
- op、sess都含有graph属性 ,默认都在一张图中
def graph_demo():
# 图的演示
a_t = tf.constant(10)
b_t = tf.constant(20)
# 不提倡直接运用这种符号运算符进行计算
# 更常用tensorflow提供的函数进行计算
# c_t = a_t + b_t
c_t = tf.add(a_t, b_t)
print("tensorflow实现加法运算:\n", c_t)
# 获取默认图
default_g = tf.get_default_graph()
print("获取默认图:\n", default_g)
# 数据的图属性
print("a_t的graph:\n", a_t.graph)
print("b_t的graph:\n", b_t.graph)
# 操作的图属性
print("c_t的graph:\n", c_t.graph)
# 开启会话
with tf.Session() as sess:
sum_t = sess.run(c_t)
print("在sess当中的sum_t:\n", sum_t)
# 会话的图属性
print("会话的图属性:\n", sess.graph)
return None
2 创建图
-
可以通过tf.Graph()自定义创建图
-
如果要在这张图中创建OP,典型用法是使用tf.Graph.as_default()上下文管理器
def graph_demo():
# 图的演示
a_t = tf.constant(10)
b_t = tf.constant(20)
# 不提倡直接运用这种符号运算符进行计算
# 更常用tensorflow提供的函数进行计算
# c_t = a_t + b_t
c_t = tf.add(a_t, b_t)
print("tensorflow实现加法运算:\n", c_t)
# 获取默认图
default_g = tf.get_default_graph()
print("获取默认图:\n", default_g)
# 数据的图属性
print("a_t的graph:\n", a_t.graph)
print("b_t的graph:\n", b_t.graph)
# 操作的图属性
print("c_t的graph:\n", c_t.graph)
# 自定义图
new_g = tf.Graph()
print("自定义图:\n", new_g)
# 在自定义图中去定义数据和操作
with new_g.as_default():
new_a = tf.constant(30)
new_b = tf.constant(40)
new_c = tf.add(new_a, new_b)
# 数据的图属性
print("new_a的graph:\n", new_a.graph)
print("new_b的graph:\n", new_b.graph)
# 操作的图属性
print("new_c的graph:\n", new_c.graph)
# 开启会话
with tf.Session() as sess:
sum_t = sess.run(c_t)
print("在sess当中的sum_t:\n", sum_t)
# 会话的图属性
print("会话的图属性:\n", sess.graph)
# 不同的图之间不能互相访问
# sum_new = sess.run(new_c)
# print("在sess当中的sum_new:\n", sum_new)
with tf.Session(graph=new_g) as sess2:
sum_new = sess2.run(new_c)
print("在sess2当中的sum_new:\n", sum_new)
print("会话的图属性:\n", sess2.graph)
# 很少会同时开启不同的图,一般用默认的图就够了
return None
TensorFlow有一个亮点就是,我们能看到自己写的程序的可视化效果,这个功能就是Tensorboard。在这里我们先简单介绍一下其基本功能。
2.2.3 TensorBoard:可视化学习
TensorFlow 可用于训练大规模深度神经网络所需的计算,使用该工具涉及的计算往往复杂而深奥。为了更方便 TensorFlow 程序的理解、调试与优化,TensorFlow提供了TensorBoard 可视化工具。

