前言
前段时间分析了yolov3的源码,这次想带着小伙伴一起把yolov5完全掌握。博主还是保持着一贯的风格,依旧采用debug级别的源码剖析。目的就是让大家可以通过一个系列的文章就把yolov5的架构、设计理念和每一行源码都弄懂。只要小伙伴可以花时间把这个系列读完,就会对yolov5的理解有所提升。
去年参加了kaggle的小麦检测比赛,yolov5在比赛的中段开始呈现霸榜趋势,超越了efficientdet。虽然最后yolov5因为权限等某些问题被kaggle官方禁用了,但是仍然体现出了其强大的能力。值得一学,学习本篇前读者应该至少对于yolo系列中的一个或几个有所了解,对照着学习更加利于理解。
前面做了yolov3的源码剖析,不了解的读者也可以学习下:
传送门:
下面我们就开始yolov5的学习吧,第一篇我们先focus在yolov5的架构上,对其各个组件有所了解,对其设计理念有所认知,然后在这个基础上开始逐行对yolov5进行debug解析。值得注意的是yolov5的架构一直在迭代演进,不同版本之间稍有区别,但是基本上是一致的。
一.yolov5 架构剖析
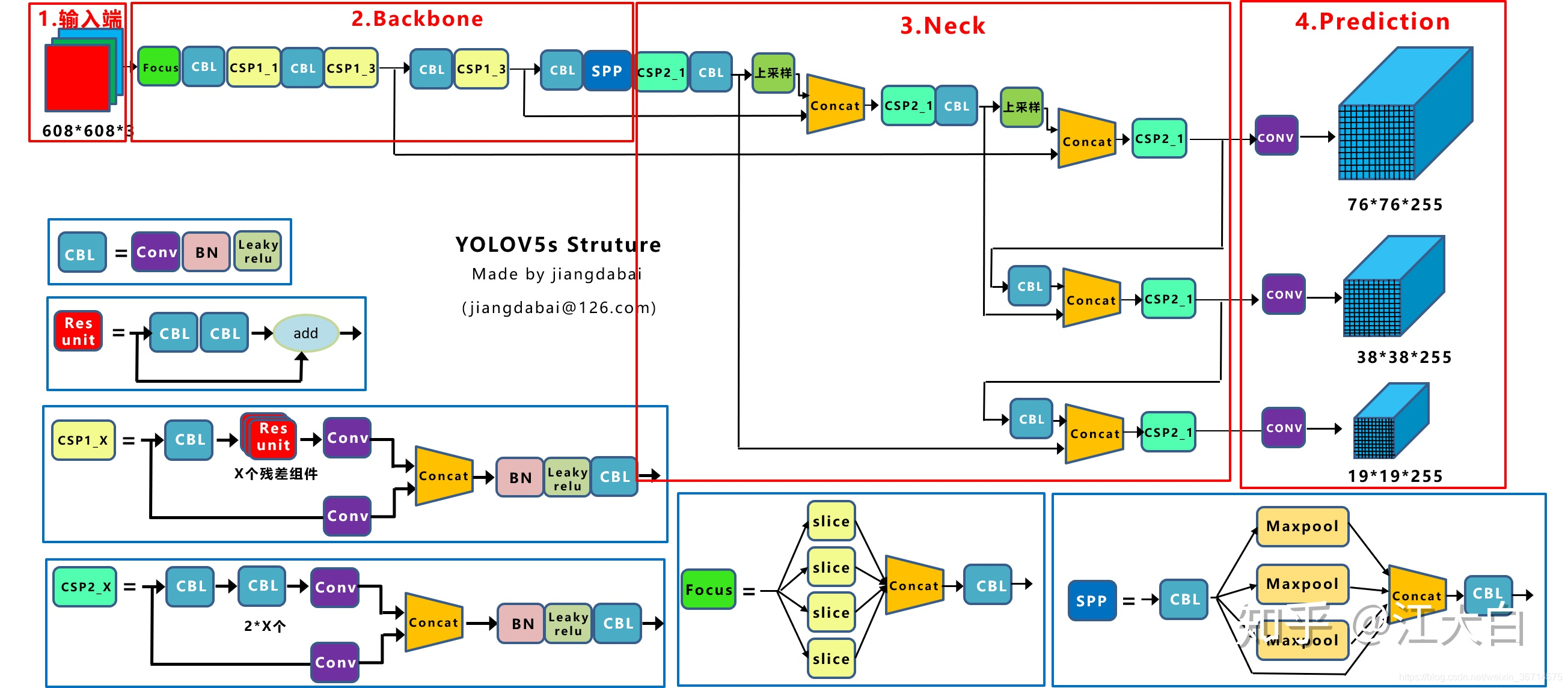
