第2章 模型评估与选择
2.3 性能度量(0207 均方误差)

性能度量(performance measure):对模型的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准
性能度量反映了任务需求,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果
这意味着模型的好坏是相对的,什么样的模型是好的,不仅取决于算法和数据,还取决于任务需求

如 m=3时
| D | (x1,y1) | (x2,y2) | (x3,y3) |
|---|---|---|---|
| (2,3) | (4,5) | (7,1) | |
| f(x) | 4 | 5 | 1 |
则
- 均方误差(mean squared error)= ((4-3)2 + (5-5)2 + (1-1)2) / 3
- 公式2.3就是再乘个概率
2.3.1 错误率与精度(0208)
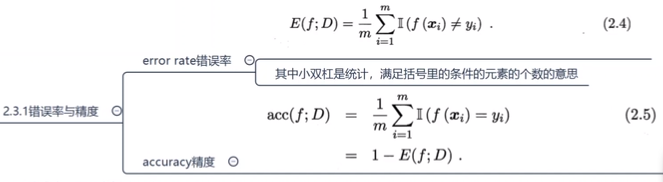
错误率(error rate):分类错误的样本数占样本总数的比例
精度(accuracy):分类正确的样本数占样本总数的比例
如 m=3时
| D | (x1,y1) | (x2,y2) | (x3,y3) |
|---|---|---|---|
| (2,3) | (4,5) | (7,1) | |
| f(x) | 4 | 5 | 1 |
| y1!=f(x1) | y2=f(x2) | y3=f(x3) |
则
- error rate = 1/3
- acc = 2/3 = 1- error rate

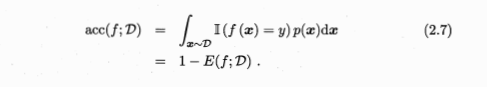
2.3.2 查重率、查全率与F1
查重率、查全率(0209)
查准率(precision),亦称准确率
- 挑出的西瓜有多少是好瓜
- 检索出的信息有多少比例是用户感兴趣的
查全率(recall),亦称召回率
- 所有好瓜中有多大比例被挑了出来
- 用户感兴趣的信息中有多少被检索出来了
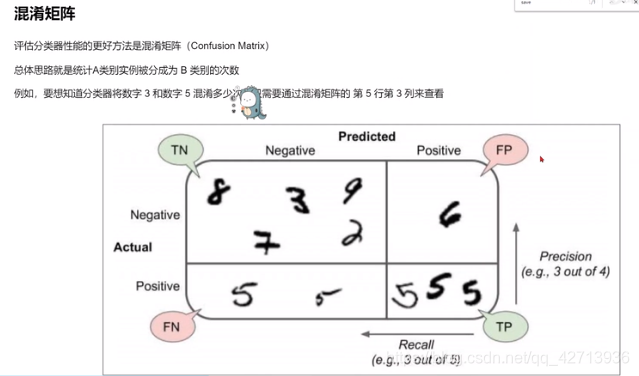
假设 m=100,y=1为正例,y=0为反例
| 实际值y | 1 | 0 | 1 | 0 | … | 1 |
|---|---|---|---|---|---|---|