实现程序可视化过程:
1 数据序列化-events文件
TensorBoard 通过读取 TensorFlow 的事件文件来运行,需要将数据生成一个序列化的 Summary protobuf 对象。
# 返回filewriter,写入事件文件到指定目录(最好用绝对路径),以提供给tensorboard使用
tf.summary.FileWriter('./tmp/summary/test/', graph=sess.graph)
这将在指定目录中生成一个 event 文件,其名称格式如下:
events.out.tfevents.{timestamp}.{hostname}
2 启动TensorBoard
tensorboard --logdir="./tmp/tensorflow/summary/test/"
在浏览器中打开 TensorBoard 的图页面 127.0.0.1:6006 ,会看到与以下图形类似的图,在GRAPHS模块我们可以看到以下图结构
2.2.4 OP
2.2.4.1 常见OP
哪些是OP?
| 类型 | 实例 |
|---|---|
| 标量运算 | add, sub, mul, div, exp, log, greater, less, equal |
| 向量运算 | concat, slice, splot, constant, rank, shape, shuffle |
| 矩阵运算 | matmul, matrixinverse, matrixdateminant |
| 带状态的运算 | Variable, assgin, assginadd |
| 神经网络组件 | softmax, sigmoid, relu,convolution,max_pool |
| 存储, 恢复 | Save, Restroe |
| 队列及同步运算 | Enqueue, Dequeue, MutexAcquire, MutexRelease |
| 控制流 | Merge, Switch, Enter, Leave, NextIteration |
一个操作对象(Operation)是TensorFlow图中的一个节点, 可以接收0个或者多个输入Tensor, 并且可以输出0个或者多个Tensor,Operation对象是通过op构造函数(如tf.matmul())创建的。
例如: c = tf.matmul(a, b) 创建了一个Operation对象,类型为 MatMul类型, 它将张量a, b作为输入,c作为输出,,并且输出数据,打印的时候也是打印的数据。其中tf.matmul()是函数,在执行matmul函数的过程中会通过MatMul类创建一个与之对应的对象
# 实现一个加法运算
con_a = tf.constant(3.0)
con_b = tf.constant(4.0)
sum_c = tf.add(con_a, con_b)
print("打印con_a:\n", con_a)
print("打印con_b:\n", con_b)
print("打印sum_c:\n", sum_c)
打印语句会生成:
打印con_a:
Tensor("Const:0", shape=(), dtype=float32)
打印con_b:
Tensor("Const_1:0", shape=(), dtype=float32)
打印sum_c:
Tensor("Add:0", shape=(), dtype=float32)
注意,打印出来的是张量值,可以理解成OP当中包含了这个值。并且每一个OP指令都对应一个唯一的名称,如上面的Const:0,这个在TensorBoard上面也可以显示
请注意,tf.Tensor 对象以输出该张量的 tf.Operation 明确命名。张量名称的形式为 "<OP_NAME>:<i>",其中:
- "<OP_NAME>" 是生成该张量的指令的名称
- "<i>" 是一个整数,它表示该张量在指令的输出中的索引
2.2.4.2 指令名称
tf.Graph对象为其包含的 tf.Operation对象定义的一个命名空间。TensorFlow 会自动为图中的每个指令选择一个唯一名称,用户也可以指定描述性名称,使程序阅读起来更轻松。我们可以以以下方式改写指令名称
- 每个创建新的 tf.Operation 或返回新的 tf.Tensor 的 API 函数可以接受可选的 name 参数。
例如,tf.constant(42.0, name="answer") 创建了一个名为 "answer" 的新 tf.Operation 并返回一个名为 "answer:0" 的 tf.Tensor。如果默认图已包含名为 "answer" 的指令,则 TensorFlow 会在名称上附加 "1"、"2" 等字符,以便让名称具有唯一性。
- 当修改好之后,我们在Tensorboard显示的名字也会被修改
a = tf.constant(3.0, name="a")
b = tf.constant(4.0, name="b" )
2.3 会话
学习目标
- 目标
- 应用sess.run或者eval运行图程序并获取张量值
- 应用feed_dict机制实现运行时填充数据
- 应用placeholder实现创建占位符
- 应用
- 无
- 内容预览
- 2.3.1 会话
- 1 __init__(target='', graph=None, config=None)
- 2 会话的run()
- 3 feed操作
- 2.3.1 会话
2.3.1 会话
一个运行TensorFlow operation的类。会话包含以下两种开启方式
- tf.Session:用于完整的程序当中
- tf.InteractiveSession:用于交互式上下文中的TensorFlow ,例如shell
1 TensorFlow 使用 tf.Session 类来表示客户端程序(通常为 Python 程序,但也提供了使用其他语言的类似接口)与 C++ 运行时之间的连接