这是yolov5s的架构,图来自于百度图片,博主查了下应该是知乎上一个大神画的。这里尊重大神创作,给下地址:
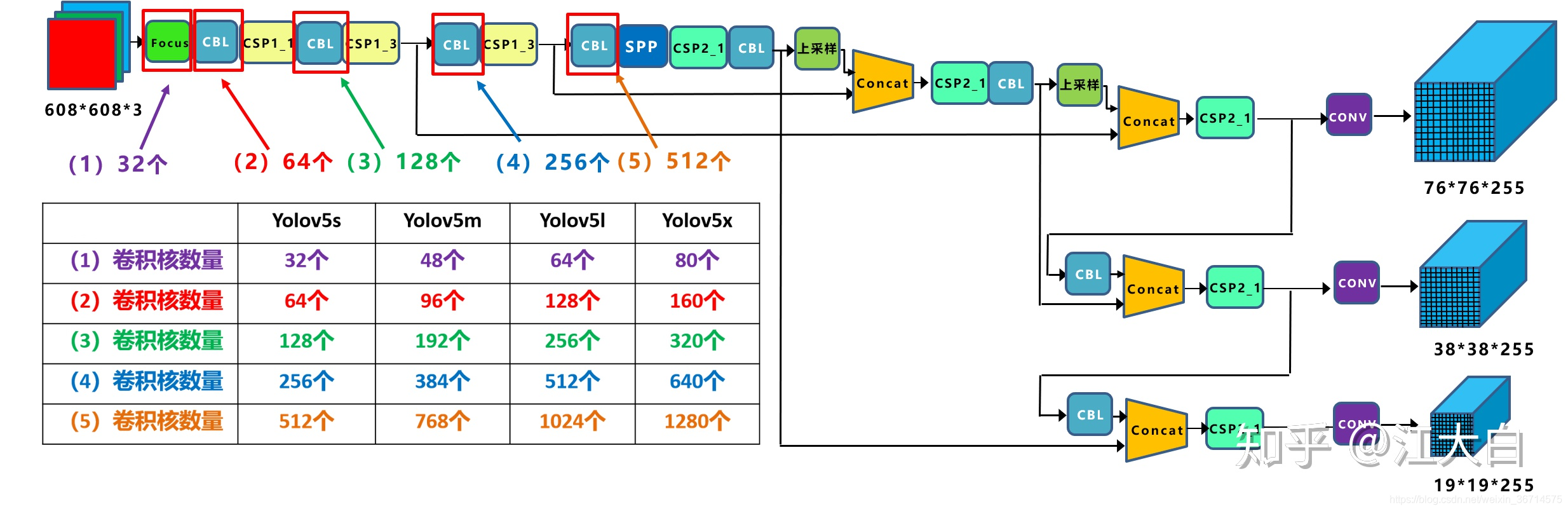
从yolov5s到yolov5x之间的差别就是不同的block叠加次数不同,见下图:
从架构上看,yolov5的架构设计并不复杂,整体上维持了FPN的设计方式,FPN加强了重复迭代,两次迭代的结构称为PAN。这个结构还可以进一步重复,类似efficientdet那样演进为BiFPN。backbone仍然是darknet的形式,通过残差结构让网络加深。模型开始引入Focus的设计有点奇特,直接就降低了resolution应该是yolov5轻量的原因之一。SPP模块的引入进一步融合了多尺度特征提取。有两种不同的CSP模块,区别是有无残差结构,
整体设计和模块的加减像是消融实验的产物,不过我们还是逐个模块过下:
1. Focus
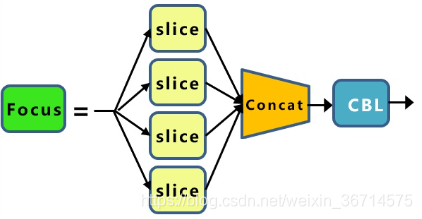
Focus的理念比较特殊,执行过程见下图:
我在观察Focus这个设计的时候带着的问题是这样的设计是为什么以及这样的设计为什么work?