| 预测值y’ | 1 | 1 | 1 | 1 | … | 0 |
若此时实际情况中正例有60个,反例40个;预测结果中正例70个,反例30个
| 真实情况 \ 预测结果 | 正例(70个) | 反例(30个) |
|---|---|---|
| 正例(60个) | TP(真正例50个) | FN(假反例10个) |
| 反例(40个) | FP(假正例20个) | TN(真反例20个) |
查准率 P = TP / (TP+FP) = 50/70
查全率 R = TP / (TP+FN) = 50/60
P-R反向关系原理(0210)
机器学习实战-第三章解释了只用准确率有问题
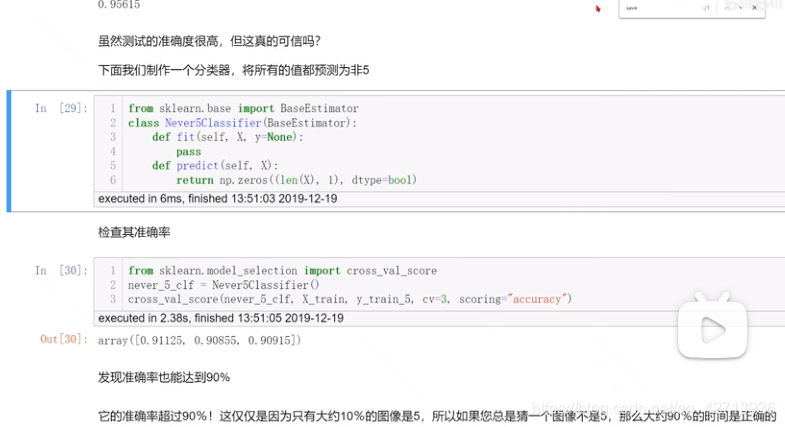
上图为手写数字识别的例子,假设给了10个数1-10,做二分类,即判断一个数是不是5
- 刚开始训练了1个模型,预测的准确率(=预测对的/全部)是96.615%
- 再给一个模型,只要见到数字就判断不是5,得到的准确率也会在90%以上
这就说明了为什么准确度通常不是分类器的首选性能指标,尤其是在处理斜偏的数据集时,即某些类比其他类更频繁时
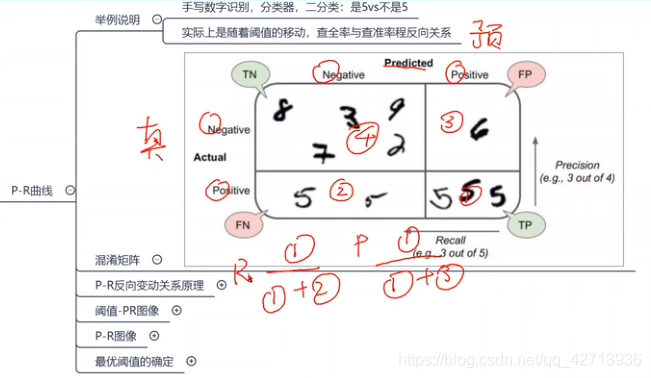
为什么P-R反向变动?(P-R反向变动关系原理)
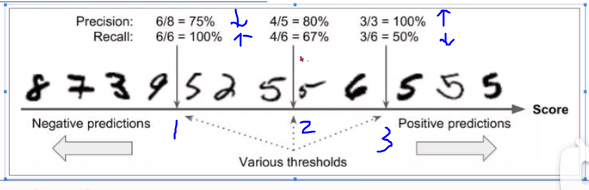
域值(thresholds)从2->3 P变大,R变小;从2->1 P变小,R变大
一般而言,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。例如,
- 若希望将所有好瓜尽可能多地选出来,则可通过增加选瓜的数量来实现,如果将所有西瓜都选上,那么所有的好瓜也必然都被选上了,但这样查准率就会降低;
- 若希望选出的好瓜比例尽可能高,则可只挑选最有把握的瓜,但这样就难免会漏掉不少好瓜,是查全率较低
通常只有在一些简单任务中,才能使查重率和查全率都很高
P-R反向关系图像与F1(0211)
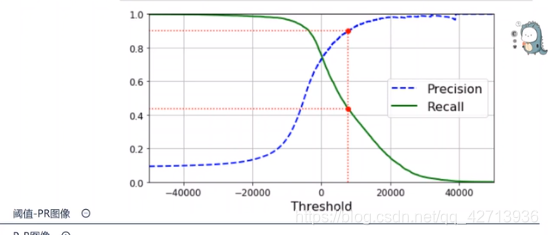
当域值变大时,P增大,R减小
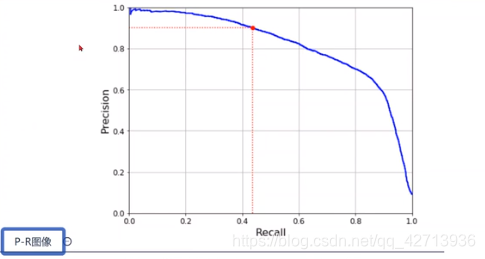
在与 域值-PR图 同一模型下,变为 P-R图像
域值-PR图 下,P=0.1 R=1,依次在图上描点得P-R的反向关系图
但是怎样选让模型性能最优?
