原理加强
生产过程分析
-
1.client客户端连接任意一台活着的KafkaBroker,就可以连接上Kafka集群,并且可以获取到集群的元数据信息
-
2.producer生产者
将消息打包调用send方法,开启sender线程异步将消息推送给Kafka的指定主题 -
3.消息到达Kafka后具体落到哪个分区,
由代码producer代码中的分区器决定- 分区器可以使用自定义分区制定分区规则,也可以使用DefaultPartitioner默认分区器中的规则
- 默认的分区策略:
- 如果在record记录对象中
指定了分区,那么就会使用该分区 - 如果没有指定分区,但存在key,则根据
key的 哈希值 % 分区数 得到分区编号;如果key一样都到一个分区.所以如果使用key作为分区依据,那么key应该要不一样 - 如果
没有分区或key,则以循环/轮询方式选择分区
- 如果在record记录对象中
-
4.分区的目的是为了
提高并发读写和增加集群的可扩展性(后续可以加分区/加机器提高集群性能…) -
5.分区会有副本,
副本的作用是为了提高数据的安全性- 副本分为
Leader主副本---负责读写, Follower从副本--只负责备份
- 副本分为
-
6.如何确认消息发送成功?–使用
acks消息确认应答机制acks=0:表示只要发出去就认为发送成功,可能会有数据丢失,一般不用,除非对性能要求特别高,且不在乎数据丢失acks=1:表示只要leaader收到就认为发送成功,开发中可以使用,但是如果对于数据安全要求还是较高,该配置不适合acks=-1/all:表示所有的ISR副本(Leader+Follower)都收到才认为发送成功,也就是必须等到Follower把数据从Leader上同步过来得了
-
7.消息的有序性:
Kafka只保证从同一个分区消费的消息,是按照offset,有序的, 不保证多个分区间有序
Broker存储机制分析
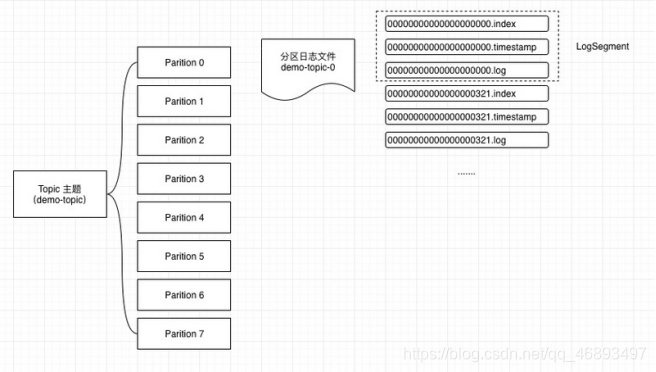
- 1.消息到达Kafka会根据指定的主题和使用的分区策略,然后进入到不同的文件夹中
主题和分区的体现都是不同机器的不同的文件夹
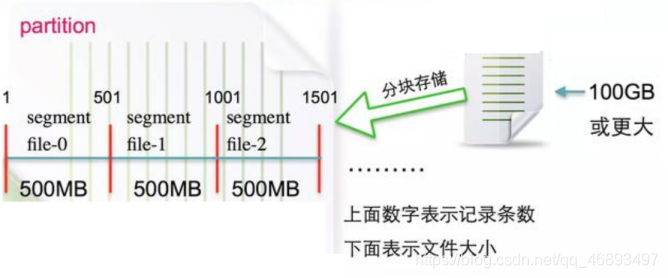
- 2.当某个主题的某个分区的文件夹下的文件太大了,就
会生成新的segment分段文件,目的也是为了提高后续的读效率,注意: 消息添加到segment分段文件是追加进去的, 也就是顺序写 - 3.
消息日志文件不是一直存储的,可以根据配置的策略进行自动删除- 1)基于
时间:log.retention.hours=168 ----默认的7天 - 2)基于
大小:log.retention.bytes=1073741824 ----单个大小达到1G 就删除
- 1)基于
- 4.如果数据足够多, 新来一个消费者要从指定的offset去消费消息,该如何寻找?