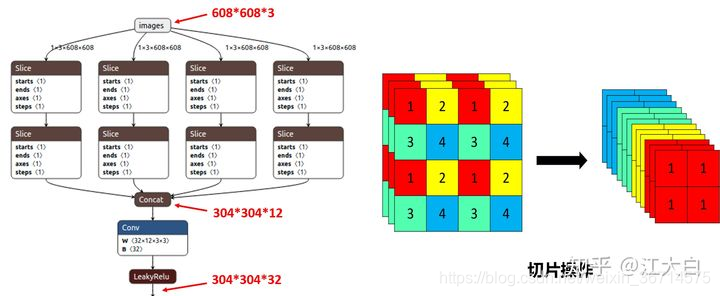
我的理解是首先它这样的排列方式是将相邻的四个块从平面改为特征上的concat。

也就是这样的四个块做了叠加,从3通道变为12通道,这样尽可能的保留了位置信息。同一个通道里应该代表着局部的特征表达,这样操作一个grid位置代表了原图四个grid的特征。在保证了位置信息尽可能保留的情况下又增大了感受野。
这样的效果是特征图的尺寸为原来的一半,在这里我想到的问题是卷积是能够保持特征的位置相对性的,那么这种focus操作能否常规化代替pooling或者是stride=2的卷积呢?我们都知道pooling对feature map的信息的丢失是很严重的(当然也有一部分正则化的作用),所以很多现在的架构设计里pooling都被stride=2的convolution代替。我又想到了shufflenet里的channel shuffle操作是在做了组卷积之后,怕看不到全局特征,为了增强channel间的特征共享,进行的特征融合。所以Focus操作后面是否也应该增强每个格点通过concat拼接起来的特征向量的融合,比如通过1x1 group convolution。yolov5的融合采用的是一个普通的CBL(conv–bn–leakyrelu)。
2.CSP
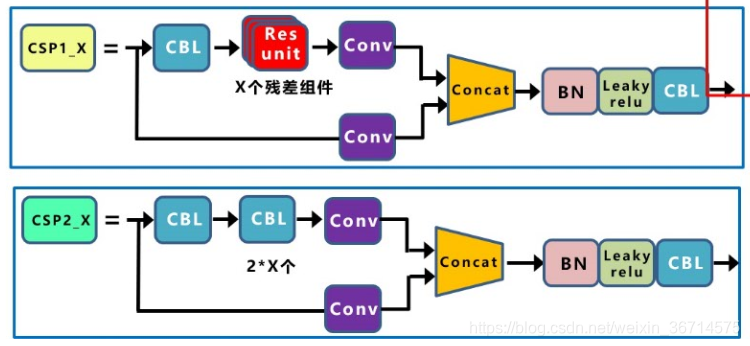
yolov5的设计中有两种CSP结构,一种是带了resunit(2*CBL卷积+残差),一种是用普通的CBL替换resunit。带残差的部分是用在backbone里,不带残差的是用在backbone之外的地方。这里应该是实验的结果,backbone为较深的网络,增加残差结构可以增强层与层之间反向传播的梯度值,避免因为加深而带来的梯度消失,从而提取到更细粒度的特征而不必担心网络退化。同时,有些研究表明残差结构可以看作非残差的ensemble,从而增强部分的泛化能力。
当然以上都是理论上的分析,我之前在竞赛中对于unet的encoder,bridge,decoder的部分都分别测试了残差结构,也发现encoder的部分对于残差结构是比较依赖的,但是bridge和decoder的残差结构都没有获得精度上的提高。这里只是说一下我之前的实验结果,供大家参考。
CSP结构的好处就是对比普通的CBL,它分为两个支路,有支路就意味着特征的融合,而concat就可以更好的把不同支路的特征信息保留下来,因此CSP的设计可以提取到更为丰富的特征信息。
3.SPP
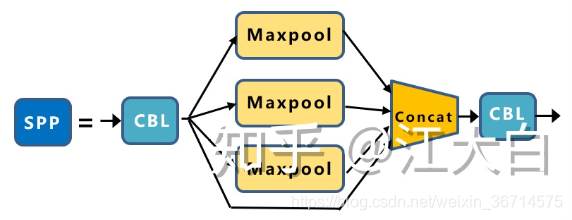
SPP这个结构就是通过不同kernel size的pooling抽取不同尺度特征,再进行叠加进行特征融合。在yolov5里pooling的kernel size分别是11, 55, 99, 1313。