最优阀值的确定

方法一:R=P的点
方法二:F1度量
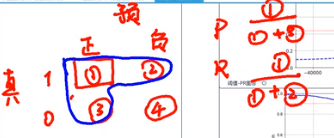
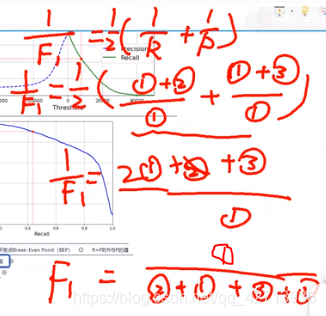
方法三


圈1和圈3的权重是1,圈1和圈2的权重是beta2
当beta>1时,R有更大影响
当beta<1时,P有更大影响

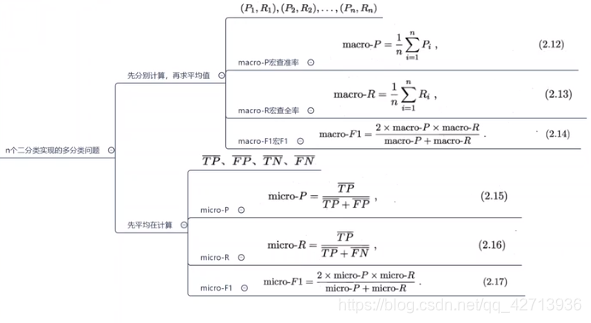
macro/micro - P/R(0213)
实现多分类(以手写数字识别为例)
- 直接使用算法
- 使用二分类
- O vs 1 (?):2个数字一组,1、2;1、3;1、4; … ;2、3;2、4;… 。一共需要10*9/2=45个模型
- O vs Rest:1和其他;2和其他;…;10和其他 。一共需要10个模型