2 tf.Session 对象使用分布式 TensorFlow 运行时提供对本地计算机中的设备和远程设备的访问权限。
2.3.1.1 __init__(target='', graph=None, config=None)
会话可能拥有的资源,如 tf.Variable,tf.QueueBase和tf.ReaderBase。当这些资源不再需要时,释放这些资源非常重要。因此,需要调用tf.Session.close会话中的方法,或将会话用作上下文管理器。以下两个例子作用是一样的:
def session_demo():
"""
会话演示
:return:
"""
a_t = tf.constant(10)
b_t = tf.constant(20)
# 不提倡直接运用这种符号运算符进行计算
# 更常用tensorflow提供的函数进行计算
# c_t = a_t + b_t
c_t = tf.add(a_t, b_t)
print("tensorflow实现加法运算:\n", c_t)
# 开启会话
# 传统的会话定义
# sess = tf.Session()
# sum_t = sess.run(c_t)
# print("sum_t:\n", sum_t)
# sess.close()
# 开启会话
with tf.Session() as sess:
# sum_t = sess.run(c_t)
# 想同时执行多个tensor
print(sess.run([a_t, b_t, c_t]))
# 方便获取张量值的方法
# print("在sess当中的sum_t:\n", c_t.eval())
# 会话的图属性
print("会话的图属性:\n", sess.graph)
return None
- target:如果将此参数留空(默认设置),会话将仅使用本地计算机中的设备。可以指定 grpc:// 网址,以便指定 TensorFlow 服务器的地址,这使得会话可以访问该服务器控制的计算机上的所有设备。
- graph:默认情况下,新的 tf.Session 将绑定到当前的默认图。
- config:此参数允许您指定一个 tf.ConfigProto 以便控制会话的行为。例如,ConfigProto协议用于打印设备使用信息
# 运行会话并打印设备信息
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,
log_device_placement=True))
会话可以分配不同的资源在不同的设备上运行。
/job:worker/replica:0/task:0/device:CPU:0
device_type:类型设备(例如CPU,GPU,TPU)
2.3.1.2 会话的run()
- run(fetches,feed_dict=None, options=None, run_metadata=None)
- 通过使用sess.run()来运行operation
- fetches:单一的operation,或者列表、元组(其它不属于tensorflow的类型不行)
- feed_dict:参数允许调用者覆盖图中张量的值,运行时赋值
- 与tf.placeholder搭配使用,则会检查值的形状是否与占位符兼容。
使用tf.operation.eval()也可运行operation,但需要在会话中运行
# 创建图
a = tf.constant(5.0)
b = tf.constant(6.0)
c = a * b
# 创建会话
sess = tf.Session()
# 计算C的值
print(sess.run(c))
print(c.eval(session=sess))
2.3.1.3 feed操作
- placeholder提供占位符,run时候通过feed_dict指定参数
def session_run_demo():
"""
会话的run方法
:return:
"""
# 定义占位符
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
sum_ab = tf.add(a, b)
print("sum_ab:\n", sum_ab)
# 开启会话
with tf.Session() as sess:
print("占位符的结果:\n", sess.run(sum_ab, feed_dict={a: 3.0, b: 4.0}))
return None
请注意运行时候报的错误error:
RuntimeError:如果这Session是无效状态(例如已关闭)。 TypeError:如果fetches或者feed_dict键的类型不合适。 ValueError:如果fetches或feed_dict键无效或引用 Tensor不存在的键。
2.4 张量
学习目标
- 目标
- 知道常见的TensorFlow创建张量
- 知道常见的张量数学运算操作
- 说明numpy的数组和张量相同性
- 说明张量的两种形状改变特点
- 应用set_shape和tf.reshape实现张量形状的修改
- 应用tf.matmul实现张量的矩阵运算修改
- 应用tf.cast实现张量的类型
- 应用
- 无
- 内容预览
- 2.4.1 张量(Tensor)
- 1 张量的类型
- 2 张量的阶
- 2.4.2 创建张量的指令
- 固定值张量
- 随机值张量
- 2.4.3 张量的变换
- 1 类型改变
- 2 形状改变
- 2.4.4 张量的数学运算
- 2.4.1 张量(Tensor)
在编写 TensorFlow 程序时,程序传递和运算的主要目标是tf.Tensor
2.4.1 张量(Tensor)
TensorFlow 的张量就是一个 n 维数组, 类型为tf.Tensor。Tensor具有以下两个重要的属性
- type:数据类型
- shape:形状(阶)
2.4.1.1 张量的类型