我在很多比赛中都测试过SPP和ASPP加在不同网络的各种位置,其实就是为了找到适配数据的最佳感受野大小,但1其实这个过程是比较耗时的,因为对应的pooling kernel和dilation rate都是非常难以调整的。因此我经常使用可变形卷积让网络自动适配感受野,起到替代SPP/ASPP的作用。
4.PAN
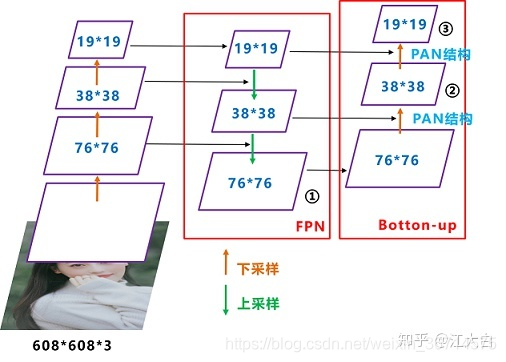
FPN还是PAN或者后面的BiFPN都是类似的结构。FPN的理念就是增强不同层特征融合,在多尺度上进行预测。PAN在FPN的基础上又加了从下到上的融合。
我们都知道,深层的feature map携带有更强的语义特征,较弱的定位信息。而浅层的feature map携带有较强的位置信息,和较弱的语义特征。FPN就是把深层的语义特征传到浅层,从而增强多个尺度上的语义表达。而PAN则相反把浅层的定位信息传导到深层,增强多个尺度上的定位能力。
再联想后来的BiFPN,语义特征和定位信息在串联的FPN/PAN结构中被像踢皮球一样的“传来传去”…咳咳,都是玄学。
以上就是yolov5中的架构比较特殊的地方,具体我们还是在代码中去识别他们。
二.yolov5 源码剖析准备
我们在debug前先要保证把yolov5跑起来。安装下面的步骤操作就可以跑通:
1.下载yolov5源码,安装requirement.txt
需要注意python>=3.8,pytorch>=1.7。
$ git clone https://github.com/ultralytics/yolov5 # clone repo
$ cd yolov5
$ pip install -r requirements.txt # install dependencies
2.配置dataset的yaml文件,准备数据
yolov5识别yaml配置文件,所以自定义的数据集就要按照模板去写。我们以最简单的coco128为例,coco128是coco数据集的前128张组成的小型数据集,用来验证流程。地址在yolov5/data文件夹里,coco128.yaml。我们来看下coco128.yaml的内容:
# COCO 2017 dataset http://cocodataset.org - first 128 training images
# Train command: python train.py --data coco128.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /coco128
# /yolov5
# download command/URL (optional)
download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../coco128/images/train2017/ # 128 images