以上出现了很多个二分类,很多个P和R,但这些二分类本质相同,共同解决了一个多分类问题。如何去衡量这个模型的好坏?
- 方法1:先计算,再求平均值
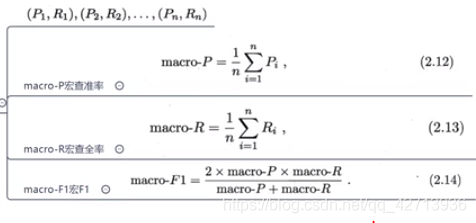
- 方法2:先平均再计算

以上所学一种训练集多种算法
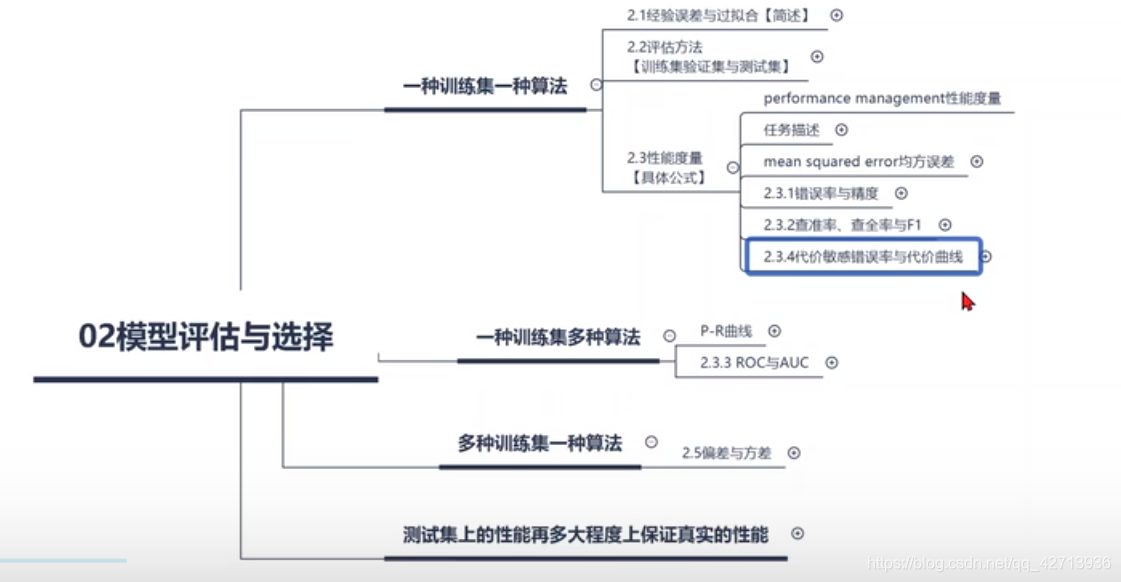
接下来多种训练集一种算法
0214使用P-R曲线比较不同模型
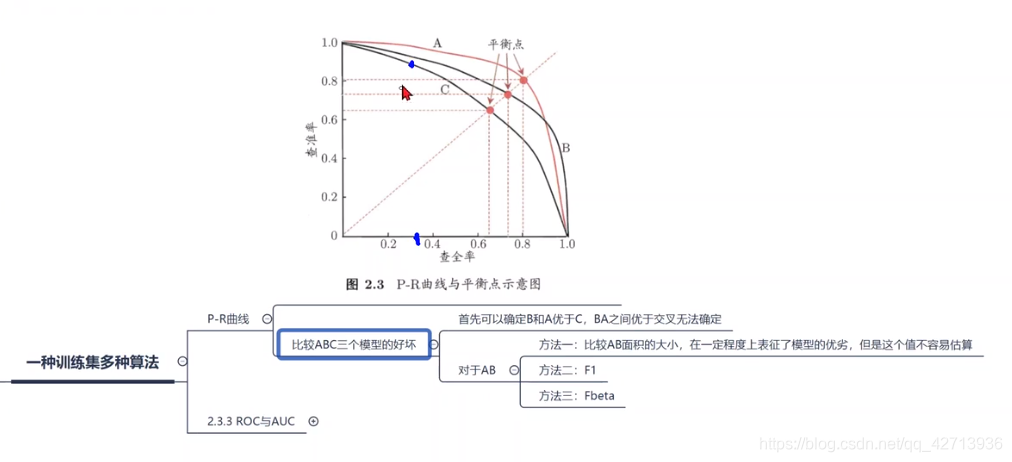
在查全率相同的情况下,B的查准率>C的,所以B要比C好
但AB不好比较,有以下3种方法:
- 比较AB的面积大小
- 比F1
- 比Fbeta
2.3.3 ROC与AUC
ROC曲线与AUC(0215)
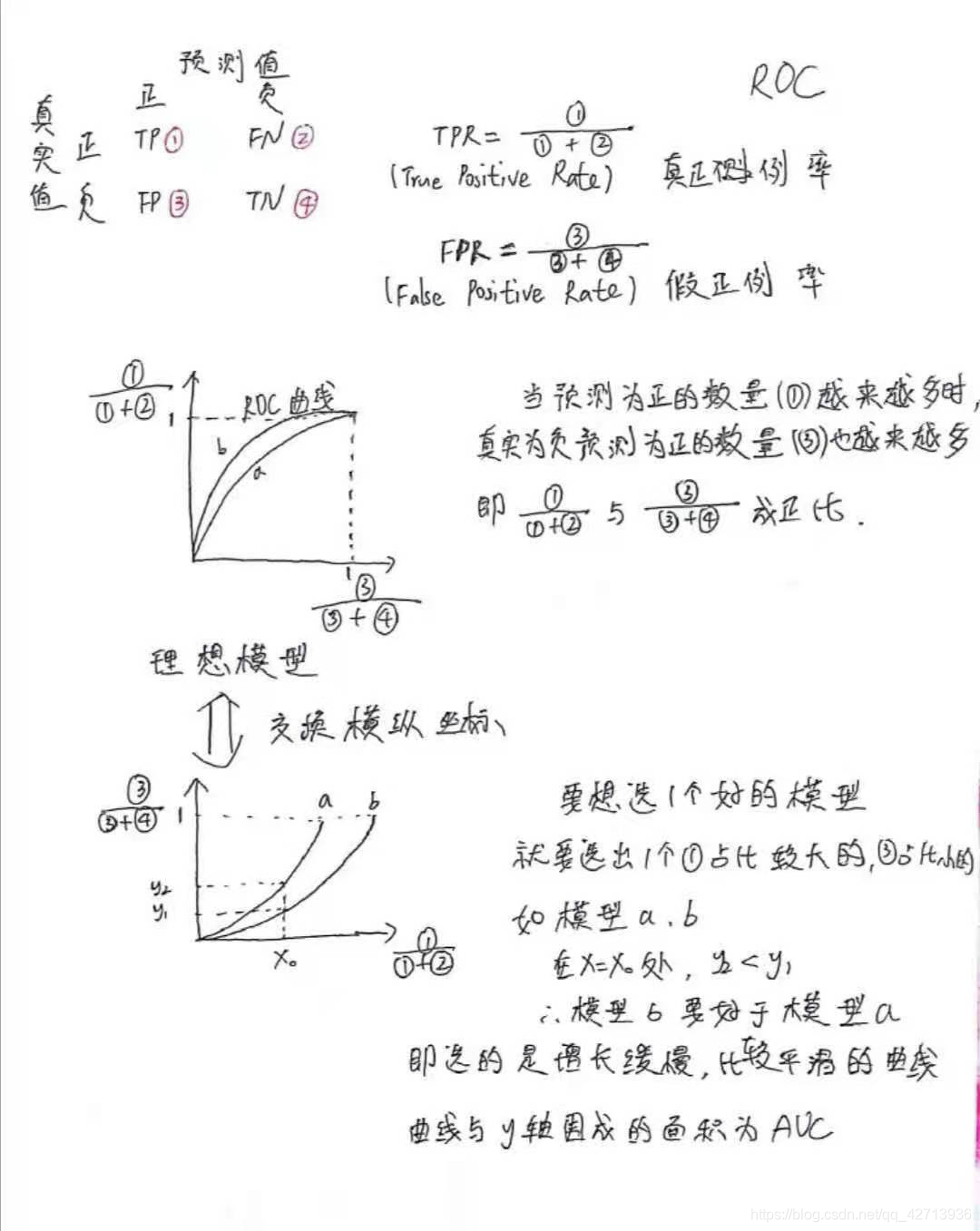
当2条曲线相交时,比较二者孰优孰劣,较为合理的判据是比较ROC曲线下的面积,即AUC(Area Under ROC Curve)

