第2章 模型评估与选择
模型评估与选择(0201)

分别看 一种训练集一种算法、一种训练集多种算法、多种训练集一种算法、测试集上的性能在多大程度上保证真实的性能 这几种情况下的如何对模型进行评估与选择
2.1 经验误差与过拟合(0202)

以识别手写字体为例
m为样本数量,假设 m=10000
| x | 第1张图片 | 第2张图片 | 。。。 | 第m张图片 |
|---|---|---|---|---|
| Y(图片上的数字) | 1 | 9 | 。。。 | 7 |
| f(x)=Y’(经过模型预测后的数字) | 1 | 9 | 。。。 | 1 |
假设模型预测错了a=100个,则
- 错误率(error rate) E=a/m=100/10000
- 精度(accuracy) = 1-E(写成百分比形式)
- 误差(error) = |Y-Y’|
训练误差(training error)/ 经验误差(empirical error):模型在训练集上的误差
泛化误差(generalization):在新样本上的误差
我们希望得到泛化误差小的模型,但是事先不知道新样本什么样,实际能做的是努力使经验误差最小化。但是这种经验误差很小、在训练集上表现很好的模型多数情况下并不好
学习能力是否“过于强大”,是由学习算法和数据内涵共同决定的
| 过拟合(overfitting) | 欠拟合(underfitting) | |
|---|---|---|
| 概念 | 过配,当学习器把训练样本学得太好了的时候,很可能已经把训练样本本身的一些特点当作了潜在样本都具有的一般性质,这样就会导致泛化性能下降 | 欠配,指对训练样本的一般特性都没学好 |
| 造成因素 | 有很多因素可能导致过拟合,其中最常见的情况是由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学到了 | 通常由于学习能力低下造成的 |
| 应对措施 | 过拟合不可避免,只能缓解,或减小其风险 | 容易克服,例如在决策树学习中拓展分支、在神经网络学习中增加训练轮数等 |

2.2 评估方法【训练集验证集与测试集】(0203 测试集分割流出法)

通常可通过试验测试来对模型的泛化误差进行评估并进而做出选择
在现实任务中往往还会考虑时间开销、存储开销、可解释性等方面的因素
泛化能力:即模型对没见过的数据的预测能力
使用训练集(training set)对模型进行训练
使用测试集(testing set)来测试模型对新样本的判别能力
通常假设测试样本也是从样本真实分布中独立同分布采样而得。但须注意的是,测试集应尽可能与训练集互斥,即测试样本尽量不在训练集中出现、未在训练过程中使用过
原因:希望得到泛化性能强的模型。若测试样本被用作训练,则会得到过于“乐观”的估计结果。如老师给了10道题作为考试范围,考试时老师出的也是这10道题,但是得高分的同学可能只会这几道题
如何对数据集进行适当处理,从中产生训练集S和测试集T?
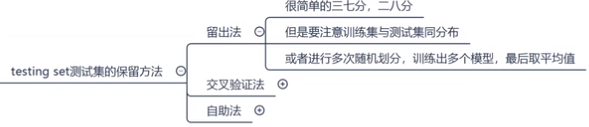
2.2.1 留出法(hold-out)
直接将数据集D划分为2个互斥的集合,
- 一个集合作为训练集S,训练模型
- 另一个集合做测试集T,评估其测试误差,作为对泛化误差的估计
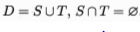

注:
- 训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响
例如,在分类任务中至少要在保持样本的类别比例相似。从采样的角度看带数据集的划分过程,则保留类别比例的采样方式通常称为分层采样(stratified sampling)
若D包含500个正例,500个反例,分层采样得70%的S和30%的T,则S应包含350个正例、350个反例,T应包含150个正例、150个反例 - 即便在给定训练/测试集的样本比例后,仍存在多种划分方式对初始数据集D进行分割
例如,可以把前350个正例放在训练集S中,也可以把后350个正例放在S中
不同划分方式产生不同的训练/测试集,会导致模型估计的结果也会有差别
可以多次随机划分、重复进行实验评估后取平均值作为留出法的评估结果
留出法的问题:
- 若S包含的样本数>>T,则训练出的模型更可能接近用D训练出的模型,但因为T较小,评估结果可能不够稳定准确
- 若令T多包含些样本,S与D的差别大了,被评估的模型与用D训练出的模型相比可能有较大差别,从而降低了评估结果的真实性(fidelity)
- 没有完美的解决方案,常见做法是将大约2/3~4/5的样本用于训练

2.2.2 交叉验证法(cross validation)(0204)
k折交叉验证(k-fold cross validation)

假设k=10,则把数据分为10份,
- 第一次取第10份做测试集,第1-9份做训练集,得测试结果1
- 第二次取第9份做测试集,取其他份做训练集,得测试结果2
- .。。。
- 第十次取第1份做测试集,取其他份做训练集,得测试结果10
- 对这10次得结果取平均值,返回结果
缺点:数据量较大时,对计算力要求较高。耗时长
2.2.3 自助法(bootstrapping)(0205)

假设数据集D包含m个样本,对其进行采样产生数据集D’,
- 每次随机从D中取一个放入D’,取完放回,
- 重复m次,得到包含m个样本的数据集D’
- 显然D中得部分样本会在D’中重复出现,而另一部分不会出现
- 样本在m次采样中始终不被采到的概率是(1-1/m)m,取极限得
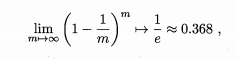
- D’做训练集,D在D’中没出现的部分做测试集

好处:
- 自助法适用于数据集较小、难以有效划分训练/测试集的情况。
- 自助法能从初始数据集中产生多个不同的训练集,对集成学习等方法有很大的好处
缺点:
- 自助法产生的数据改变了初始数据集的分布,这会引起估计偏差
- 因此,在初始数据量足够时,留出法和交叉验证法更常用
2.2.4 调参与最终模型(0206 验证集)

把训练数据在分为训练集和验证集,
- 用训练集进行训练
- 用验证集进行模型选择和调参
- 之后再把选择好的模型应用在整个 Training Set 上