2.4.1.2 张量的阶

形状有0阶、1阶、2阶….
tensor1 = tf.constant(4.0)
tensor2 = tf.constant([1, 2, 3, 4])
linear_squares = tf.constant([[4], [9], [16], [25]], dtype=tf.int32)
print(tensor1.shape)
# 0维:() 1维:(10, ) 2维:(3, 4) 3维:(3, 4, 5)
2.4.2 创建张量的指令
- 固定值张量

- 随机值张量

- 其它特殊的创建张量的op
- tf.Variable
- tf.placeholder
2.4.3 张量的变换
1 类型改变

2 形状改变
TensorFlow的张量具有两种形状变换,动态形状和静态形状
- tf.reshape
- tf.set_shape
关于动态形状和静态形状必须符合以下规则
- 静态形状
- 转换静态形状的时候,1-D到1-D,2-D到2-D,不能跨阶数改变形状
- 对于已经固定的张量的静态形状的张量,不能再次设置静态形状
- 动态形状
- tf.reshape()动态创建新张量时,张量的元素个数必须匹配
def tensor_demo():
"""
张量的介绍
:return:
"""
a = tf.constant(value=30.0, dtype=tf.float32, name="a")
b = tf.constant([[1, 2], [3, 4]], dtype=tf.int32, name="b")
a2 = tf.constant(value=30.0, dtype=tf.float32, name="a2")
c = tf.placeholder(dtype=tf.float32, shape=[2, 3, 4], name="c")
sum = tf.add(a, a2, name="my_add")
print(a, a2, b, c)
print(sum)
# 获取张量属性
print("a的图属性:\n", a.graph)
print("b的名字:\n", b.name)
print("a2的形状:\n", a2.shape)
print("c的数据类型:\n", c.dtype)
print("sum的op:\n", sum.op)
# 获取静态形状
print("b的静态形状:\n", b.get_shape())
# 定义占位符
a_p = tf.placeholder(dtype=tf.float32, shape=[None, None])
b_p = tf.placeholder(dtype=tf.float32, shape=[None, 10])
c_p = tf.placeholder(dtype=tf.float32, shape=[3, 2])
# 获取静态形状
print("a_p的静态形状为:\n", a_p.get_shape())
print("b_p的静态形状为:\n", b_p.get_shape())
print("c_p的静态形状为:\n", c_p.get_shape())
# 形状更新
# a_p.set_shape([2, 3])
# 静态形状已经固定部分就不能修改了
# b_p.set_shape([10, 3])
# c_p.set_shape([2, 3])
# 静态形状已经固定的部分包括它的阶数,如果阶数固定了,就不能跨阶更新形状
# 如果想要跨阶改变形状,就要用动态形状
# a_p.set_shape([1, 2, 3])
# 获取静态形状
print("a_p的静态形状为:\n", a_p.get_shape())
print("b_p的静态形状为:\n", b_p.get_shape())
print("c_p的静态形状为:\n", c_p.get_shape())
# 动态形状
# c_p_r = tf.reshape(c_p, [1, 2, 3])
c_p_r = tf.reshape(c_p, [2, 3])
# 动态形状,改变的时候,不能改变元素的总个数
# c_p_r2 = tf.reshape(c_p, [3, 1])
print("动态形状的结果:\n", c_p_r)
# print("动态形状的结果2:\n", c_p_r2)
return None
2.4.4 张量的数学运算
- 算术运算符
- 基本数学函数
- 矩阵运算
- reduce操作
- 序列索引操作
详细请参考: https://www.tensorflow.org/versions/r1.8/api_guides/python/math_ops
这些API使用,我们在使用的时候介绍,具体参考文档
2.5 变量OP
- 目标
- 说明变量op的特殊作用
- 说明变量op的trainable参数的作用
- 应用global_variables_initializer实现变量op的初始化
- 应用
- 无
- 内容预览
- 2.5.1 创建变量
- 2.5.2 使用tf.variable_scope()修改变量的命名空间
TensorFlow变量是表示程序处理的共享持久状态的最佳方法。变量通过 tf.Variable OP类进行操作。变量的特点:
- 存储持久化
- 可修改值
- 可指定被训练
2.5.1 创建变量
-
tf.Variable(initial_value=None,trainable=True,collections=None,name=None)
- initial_value:初始化的值
- trainable:是否被训练
- collections:新变量将添加到列出的图的集合中collections,默认为[GraphKeys.GLOBAL_VARIABLES],如果trainable是True变量也被添加到图形集合 GraphKeys.TRAINABLE_VARIABLES
-
变量需要显式初始化,才能运行值
def variable_demo():
"""
变量的演示
:return:
"""
# 定义变量
a = tf.Variable(initial_value=30)
b = tf.Variable(initial_value=40)
sum = tf.add(a, b)
# 初始化变量
init = tf.global_variables_initializer()
# 开启会话
with tf.Session() as sess:
# 变量初始化
sess.run(init)
print("sum:\n", sess.run(sum))
return None
2.5.2 使用tf.variable_scope()修改变量的命名空间
会在OP的名字前面增加命名空间的指定名字
with tf.variable_scope("name"):
var = tf.Variable(name='var', initial_value=[4], dtype=tf.float32)
var_double = tf.Variable(name='var', initial_value=[4], dtype=tf.float32)
<tf.Variable 'name/var:0' shape=() dtype=float32_ref>
<tf.Variable 'name/var_1:0' shape=() dtype=float32_ref>2.7 案例:实现线性回归
学习目标
- 目标
- 应用op的name参数实现op的名字修改
- 应用variable_scope实现图程序作用域的添加
- 应用scalar或histogram实现张量值的跟踪显示
- 应用merge_all实现张量值的合并
- 应用add_summary实现张量值写入文件
- 应用tf.train.saver实现TensorFlow的模型保存以及加载
- 应用tf.app.flags实现命令行参数添加和使用
- 应用reduce_mean、square实现均方误差计算
- 应用tf.train.GradientDescentOptimizer实现有梯度下降优化器创建
- 应用minimize函数优化损失
- 知道梯度爆炸以及常见解决技巧
- 应用
- 实现线性回归模型
- 内容预览
- 2.7.1 线性回归原理复习
- 2.7.2 案例:实现线性回归的训练
- 2.7.3 增加其他功能
- 1 增加变量显示
- 2 增加命名空间
- 3 模型的保存与加载
- 4 命令行参数使用
2.7.1 线性回归原理复习
根据数据建立回归模型,w1x1+w2x2+…..+b = y,通过真实值与预测值之间建立误差,使用梯度下降优化得到损失最小对应的权重和偏置。最终确定模型的权重和偏置参数。最后可以用这些参数进行预测。
2.7.2 案例:实现线性回归的训练
1 案例确定
- 假设随机指定100个点,只有一个特征