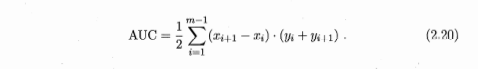
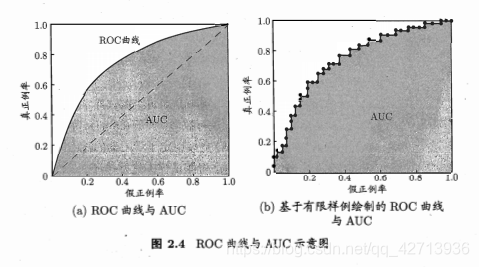
AUC 是上图阴影部分的面积,公式2.20是用微元法求得
(上底+下底)* 高 / 2
(yi + yi+1)* (xi+1 -xi) / 2
排序损失rank-loss(0216)

+ :正例
-:反例
D+ :所有正例的集合
D- :所有反例的集合
m+ :正例的个数
m- :反例的个数
以下图手写数字为例,
+:=5的-:!=5的- D+ :所有 =5 的图片的集合
- D- :所有 !=5 的图片集合
- m+ :正例的个数,6个
- m- :反例的个数,6个
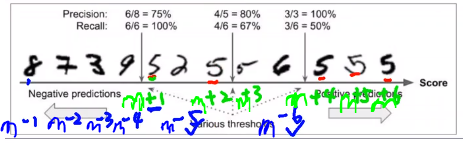
横轴score是给每个图片打的分,越向右分数越大