val: ../coco128/images/train2017/ # 128 images
# number of classes
nc: 80
# class names
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ]
可见定义数据集的配置文件需要可以包含三个部分内容:
- download:下载地址(可选的)
- train/val:train数据集和val数据集的相对路径
- nc:类别数
- names:类别的具体名字
我们先手动下载coco128数据集,并放在yolov5的同一级目录里:
如上图所示放在同一级目录。
images不用多说,就是训练图片,而labels需要注意下格式,自己标注的也要注意转换为yolo格式。
每一个图片的label单独存放在一个txt文件里,每一个框单独占一行。如下图所示:
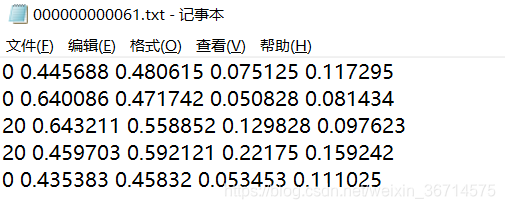
坐标需要做归一化,如下图:

如上图所示,yolo的标签数据为[class, x_center, Y_center, width, height]的格式,要注意class是从0开始计算的。四个坐标则都需要归一化到0-1之间,也就是如果你的数据是pixel的,那么需要对应除以宽高。
最后文件夹相应位置如下图所示对齐:
如果准备好了coco128数据,就可以测试了。
3.准备好模型文件
模型默认有yolov5s、m、l、x四种,参数量从小到大。大家在官网下载好对应的模型。
我这边下载一个yolov5s做演示。下载好放到weights文件夹下:
$ python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov5s.pt
执行上述代码进行测试,可以看到训练开始。
Epoch gpu_mem box obj cls total targets img_size
0/4 0G 0.0492 0.0805 0.03435 0.1641 35 640: 16%|██████▋
4.wandb*
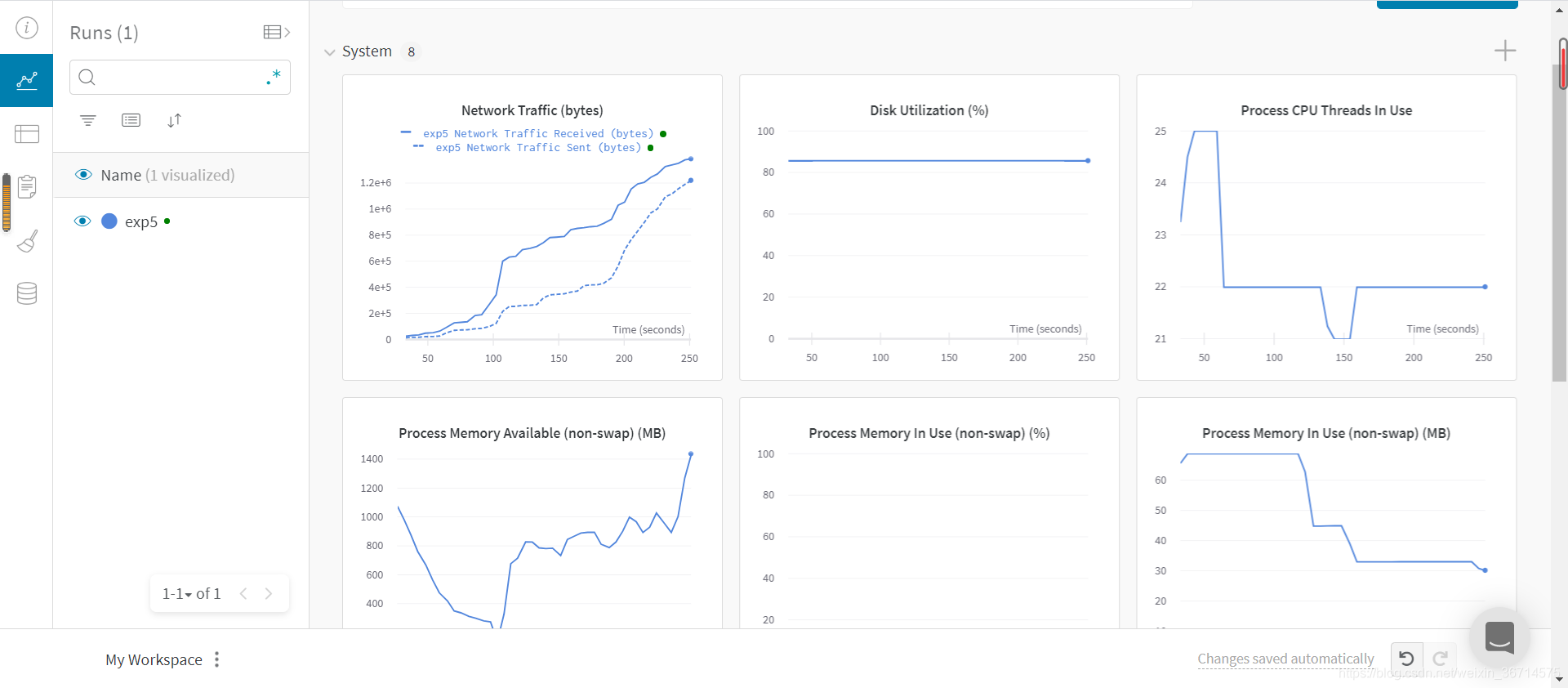
yolov5可以配置wandb,一个动态展示训练状态的web portal,用以观察loss和设备情况。
以上我们就成功跑通了yolov5,为我们后面开始debug源码做好了准备。请大家移步到下一篇让我们共同探索yolov5的源码吧!