ScheduledThreadPoolExecutor有一个功能,就是可以指定执行间隔,周期性的去执行指定的任务,和timer、定时任务的作用类似,网上也有好多说ScheduledThreadPoolExecutor的性能要比timer高,这个我还没有研究到,所以就不做对比,这篇笔记,主要记录部分源码的学习
类结构
ScheduledThreadPoolExecutor
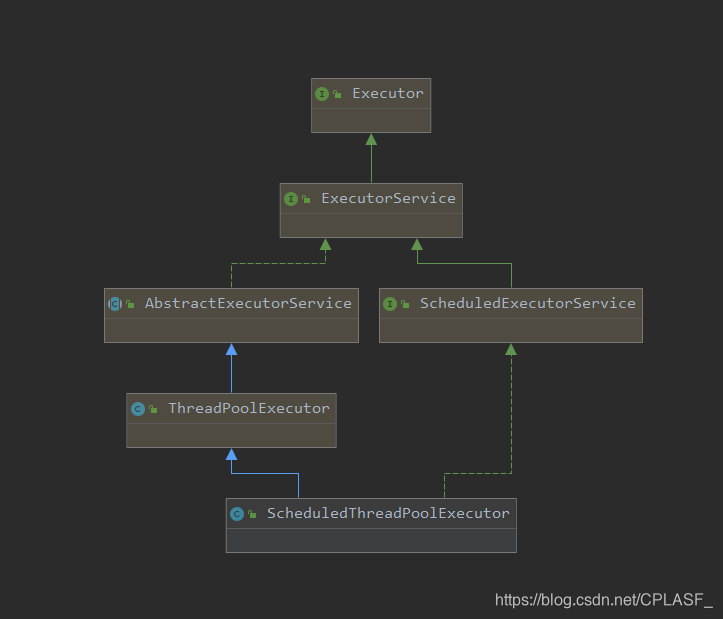
可以看到 ScheduledThreadPoolExecutor继承了线程池ThreadPoolExecutor,除此之外,还实现了ScheduledExecutorService,说明了这个类至少是一个线程池,除此之外,在线程池之上,还有一些其他的功能
ScheduledExecutorService
我们可以看到ScheduledExecutorService是一个接口,里面定义了四个方法
public interface ScheduledExecutorService extends ExecutorService {
public ScheduledFuture<?> schedule(Runnable command,
long delay, TimeUnit unit);
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay, TimeUnit unit);
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
}
这四个方法的前两个不说了,就是开启一个延迟的任务,只会执行一次
下面这两个都是开启延迟定时周期性执行任务的,下面再具体研究
DelayedWorkQueue
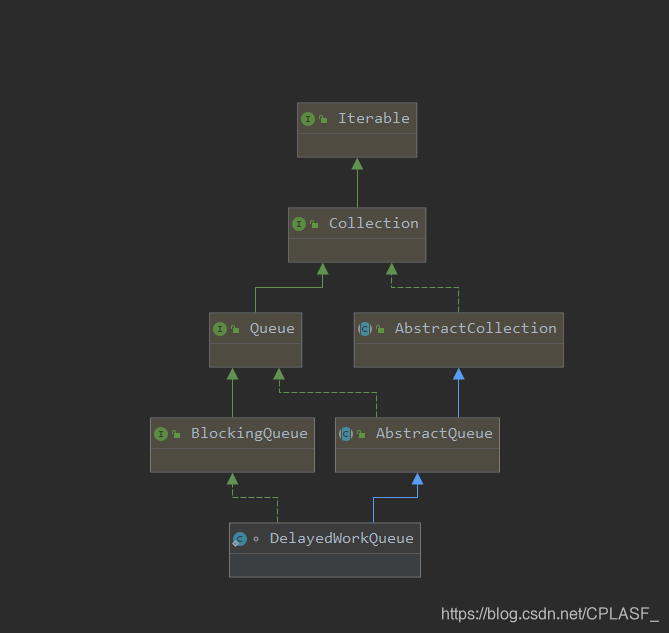
这个类的作用,我觉得可以理解为:DelayedWorkQueue = DelayQueue + PriorityQueue 关于这三个类的笔记,我想单独再写一篇笔记来记录,所以这里不做过多的讨论,
我们可以认为这个内部类完成的操作就是:在将定时任务的元素插入到队列中的时候,会进行优先级排序,将最先执行的任务放到前面
比如:A任务5S之后执行,这时候插入了一个B任务,B任务需要在2S之后执行,那就把B插入到A前面
ScheduledFutureTask
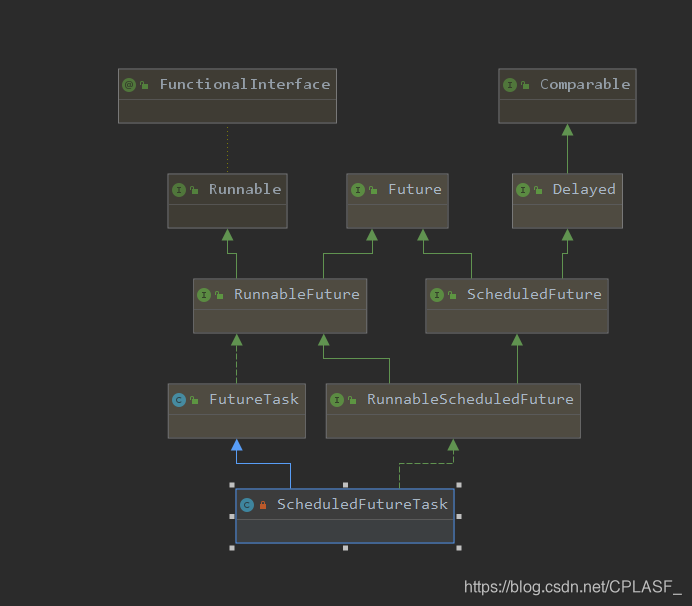
这个类的作用,我目前的理解是:对我们指定的要执行的任务进行了一层包装
源码
公共方法一、triggerTime(delay, unit)
这个方法是在当前时间的基础之上 加上delay的时间,作为该任务执行的时间
long triggerTime(long delay) {
return now() +
((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
}
公共方法二、decorateTask
这个方法主要是对指定的task进行一层再包装,包装成ScheduledFutureTask对象
公共方法三、delayedExecute
这个方法是为了将包装好的任务,添加到任务队列中
/**
* 这个方法是把任务添加到队列中,在scheduledThreadPoolExecutor中,这里的队列是优先级队列
* 1.添加到任务队列之前,会判断下线程池的状态,如果是非运行状态,就执行拒绝策略
* 2.在添加到任务队列之后,如果线程池是shutdown状态,就remove,并且将任务取消