依次给每个正例编号 m+i ,每个反例编号 m-i
然后依次看
- m-i 中有几个的score比m+1 大 ,此时m-5 、m-6 符合条件,有2个
- m-i 中有几个的score比m+2 大 ,此时m-6 符合条件,有1个
- m-i 中有几个的score比m+3 大 ,此时m-6 符合条件,有1个
- m-i 中有几个的score比m+4 大 ,有0个
- m-i 中有几个的score比m+5 大 ,有0个
- m-i 中有几个的score比m+6 大 ,有0个
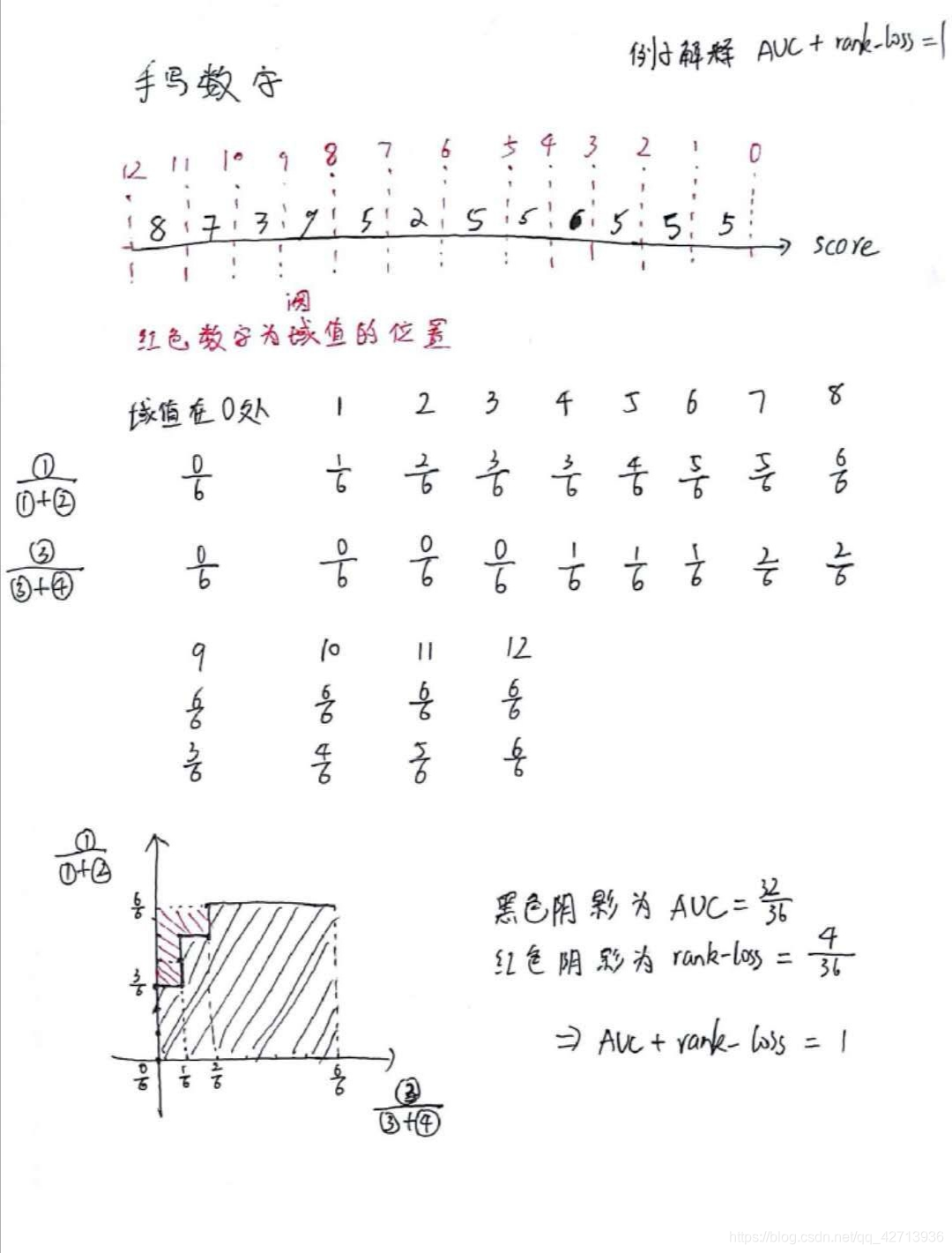
rank-loss=(2+1+1+0+0+0)/(m+ * m-)=4/(6*6)=4/36
AUC与rank-loss(0217)

2.3.4 代价敏感错误率与代价曲线(未完待续)
代价敏感曲线引入(0218)