- 数据本身的分布为 y = 0.8 * x + 0.7
这里将数据分布的规律确定,是为了使我们训练出的参数跟真实的参数(即0.8和0.7)比较是否训练准确
2 API
运算
- 矩阵运算
- tf.matmul(x, w)
- 平方
- tf.square(error)
- 均值
- tf.reduce_mean(error)
梯度下降优化
- tf.train.GradientDescentOptimizer(learning_rate)
- 梯度下降优化
- learning_rate:学习率,一般为0~1之间比较小的值
- method:
- minimize(loss)
- return:梯度下降op
3 步骤分析
- 1 准备好数据集:y = 0.8x + 0.7 100个样本
- 2 建立线性模型
- 随机初始化W1和b1
- y = W·X + b,目标:求出权重W和偏置b
- 3 确定损失函数(预测值与真实值之间的误差)-均方误差
- 4 梯度下降优化损失:需要指定学习率(超参数)
4 实现完整功能
import tensorflow as tf
import os
def linear_regression():
"""
自实现线性回归
:return: None
"""
# 1)准备好数据集:y = 0.8x + 0.7 100个样本
# 特征值X, 目标值y_true
X = tf.random_normal(shape=(100, 1), mean=2, stddev=2)
# y_true [100, 1]
# 矩阵运算 X(100, 1)* (1, 1)= y_true(100, 1)
y_true = tf.matmul(X, [[0.8]]) + 0.7
# 2)建立线性模型:
# y = W·X + b,目标:求出权重W和偏置b
# 3)随机初始化W1和b1
weights = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)))
bias = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)))
y_predict = tf.matmul(X, weights) + bias
# 4)确定损失函数(预测值与真实值之间的误差)-均方误差
error = tf.reduce_mean(tf.square(y_predict - y_true))
# 5)梯度下降优化损失:需要指定学习率(超参数)
# W2 = W1 - 学习率*(方向)
# b2 = b1 - 学习率*(方向)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error)
# 初始化变量
init = tf.global_variables_initializer()
# 开启会话进行训练
with tf.Session() as sess:
# 运行初始化变量Op
sess.run(init)
print("随机初始化的权重为%f, 偏置为%f" % (weights.eval(), bias.eval()))
# 训练模型
for i in range(100):
sess.run(optimizer)
print("第%d步的误差为%f,权重为%f, 偏置为%f" % (i, error.eval(), weights.eval(), bias.eval()))
return None
6 变量的trainable设置观察
trainable的参数作用,指定是否训练
weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0), name="weights", trainable=False)
2.7.3 增加其他功能
- 增加命名空间
- 命令行参数设置
2 增加命名空间
是代码结构更加清晰,Tensorboard图结构清楚
with tf.variable_scope("lr_model"):
def linear_regression():
# 1)准备好数据集:y = 0.8x + 0.7 100个样本
# 特征值X, 目标值y_true
with tf.variable_scope("original_data"):
X = tf.random_normal(shape=(100, 1), mean=2, stddev=2, name="original_data_x")
# y_true [100, 1]
# 矩阵运算 X(100, 1)* (1, 1)= y_true(100, 1)
y_true = tf.matmul(X, [[0.8]], name="original_matmul") + 0.7
# 2)建立线性模型:
# y = W·X + b,目标:求出权重W和偏置b
# 3)随机初始化W1和b1
with tf.variable_scope("linear_model"):
weights = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)), name="weights")
bias = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)), name="bias")
y_predict = tf.matmul(X, weights, name="model_matmul") + bias
# 4)确定损失函数(预测值与真实值之间的误差)-均方误差
with tf.variable_scope("loss"):
error = tf.reduce_mean(tf.square(y_predict - y_true), name="error_op")
# 5)梯度下降优化损失:需要指定学习率(超参数)
# W2 = W1 - 学习率*(方向)
# b2 = b1 - 学习率*(方向)
with tf.variable_scope("gd_optimizer"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01, name="optimizer").minimize(error)
# 2)收集变量
tf.summary.scalar("error", error)
tf.summary.histogram("weights", weights)
tf.summary.histogram("bias", bias)
# 3)合并变量
merge = tf.summary.merge_all()
# 初始化变量
init = tf.global_variables_initializer()
# 开启会话进行训练
with tf.Session() as sess:
# 运行初始化变量Op
sess.run(init)
print("随机初始化的权重为%f, 偏置为%f" % (weights.eval(), bias.eval()))
# 1)创建事件文件
file_writer = tf.summary.FileWriter(logdir="./summary", graph=sess.graph)
# 训练模型
for i in range(100):
sess.run(optimizer)
print("第%d步的误差为%f,权重为%f, 偏置为%f" % (i, error.eval(), weights.eval(), bias.eval()))
# 4)运行合并变量op
summary = sess.run(merge)
file_writer.add_summary(summary, i)
return None
3 模型的保存与加载
- tf.train.Saver(var_list=None,max_to_keep=5)
- 保存和加载模型(保存文件格式:checkpoint文件)
- var_list:指定将要保存和还原的变量。它可以作为一个dict或一个列表传递.
- max_to_keep:指示要保留的最近检查点文件的最大数量。创建新文件时,会删除较旧的文件。如果无或0,则保留所有检查点文件。默认为5(即保留最新的5个检查点文件。)
使用
例如:
指定目录+模型名字
saver.save(sess, '/tmp/ckpt/test/myregression.ckpt')
saver.restore(sess, '/tmp/ckpt/test/myregression.ckpt')
如要判断模型是否存在,直接指定目录
checkpoint = tf.train.latest_checkpoint("./tmp/model/")
saver.restore(sess, checkpoint)4 命令行参数使用