* 3.如果不需要取消任务,就执行ensurePrestart(); 在该方法中,会判添加一个空的worker任务,去执行队列中的任务
* @param task the task
*/
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);
else {
super.getQueue().add(task);
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
/**
* Same as prestartCoreThread except arranges that at least one
* thread is started even if corePoolSize is 0.
* 判断当前线程池中工作线程的数量
* 如果小于核心线程数,就添加一个核心线程
* 如果大于核心线程数,就添加一个非核心线程
* 这里是空任务的原因:就是为了开启一个线程,去执行任务队列中排队的任务
*/
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
ensurePrestart:这个方法中,添加一个worker对象,在前面线程池源码中我有记录过,其实就是线程池的线程会被包装成worker对象,存到线程池中,这里添加一个null,就是为了让线程去执行任务队列中的任务
入队方法
在调用super.getQueue().add(task);的时候,就会调用相应的offer方法进行入队
/**
* 入队方法,将待执行的任务插入到队列中
* 在入队的时候,会进行优先级的判断
* @param x
* @return
*/
public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;
final ReentrantLock lock = this.lock;
/**
* 1.加锁
*/
lock.lock();
try {
int i = size;
/**
* 2.判断是否需要进行扩容
* 这里的扩容,和ArrayList扩容的方法类型:
* 先扩容50%,然后通过Arrays.copy将数组扩容之后的数据,再复制到queue中
*/
if (i >= queue.length)
grow();
size = i + 1;
/**
* 3.如果当前插入的是第一个任务
* 就将e设置为头结点
*
* 否则的话,就进行优先级的处理
*/
if (i == 0) {
queue[0] = e;
setIndex(e, 0);
} else {
siftUp(i, e);
}
/**
* 4.这里是如果插入了第一个元素,去通知
* take方法,这里的available是一个condition对象
*/
if (queue[0] == e) {
leader = null;
available.signal();
}
} finally {
lock.unlock();
}
return true;
}
上面入队的方法,注释写的还算可以,所以就不做过多说明,在入队的时候,有一个关键方法,就是对队列中的元素进行排队,其实就是在新插入一个元素的时候,要判断下当前元素要插入到哪里,根据元素对应的过期时间,也就是执行时间来比较,越早执行的,放到前面
优先级排序
/**
* Sifts element added at bottom up to its heap-ordered spot.
* Call only when holding lock.
