第2章 模型评估与选择

2.4 比较检验
2.4.1 假设检验
假设检验目的(0223)
理想情况下
| 训练集 | 验证集 | 测试集 | |
|---|---|---|---|
| 真实值y | |||
| 经过模型f(x)得预测值y’ | |||
| 由以上2项可得错误率 |
但是在真实世界中,还会有更多的数据,测试集的错误率能多大程度上保证真实的性能,而假设检验的目的就是为了保证这个程度
泛化问题与概率论课程推荐(0224)

2个泛化性能
- 在训练集上得到一个模型,然后在测试集上的表现怎样
- 这个模型在全部真实数据上的表现怎样
问题
- 测试集上的性能与真正的泛化性能未必相同
- 测试集不同反映出来的性能不同
- 机器学习算法本身具有一定的随机性,同一测试集上多次运行,可能会有不同的结果
她推荐的是 概率论与数理统计【合集】【小元老师】
二项分布(0225)

已知
- 测试集上m=10,错误率=m’/m
- 真实数据上的错误率为0.3
求测试集上各种出错情况的概率
以下为视频中解释的假设检验思路

代码实现二项分布(0226)

round(m_T_error / m, 4) # 对m'/m曲小数点后4位

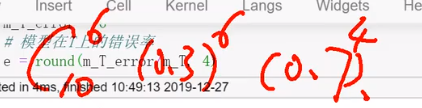
上上图黄色背景式子与上式等价
comb(m_T, m_T_error) # 排列组合C~10~^6^
e_all**m_T_error # 0.3^6

m_T_errors=[0,1,2,3,4,5,6,7,8,9,10] 是错误个数的列表集合(错0个、1个。。。10个)
运行结果:



可得结论:
当假设了在真实数据上的错误率=0.3得情况下,在测试集上进行实验时,错3个的概率较大
测试集错误率=3/10=0.333与真实数据上的错误率=0.3相差不大
假设检验举例e=0.3(0227)
假设90%的置信区间

若实际测得在测试集上错了5个,看上图,它在90%里,所以接受原假设
若实际测得在测试集上错了10个,看上图,它不在90%里,所以拒绝原假设
假设e_0大于等于0.3(0228)


当错5个时,左边的面积占比90%,所以大于等于5,就拒绝假设
另一个更直观的理解:


由上述程序可知,当x=5时,概率累加为0.9552…>90%,所以大于等于5,就拒绝假设
多个测试集一种算法的假设检验(0229)