-
2、 tf.app.flags.,在flags有一个FLAGS标志,它在程序中可以调用到我们
前面具体定义的flag_name
- 3、通过tf.app.run()启动main(argv)函数
# 定义一些常用的命令行参数
# 训练步数
tf.app.flags.DEFINE_integer("max_step", 0, "训练模型的步数")
# 定义模型的路径
tf.app.flags.DEFINE_string("model_dir", " ", "模型保存的路径+模型名字")
# 定义获取命令行参数
FLAGS = tf.app.flags.FLAGS
# 开启训练
# 训练的步数(依据模型大小而定)
for i in range(FLAGS.max_step):
sess.run(train_op)
完整代码
import tensorflow as tf
import os
tf.app.flags.DEFINE_string("model_path", "./linear_regression/", "模型保存的路径和文件名")
FLAGS = tf.app.flags.FLAGS
def linear_regression():
# 1)准备好数据集:y = 0.8x + 0.7 100个样本
# 特征值X, 目标值y_true
with tf.variable_scope("original_data"):
X = tf.random_normal(shape=(100, 1), mean=2, stddev=2, name="original_data_x")
# y_true [100, 1]
# 矩阵运算 X(100, 1)* (1, 1)= y_true(100, 1)
y_true = tf.matmul(X, [[0.8]], name="original_matmul") + 0.7
# 2)建立线性模型:
# y = W·X + b,目标:求出权重W和偏置b
# 3)随机初始化W1和b1
with tf.variable_scope("linear_model"):
weights = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)), name="weights")
bias = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)), name="bias")
y_predict = tf.matmul(X, weights, name="model_matmul") + bias
# 4)确定损失函数(预测值与真实值之间的误差)-均方误差
with tf.variable_scope("loss"):
error = tf.reduce_mean(tf.square(y_predict - y_true), name="error_op")
# 5)梯度下降优化损失:需要指定学习率(超参数)
# W2 = W1 - 学习率*(方向)
# b2 = b1 - 学习率*(方向)
with tf.variable_scope("gd_optimizer"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01, name="optimizer").minimize(error)
# 2)收集变量
tf.summary.scalar("error", error)
tf.summary.histogram("weights", weights)
tf.summary.histogram("bias", bias)
# 3)合并变量
merge = tf.summary.merge_all()
# 初始化变量
init = tf.global_variables_initializer()
# 开启会话进行训练
with tf.Session() as sess:
# 运行初始化变量Op
sess.run(init)
# 未经训练的权重和偏置
print("随机初始化的权重为%f, 偏置为%f" % (weights.eval(), bias.eval()))
# 当存在checkpoint文件,就加载模型
# 1)创建事件文件
file_writer = tf.summary.FileWriter(logdir="./summary", graph=sess.graph)
# 训练模型
for i in range(100):
sess.run(optimizer)
print("第%d步的误差为%f,权重为%f, 偏置为%f" % (i, error.eval(), weights.eval(), bias.eval()))
# 4)运行合并变量op
summary = sess.run(merge)
file_writer.add_summary(summary, i)
return None
def main(argv):
print("这是main函数")
print(argv)
print(FLAGS.model_path)
linear_regression()
if __name__ == "__main__":
tf.app.run()
作业:将面向过程改为面向对象
参考代码
# 用tensorflow自实现一个线性回归案例
# 定义一些常用的命令行参数
# 训练步数
tf.app.flags.DEFINE_integer("max_step", 0, "训练模型的步数")
# 定义模型的路径
tf.app.flags.DEFINE_string("model_dir", " ", "模型保存的路径+模型名字")
FLAGS = tf.app.flags.FLAGS
class MyLinearRegression(object):
"""
自实现线性回归
"""
def __init__(self):
pass
def inputs(self):
"""
获取特征值目标值数据数据
:return:
"""
x_data = tf.random_normal([100, 1], mean=1.0, stddev=1.0, name="x_data")
y_true = tf.matmul(x_data, [[0.7]]) + 0.8
return x_data, y_true
def inference(self, feature):
"""
根据输入数据建立模型
:param feature:
:param label:
:return:
"""
with tf.variable_scope("linea_model"):
# 2、建立回归模型,分析别人的数据的特征数量--->权重数量, 偏置b
# 由于有梯度下降算法优化,所以一开始给随机的参数,权重和偏置
# 被优化的参数,必须得使用变量op去定义
# 变量初始化权重和偏置
# weight 2维[1, 1] bias [1]
# 变量op当中会有trainable参数决定是否训练
self.weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0),
name="weights")
self.bias = tf.Variable(0.0, name='biases')
# 建立回归公式去得出预测结果
y_predict = tf.matmul(feature, self.weight) + self.bias
return y_predict
def loss(self, y_true, y_predict):
"""
目标值和真实值计算损失
:return: loss
"""
# 3、求出我们模型跟真实数据之间的损失
# 均方误差公式
loss = tf.reduce_mean(tf.square(y_true - y_predict))
return loss
def merge_summary(self, loss):
# 1、收集张量的值
tf.summary.scalar("losses", loss)
tf.summary.histogram("w", self.weight)
tf.summary.histogram('b', self.bias)
# 2、合并变量
merged = tf.summary.merge_all()
return merged
def sgd_op(self, loss):
"""
获取训练OP
:return:
"""
# 4、使用梯度下降优化器优化
# 填充学习率:0 ~ 1 学习率是非常小,
# 学习率大小决定你到达损失一个步数多少
# 最小化损失
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
return train_op
def train(self):
"""
训练模型
:param loss:
:return:
"""
g = tf.get_default_graph()
with g.as_default():
x_data, y_true = self.inputs()
y_predict = self.inference(x_data)
loss = self.loss(y_true, y_predict)
train_op = self.sgd_op(loss)
# 收集观察的结果值
merged = self.merge_summary(loss)
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 在没训练,模型的参数值
print("初始化的权重:%f, 偏置:%f" % (self.weight.eval(), self.bias.eval()))
# 开启训练
# 训练的步数(依据模型大小而定)
for i in range(FLAGS.max_step):
sess.run(train_op)
# 生成事件文件,观察图结构
file_writer = tf.summary.FileWriter("./tmp/summary/", graph=sess.graph)
print("训练第%d步之后的损失:%f, 权重:%f, 偏置:%f" % (
i,
loss.eval(),
self.weight.eval(),
self.bias.eval()))
# 运行收集变量的结果
summary = sess.run(merged)
# 添加到文件
file_writer.add_summary(summary, i)
if __name__ == '__main__':
lr = MyLinearRegression()
lr.train()1.2 神经网络基础
学习目标
- 目标
- 知道逻辑回归的算法计算输出、损失函数
- 知道导数的计算图
- 知道逻辑回归的梯度下降算法
- 知道多样本的向量计算
- 应用
- 应用完成向量化运算
- 应用完成一个单神经元神经网络的结构
1.2.1 Logistic回归
1.2.1.1 Logistic回归