不同类型的错误造成的后果不同,为权衡不同类型错误所造成的不同损失,可将错误赋 非均等代价(unequal cost)
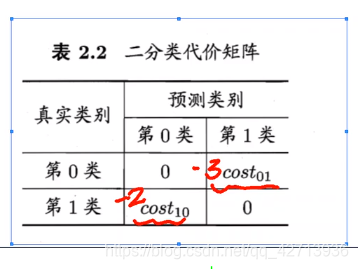
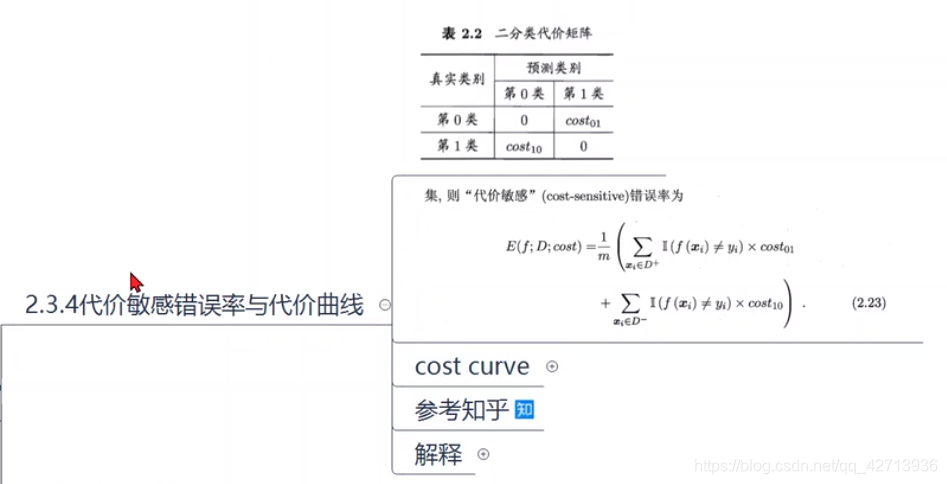
上图二分类的代价矩阵中
- costij 表示将第 i 类样本预测为第 j 类样本的代价
- 一般来说,costij =0
- 若将第0类判别为第1类所造成的损失更大,则 cost01 > cost10
- 损失程度相差约达,cost01 和 cost10值差别越大
之前的错误率是直接计算错误次数,没有考虑不同错误造成的不同后果



代价曲线思路(0219)
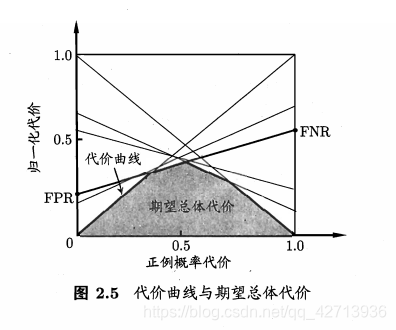
可以参考知乎-机器学习(周志华)第2.3.4节中,代价曲线的理解?
2021/2/19 没看完,决定先跳过