版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_31456593/article/details/88915982
Tensorflow 2.0 教程持续更新 :https://blog.csdn.net/qq_31456593/article/details/88606284
完整tensorflow2.0教程代码请看tensorflow2.0:中文教程tensorflow2_tutorials_chinese(欢迎star)
入门教程:
TensorFlow 2.0 教程- Keras 快速入门
TensorFlow 2.0 教程-keras 函数api
TensorFlow 2.0 教程-使用keras训练模型
TensorFlow 2.0 教程-用keras构建自己的网络层
TensorFlow 2.0 教程-keras模型保存和序列化
TensorFlow2教程-mlp及深度学习常见技巧
我们将以mlp对为,基础模型,然后介绍一些深度学习常见技巧, 如:
权重初始化, 激活函数, 优化器, 批规范化, dropout,模型集成
1.导入数据
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape([x_train.shape[0], -1])
x_test = x_test.reshape([x_test.shape[0], -1])
print(x_train.shape, ' ', y_train.shape)
print(x_test.shape, ' ', y_test.shape)
(60000, 784) (60000,)
(10000, 784) (10000,)
2.基础模型
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_11 (Dense) (None, 64) 50240
_________________________________________________________________
dense_12 (Dense) (None, 64) 4160
_________________________________________________________________
dense_13 (Dense) (None, 64) 4160
_________________________________________________________________
dense_14 (Dense) (None, 10) 650
=================================================================
Total params: 59,210
Trainable params: 59,210
Non-trainable params: 0
_________________________________________________________________
history = model.fit(x_train, y_train, batch_size=256, epochs=100, validation_split=0.3, verbose=0)
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()
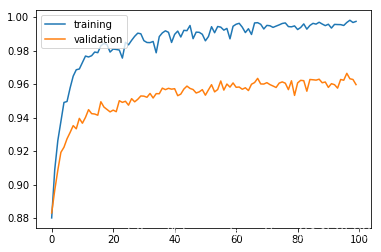
result = model.evaluate(x_test, y_test)
10000/10000 [==============================] - 0s 25us/sample - loss: 0.4429 - accuracy: 0.9632
3.权重初始化
model = keras.Sequential([
layers.Dense(64, activation='relu', kernel_initializer='he_normal', input_shape=(784,)),
layers.Dense(64, activation='relu', kernel_initializer='he_normal'),
layers.Dense(64, activation='relu', kernel_initializer='he_normal'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_19 (Dense) (None, 64) 50240
_________________________________________________________________
dense_20 (Dense) (None, 64) 4160
_________________________________________________________________
dense_21 (Dense) (None, 64) 4160
_________________________________________________________________
dense_22 (Dense) (None, 10) 650
=================================================================
Total params: 59,210
Trainable params: 59,210
Non-trainable params: 0
_________________________________________________________________
history = model.fit(x_train, y_train, batch_size=256, epochs=100, validation_split=0.3, verbose=0)
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()
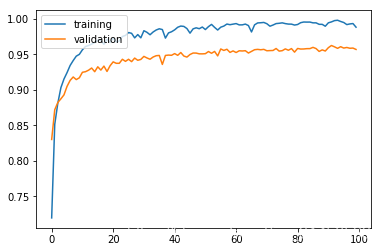
result = model.evaluate(x_test, y_test)
10000/10000 [==============================] - 0s 21us/sample - loss: 0.4355 - accuracy: 0.9587
4.激活函数
relu和sigmoid对比
model = keras.Sequential([
layers.Dense(64, activation='sigmoid', input_shape=(784,)),
layers.Dense(64, activation='sigmoid'),
layers.Dense(64, activation='sigmoid'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_23 (Dense) (None, 64) 50240
_________________________________________________________________
dense_24 (Dense) (None, 64) 4160
_________________________________________________________________
dense_25 (Dense) (None, 64) 4160
_________________________________________________________________
dense_26 (Dense) (None, 10) 650
=================================================================
Total params: 59,210
Trainable params: 59,210
Non-trainable params: 0
_________________________________________________________________
history = model.fit(x_train, y_train, batch_size=256, epochs=100, validation_split=0.3, verbose=0)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()
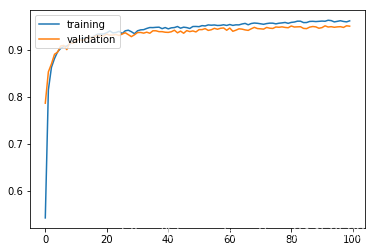
result = model.evaluate(x_test, y_test)
10000/10000 [==============================] - 0s 29us/sample - loss: 0.1526 - accuracy: 0.9529
5.优化器
model = keras.Sequential([
layers.Dense(64, activation='sigmoid', input_shape=(784,)),
layers.Dense(64, activation='sigmoid'),
layers.Dense(64, activation='sigmoid'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=keras.optimizers.SGD(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
Model: "sequential_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_27 (Dense) (None, 64) 50240
_________________________________________________________________
dense_28 (Dense) (None, 64) 4160
_________________________________________________________________
dense_29 (Dense) (None, 64) 4160
_________________________________________________________________
dense_30 (Dense) (None, 10) 650
=================================================================
Total params: 59,210
Trainable params: 59,210
Non-trainable params: 0