1.2.1.2 逻辑回归损失函数
损失函数(loss function)用于衡量预测结果与真实值之间的误差。最简单的损失函数定义方式为平方差损失:
1.2.2 梯度下降算法
目的:使损失函数的值找到最小值
方式:梯度下降
函数的梯度(gradient)指出了函数的最陡增长方向。梯度的方向走,函数增长得就越快。那么按梯度的负方向走,函数值自然就降低得最快了。模型的训练目标即是寻找合适的 w 与 b 以最小化代价函数值。假设 w 与 b 都是一维实数,那么可以得到如下的 J 关于 w 与 b 的图:


1.2.3 导数
理解梯度下降的过程之后,我们通过例子来说明梯度下降在计算导数意义或者说这个导数的意义。
1.2.3.1 导数
导数也可以理解成某一点处的斜率。斜率这个词更直观一些。
- 各点处的导数值一样



例:取一点为a=2,那么y的值为4,我们稍微增加a的值为a=2.001,那么y的值约等于4.004(4.004001),也就是当a增加了0.001,随后y增加了4倍
取一点为a=5,那么y的值为25,我们稍微增加a的值为a=5.001,那么y的值约等于25.01(25.010001),也就是当a增加了0.001,随后y增加了10倍
可以得出该函数的导数2为2a。
- 更多函数的导数结果
| 函数 | 导数 |
|---|---|
| f(a) = a^2f(a)=a2 | 2a2a |
| f(a)=a^3f(a)=a3 | 3a^23a2 |
| f(a)=ln(a)f(a)=ln(a) | \frac{1}{a}a1 |
| f(a) = e^af(a)=ea | e^aea |
| \sigma(z) = \frac{1}{1+e^{-z}}σ(z)=1+e−z1 | \sigma(z)(1-\sigma(z))σ(z)(1−σ(z)) |
| g(z) = tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}g(z)=tanh(z)=ez+e−zez−e−z | 1-(tanh(z))^2=1-(g(z))^21−(tanh(z))2=1−(g(z))2 |
1.2.3.2 导数计算图
那么接下来我们来看看含有多个变量的到导数流程图,假设J(a,b,c) = 3{(a + bc)}J(a,b,c)=3(a+bc)
我们以下面的流程图代替


1.2.3.3 链式法则

1.2.3.4 逻辑回归的梯度下降
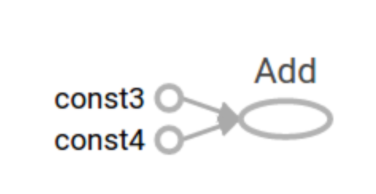
逻辑回归的梯度下降过程计算图,首先从前往后的计算图得出如下
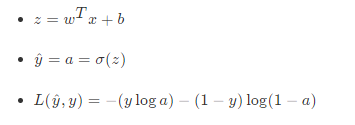
那么计算图从前向过程为,假设样本有两个特征



1.2.4 向量化编程
每更新一次梯度时候,在训练期间我们会拥有m个样本,那么这样每个样本提供进去都可以做一个梯度下降计算。所以我们要去做在所有样本上的计算结果、梯度等操作
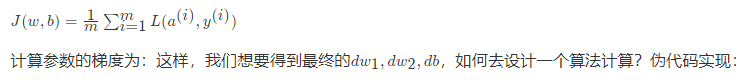



1.2.4.1 向量化优势
什么是向量化
由于在进行计算的时候,最好不要使用for循环去进行计算,因为有Numpy可以进行更加快速的向量化计算。

import numpy as np
import time
a = np.random.rand(100000)
b = np.random.rand(100000)
- 第一种方法
# 第一种for 循环
c = 0
start = time.time()
for i in range(100000):
c += a[i]*b[i]
end = time.time()
print("计算所用时间%s " % str(1000*(end-start)) + "ms")
- 第二种向量化方式使用np.dot
# 向量化运算
start = time.time()
c = np.dot(a, b)
end = time.time()
print("计算所用时间%s " % str(1000*(end-start)) + "ms")
Numpy能够充分的利用并行化,Numpy当中提供了很多函数使用
| 函数 | 作用 |
|---|---|
| np.ones or np.zeros | 全为1或者0的矩阵 |
| np.exp | 指数计算 |
| np.log | 对数计算 |
| np.abs | 绝对值计算 |
所以上述的m个样本的梯度更新过程,就是去除掉for循环。原本这样的计算
1.2.4.2 向量化实现伪代码
- 思路
| z^1 = w^Tx^1+bz1=wTx1+b | z^2 = w^Tx^2+bz2=wTx2+b | z^3 = w^Tx^3+bz3=wTx3+b |
|---|---|---|
| a^1 = \sigma(z^1)a1=σ(z1) | a^2 = \sigma(z^2)a2=σ(z2) | a^3 = \sigma(z^3)a3=σ(z3) |
可以变成这样的计算

