Kafka--介绍
其他
2021-03-01 16:52:03
阅读次数: 0
- 诞生于领英公司
- 最开始是为了处理海量的实时日志数据并做处理分析
- 然后就开发设计了用来处理实时数据,并可以做到高吞吐,可扩展,高性能的分布式消息系统—Kafka
- 2010 年, Kafka 项目被托管到Github 开源社区
- 2011 年, Kafka 成为Apache 项目基金会的一个开源项目。
- 2012 年, Apache 项目基金会开始对Kafka 项目进行孵化。
- 之后,不断有Linkedln 员工和社区成员来维护和改善Kafka 项目, Kafka项目得到持续不断地改进。
- 如今, Kafka 项目成为Apache 项目基金会的顶级项目之一。

Kafka官方介绍
- l 官网:
- l 官方文档
- 官方介绍:
- Kafka®用于构建实时数据管道和流式应用程序。它具有横向可扩展性、容错性、速度极快,在数千家公司的生产中运行。
- 注意:Kafka新版本推出了KafkaStream 然后就改变了Kafka的定位,不再简简单单是一个消息中间件了, 而是定位于一个流式数据处理平台
- 野心比较大
- 但是目前开发中还是把Kafka当作一个消息中间件来用
Kafka设计初衷
- Kafka 雏形由LinkedIn 开发,设计之初被LinkedIn 用来处理活动流数据和运营数据。
- 活动流数据,是指浏览器访问记录、页面搜索记录、查看网页详细记录等站点内容。
- 运营数据,是指服务器的基本指标,例如CPU 、磁盘I/O 、网络、内存等。
- 在后续版本迭代中, Kafka 被设计成一个统一的平台,可用来处理大公司所有的实时数据。需要它能够满足以下需求。
1.高吞吐量
- 日常生活中所使用的支付宝、微信、QQ 这类软件的用户量非常庞大,每秒产生的数据流量也非常巨大。面对这类场景,若要实时地聚合消息日志,必须具有高吞吐量才能支持高容量事件流。
2.高可用队列
- 分布式消息队列系统都具有异步处理机制。另外,分布式消息队列系统一般都拥有处理大量数据积压能力, 以便支持其他离线系统的定期数据加载。
3.低延时
- 实时应用场景对时延的要求极为严格。耗时越少,则结果越理想。这意味着,设计出来的系统必须拥有
低延迟处理能力。
4.分布式机制
- 系统还需具有支持
分区、分布式、能实时处理消息等特点,井能在机器出现故障时保证数据不丢失。