_________________________________________________________________
history = model.fit(x_train, y_train, batch_size=256, epochs=100, validation_split=0.3, verbose=0)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()
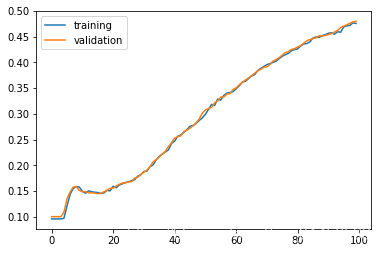
result = model.evaluate(x_test, y_test)
10000/10000 [==============================] - 0s 44us/sample - loss: 2.1199 - accuracy: 0.4749
6.批正则化
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.BatchNormalization(),
layers.Dense(64, activation='relu'),
layers.BatchNormalization(),
layers.Dense(64, activation='relu'),
layers.BatchNormalization(),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=keras.optimizers.SGD(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
Model: "sequential_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_31 (Dense) (None, 64) 50240
_________________________________________________________________
batch_normalization_v2 (Batc (None, 64) 256
_________________________________________________________________
dense_32 (Dense) (None, 64) 4160
_________________________________________________________________
batch_normalization_v2_1 (Ba (None, 64) 256
_________________________________________________________________
dense_33 (Dense) (None, 64) 4160
_________________________________________________________________
batch_normalization_v2_2 (Ba (None, 64) 256
_________________________________________________________________
dense_34 (Dense) (None, 10) 650
=================================================================
Total params: 59,978
Trainable params: 59,594
Non-trainable params: 384
_________________________________________________________________
history = model.fit(x_train, y_train, batch_size=256, epochs=100, validation_split=0.3, verbose=0)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()
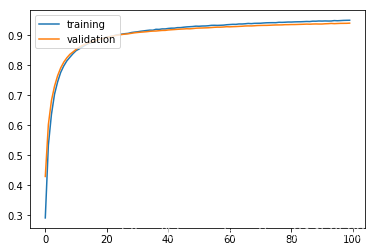
result = model.evaluate(x_test, y_test)
10000/10000 [==============================] - 0s 25us/sample - loss: 0.1863 - accuracy: 0.9447
7.dropout
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.Dropout(0.2),
layers.Dense(64, activation='relu'),
layers.Dropout(0.2),
layers.Dense(64, activation='relu'),
layers.Dropout(0.2),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=keras.optimizers.SGD(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
Model: "sequential_9"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_35 (Dense) (None, 64) 50240
_________________________________________________________________
dropout (Dropout) (None, 64) 0
_________________________________________________________________
dense_36 (Dense) (None, 64) 4160
_________________________________________________________________
dropout_1 (Dropout) (None, 64) 0
_________________________________________________________________
dense_37 (Dense) (None, 64) 4160
_________________________________________________________________
dropout_2 (Dropout) (None, 64) 0
_________________________________________________________________
dense_38 (Dense) (None, 10) 650
=================================================================
Total params: 59,210
Trainable params: 59,210
Non-trainable params: 0
_________________________________________________________________
history = model.fit(x_train, y_train, batch_size=256, epochs=100, validation_split=0.3, verbose=0)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()
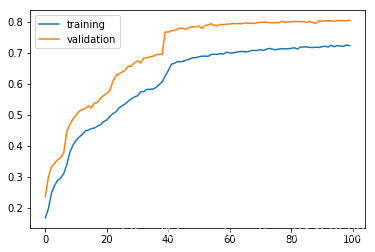
result = model.evaluate(x_test, y_test)
10000/10000 [==============================] - 0s 27us/sample - loss: 0.6157 - accuracy: 0.8132
8.模型集成
下面是使用投票的方法进行模型集成
import numpy as np
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.metrics import accuracy_score
def mlp_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.Dropout(0.2),
layers.Dense(64, activation='relu'),
layers.Dropout(0.2),
layers.Dense(64, activation='relu'),
layers.Dropout(0.2),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=keras.optimizers.SGD(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
return model
model1 = KerasClassifier(build_fn=mlp_model, epochs=100, verbose=0)
model2 = KerasClassifier(build_fn=mlp_model, epochs=100, verbose=0)
model3 = KerasClassifier(build_fn=mlp_model, epochs=100, verbose=0)
ensemble_clf = VotingClassifier(estimators=[
('model1', model1), ('model2', model2), ('model3', model3)
], voting='soft')
ensemble_clf.fit(x_train, y_train)
VotingClassifier(estimators=[('model1', <tensorflow.python.keras.wrappers.scikit_learn.KerasClassifier object at 0x7f4ed7d4c518>), ('model2', <tensorflow.python.keras.wrappers.scikit_learn.KerasClassifier object at 0x7f4ed7d4c470>), ('model3', <tensorflow.python.keras.wrappers.scikit_learn.KerasClassifier object at 0x7f4ed7d4c588>)],
flatten_transform=None, n_jobs=None, voting='soft', weights=None)
y_pred = ensemble_clf.predict(x_test)
print('acc: ', accuracy_score(y_pred, y_test))
acc: 0.9504