注:w的形状为(n,1), x的形状为(n, m),其中n为特征数量,m为样本数量
我们可以让,得出的结果为(1, m)大小的矩阵 注:大写的wx为多个样本表示
- 实现多个样本向量化计算的伪代码


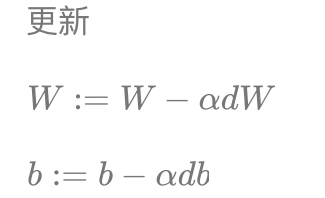
这相当于一次使用了M个样本的所有特征值与目标值,那我们知道如果想多次迭代,使得这M个样本重复若干次计算
1.2.5 案例:实现逻辑回归
1.2.5.1使用数据:制作二分类数据集
from sklearn.datasets import load_iris, make_classification
from sklearn.model_selection import train_test_split
import tensorflow as tf
import numpy as np
X, Y = make_classification(n_samples=500, n_features=5, n_classes=2)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
1.2.5.2 步骤设计:
分别构建算法的不同模块
- 1、初始化参数
def initialize_with_zeros(shape):
"""
创建一个形状为 (shape, 1) 的w参数和b=0.
return:w, b
"""
w = np.zeros((shape, 1))
b = 0
return w, b
- 计算成本函数及其梯度
- w (n,1).T * x (n, m)
- y: (1, n)
def propagate(w, b, X, Y):
"""
参数:w,b,X,Y:网络参数和数据
Return:
损失cost、参数W的梯度dw、参数b的梯度db
"""
m = X.shape[1]
# w (n,1), x (n, m)
A = basic_sigmoid(np.dot(w.T, X) + b)
# 计算损失
cost = -1 / m * np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A))
dz = A - Y
dw = 1 / m * np.dot(X, dz.T)
db = 1 / m * np.sum(dz)
cost = np.squeeze(cost)
grads = {"dw": dw,
"db": db}
return grads, cost
需要一个基础函数sigmoid
def basic_sigmoid(x):
"""
计算sigmoid函数
"""
s = 1 / (1 + np.exp(-x))
return s
- 使用优化算法(梯度下降)
- 实现优化函数. 全局的参数随着w,b对损失J进行优化改变. 对参数进行梯度下降公式计算,指定学习率和步长。
- 循环:
- 计算当前损失
- 计算当前梯度
- 更新参数(梯度下降)
def optimize(w, b, X, Y, num_iterations, learning_rate):
"""
参数:
w:权重,b:偏置,X特征,Y目标值,num_iterations总迭代次数,learning_rate学习率
Returns:
params:更新后的参数字典
grads:梯度
costs:损失结果
"""
costs = []
for i in range(num_iterations):
# 梯度更新计算函数
grads, cost = propagate(w, b, X, Y)
# 取出两个部分参数的梯度
dw = grads['dw']
db = grads['db']
# 按照梯度下降公式去计算
w = w - learning_rate * dw
b = b - learning_rate * db
if i % 100 == 0:
costs.append(cost)
if i % 100 == 0:
print("损失结果 %i: %f" %(i, cost))
print(b)
params = {"w": w,
"b": b}
grads = {"dw": dw,
"db": db}
return params, grads, costs
- 预测函数(不用实现)
利用得出的参数来进行测试得出准确率
def predict(w, b, X):
'''
利用训练好的参数预测
return:预测结果
'''
m = X.shape[1]
y_prediction = np.zeros((1, m))
w = w.reshape(X.shape[0], 1)
# 计算结果
A = basic_sigmoid(np.dot(w.T, X) + b)
for i in range(A.shape[1]):
if A[0, i] <= 0.5:
y_prediction[0, i] = 0
else:
y_prediction[0, i] = 1
return y_prediction
- 整体逻辑
- 模型训练
def model(x_train, y_train, x_test, y_test, num_iterations=2000, learning_rate=0.0001):
"""
"""
# 修改数据形状
x_train = x_train.reshape(-1, x_train.shape[0])
x_test = x_test.reshape(-1, x_test.shape[0])
y_train = y_train.reshape(1, y_train.shape[0])
y_test = y_test.reshape(1, y_test.shape[0])
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)
# 1、初始化参数
w, b = initialize_with_zeros(x_train.shape[0])
# 2、梯度下降
# params:更新后的网络参数
# grads:最后一次梯度
# costs:每次更新的损失列表
params, grads, costs = optimize(w, b, x_train, y_train, num_iterations, learning_rate)
# 获取训练的参数
# 预测结果
w = params['w']
b = params['b']
y_prediction_train = predict(w, b, x_train)
y_prediction_test = predict(w, b, x_test)
# 打印准确率
print("训练集准确率: {} ".format(100 - np.mean(np.abs(y_prediction_train - y_train)) * 100))
print("测试集准确率: {} ".format(100 - np.mean(np.abs(y_prediction_test - y_test)) * 100))
return None
- 训练
model(x_train, y_train, x_test, y_test, num_iterations=2000, learning_rate=0.0001)