* 这是DelayedWorkQueue自己实现的,在入队时,进行优先级判断的逻辑
* k:当前待插入元素要入队的位置
* key:就是要入队的任务
*/
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
/**
* 1.获取到k对应的父节点元素
*/
int parent = (k - 1) >>> 1;
RunnableScheduledFuture<?> e = queue[parent];
/**
* 2.如果任务k执行的时间晚于e父节点的,就无需再遍历处理
* 如果k的执行时间早于e,那就需要交换位置,然后再次遍历判断父节点和交换之后的优先级
*/
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
/**
* 设置待插入元素的实际位置
*/
queue[k] = key;
setIndex(key, k);
}
在比较的时候,是和当前元素的父元素比较,因为采用的是二叉树来存储,判断的核心方法就是compareTo方法,RunnableScheduledFuture也重新覆写了该方法
/**
* 用来比较优先级,这里的other是插入元素要对比的元素
* @param other
* @return
*/
public int compareTo(Delayed other) {
if (other == this) // compare zero if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
/**
* 如果当前要插入的元素对应的时间 早于X节点执行,那就返回-1
* 如果要插入的元素对应的执行时间 晚于X节点执行,那就返回1
* 举例:X要在5S之后执行,但是当前插入的元素在2S之后执行,那这里的diff就小于0,返回-1
* 如果X要5S之后执行,但是待插入元素是10S之后执行,那这里的diff就大于0,返回1
* 至于下面的sequenceNumber应该是在任务是同时执行的情况下,再进行的优先级判断吧
*/
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
/**
* 如果要比较的任务不是ScheduledFutureTask,那就直接获取到每个任务还有多少毫秒要执行,进行优先级判断
*/
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
}
执行队列中的任务
由于在入队的时候,我门指定的任务被包装成了ScheduledFutureTask,所以执行的时候,会执行对应的run方法
/**
* Overrides FutureTask version so as to reset/requeue if periodic.
* 自定义的任务在执行的时候,实际调用的就是这个方法,因为线程池对任务进行了一层包装
*/
public void run() {
/**
* 1.首先判断是否需要重复执行,这个值是在初始化的时候,指定的
* 如果只需要执行一次,这里返回的就是false
* 如果需要周期定时执行,这里返回的就是true
* 根据period的值来判断
*/
boolean periodic = isPeriodic();
/**
* 2.这里没看懂,判断是否需要取消任务?
*/
if (!canRunInCurrentRunState(periodic))
cancel(false);
/**
* 3.如果只需要执行一次,就会执行这里的逻辑
*/
else if (!periodic)
ScheduledFutureTask.super.run();
/**
* 4.如果是需要重复执行的,就执行这里的方法
* 如果任务正常执行成功,就继续设置下次的执行时间
* setNextRunTime():是在当前时间的基础之上,加上第一次指定的延迟时间
* reExecutePeriodic():是将任务再次加入队列中
*/
else if (ScheduledFutureTask.super.runAndReset()) {
setNextRunTime();
reExecutePeriodic(outerTask);
}
}
第四点 就是可以重复执行的关键点,在判断需要重复执行的时候,就会再次入队
1、而判断是否可以重复执行,又是根据ScheduledFutureTask构造方法来决定的,在下面可以看scheduleAtFixedRate和schedule构造函数的区别
2、在需要重复执行的时候,就会把任务再次入队
/**
* Requeues a periodic task unless current run state precludes it.
* Same idea as delayedExecute except drops task rather than rejecting.
*
* 将需要重复执行的任务,再次入队
* @param task the task
*/
void reExecutePeriodic(RunnableScheduledFuture<?> task) {
if (canRunInCurrentRunState(true)) {
super.getQueue().add(task);
if (!canRunInCurrentRunState(true) && remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
构造方法
public ScheduledThreadPo olExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
构造方法的话,就选取了其中一个来看,构造方法也是去初始化一个线程池,特殊的地方就在于,这个线程池类,不支持指定队列,只能使用DelayedWorkQueue,指定使用这个队列,是为了实现优先级排序
schedule
/**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
* 这是只执行一次的方法,也就是说:callable会在delay秒之后执行
* 执行一次之后,就结束
*/
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay,
TimeUnit unit) {
if (callable == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<V> t = decorateTask(callable,
new ScheduledFutureTask<V>(callable,
triggerTime(delay, unit)));
delayedExecute(t);
return t;
}
这个方法就简单明了了,将指定的任务,在当前时间的基础之上,加上指定的延迟事件delay,放入到队列中,然后由线程池的线程去任务队列中获取执行
定时周期执行
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(period));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
/**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
* @throws IllegalArgumentException {@inheritDoc}
*/
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(-delay));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
/**
* 对于需要重复执行的任务,会在这里将任务赋值到一个变量中
*/
sft.outerTask = t;
delayedExecute(t);
return t;
}
这两个方法一起看下,只有一个地方不一样,就是在将任务包装成ScheduledFutureTask对象的时候,一个是负数,一个是正数,这里的区别还没有研究到,后面再说
总体这里的逻辑是:
1.将任务包装成ScheduledFutureTask
2.将任务赋值到一个临时变量中,这个临时变量outerTask 很重要,是再次入队的关键变量
3.然后即将任务入队
总结:
- ScheduledThreadPoolExecutor支持周期性定时任务,在jdk6之前是依赖于DelayQueue,但是在jdk6之后,ScheduledThreadPoolExecutor自己实现了类似DelayQueue的逻辑,就是DelayedWorkQueue
- 在入队的时候,会进行优先级的判断,所谓的优先级,就是根据任务执行的先后来排序,放在前面的,永远是最近要执行的
- 在出队之后,会判断任务是需要重复执行的,还是只执行一次
- 如果只需要执行一次,执行完就结束
- 如果需要执行多次,在执行完之后,会将任务再次入队,相同的任务,相同的延迟时间,入队会再进行一次优先级排队