- 为满足这些需求, Kafka 拥有了许多独特的特性,这使得它更类似于数据库日志,而不是传统的消息传递系统。
Kafka应用场景
- 在实际的使用场景中, Kafka 有着广泛的应用。例如,日志收集、消息系统、活动追踪、运营指标、流式处理、事件源等。
1.日志收集
- 在实际工作中, 系统和应用程序都会产生大量的日志。为了方便管理这些日志,可以利用Kafka 将这些零散的日志收集到Kafka 集群中,然后通过Kafka 的统一接口将这些数据开放给不同的消费者(Consumer) 。统一接口包括: Hadoop 的应用接口、HBase 的应用接口、ElasticSearch的应用接口等。
2.消息系统
- 线上业务流量很大的应用,可以使用Kafka 作为缓冲, 以减少服务端的压力。这样能够有效地解耦生产者(Producer)和消费者(Consumer),以及缓冲消息数据。
3.用户轨迹
- 可使用Kafka 记录浏览器用户或者手机App 用户产生的各种记录,例如浏览的网页、搜索的内容、点击的内容等。
- 这些用户活动信息会被服务器收集到Kafka 集群中进行存储,然后消费者通过“消费”这些活动数据来做实时分析,或者加载到Hive 数据仓库做离线数据分析与挖掘。
4.记录运营监控数据
- Kafka 也可用来记录运营监控数据,包括收集各种分布式应用系统的数据(如Hadoop 系统、Hive 系统、HBase 系统等)。
5.实现流处理
- Kafka 是一个流处理平台,所以在实际应用场景中也会与其他大数据套件结合使用,例如Spark Streaming 、Storm 、Flink 等。
6.事件源
- 事件源是一种应用程序的设计风格,其中状态更改会产生一条带有时间戳的记录,然后将这条以时间序列产生的记录进行保存。在面对非常大的存储数据时,可以使用这种方式来构建非常优秀的后端程序。
Kafka在大数据项目中的位置
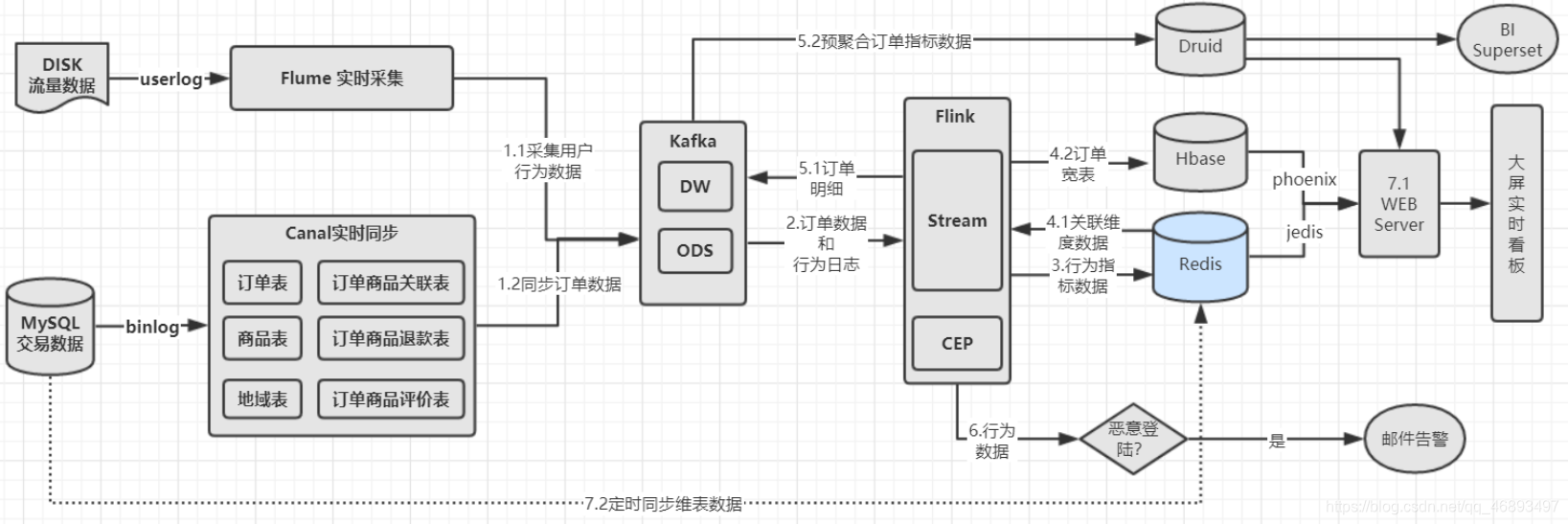
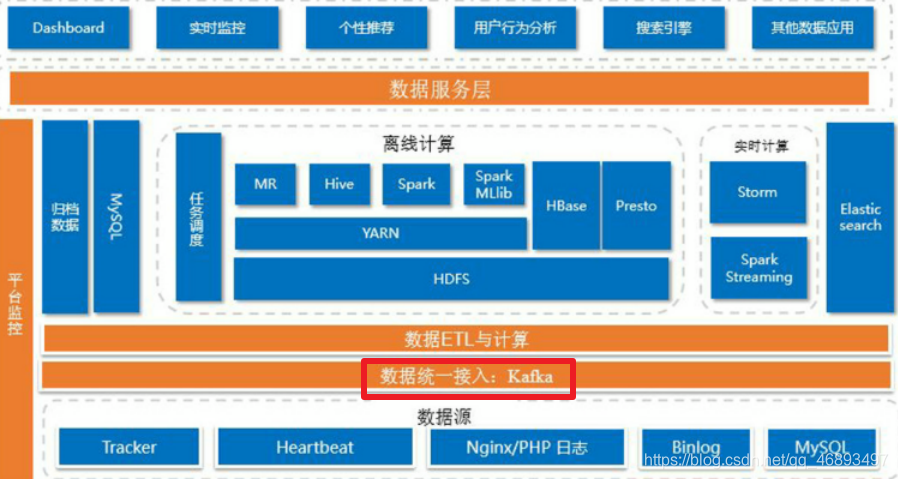
- 90%以上的大数据实时项目都会用到!
- 如下图:Kafka在项目中一般都是用作"消息中转站"
转载自blog.csdn.net/qq_46893497/article/details/114177607