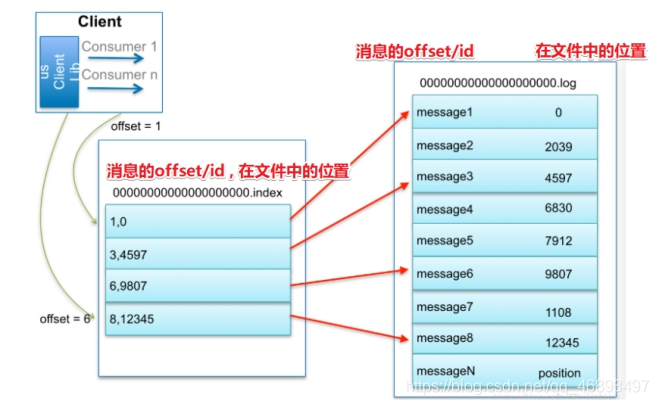
- 比如:要查找绝对offset为7的Message:
- 首先是用
二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。 - 然后打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
- 最后打开数据文件(.log),从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
- 这套机制是
建立在offset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。 - 一句话,
Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性。
- 首先是用
- 5.部分元数据在ZK中的存储
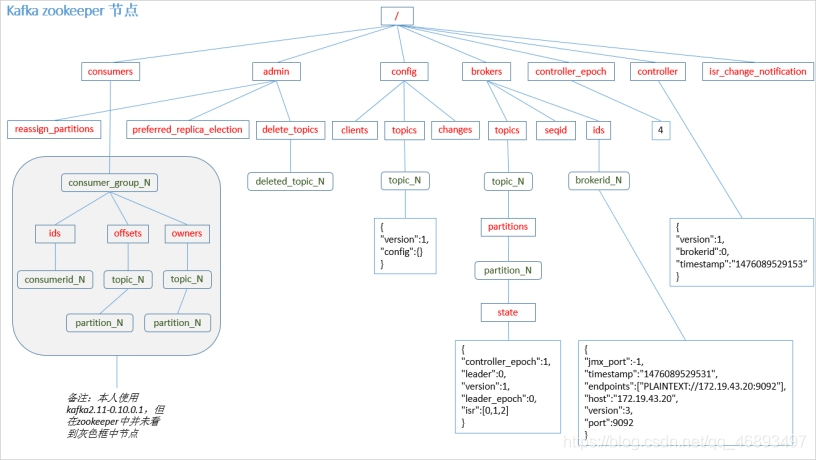
消费过程分析
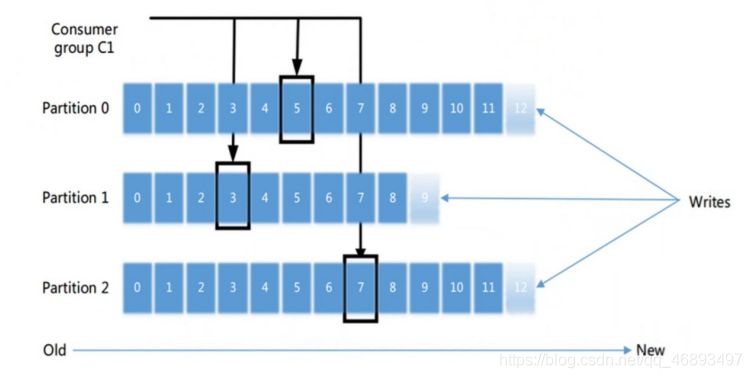
- 1.consumer只要连接任意一台KafkaBroker就可以连接上Kafka集群,然后根据订阅的主题/分区,去相应的文件夹下消费消息
- 2.消息有很多,从哪一条开始消费呢?–由auto.offset.reset参数决定
- 1.
earliest:当各分区下有已提交的 Offset 时,从提交的 Offset开始消费;无提交的Offset 时,从头开始消费; - 2.
latest: 当各分区下有已提交的 Offset 时,从提交的 Offset 开始消费;无提交的 Offset时,消费新产生的该分区下的数据 - 3.
none: Topic 各分区都存在已提交的 Offset 时,从 Offset 后开始消费;只要有一个分区不存在已提交的 Offset,则抛出异常。
- 1.
- 3.消费完如何提交?–由enable.auto.commit参数决定
- true:自动提交, 老版消费者,提交到ZK, 新版提交到默认主题 __ consumer __ offsets
- false:手动提交,consumer.commitAsync();//异步提交 和consumer.commitSync();//同步提交
- 4.了解–手动提交时可以根据业务自己决定如何提交
//准备一个集合,存放消费到的数据,集合的size大于一定数量的时候,也就是积攒到一批的时候,才提交偏移量
ArrayList<ConsumerRecord<String, String>> list = new ArrayList();
while (true){
ConsumerRecords<String, String> records = consumer.poll(100);
//如果这一次拉取消费有数据,那么消费完应该要手动提交偏移量,如果没有拉取到消息,那么没必要提交
//如果这一次只消费到了一条数据,也提交吗?有点性能浪费,我们可以积攒到一批再提交
//当然可以根据实际业务需求来
//那么我们这里演示有数据,且积攒了一批数据再提交
for (ConsumerRecord<String, String> record : records) {
System.out.println("分区:"+record.partition()+" 偏移量:"+record.offset()+" key:"+record.key()+" value:"+record.value());
list.add(record);
}
//TODO 5.手动提交偏移量
//经过上面的循环,list中就有了一批数据,如果list.size>5,就提交偏移量
if (list.size() > 5){
System.out.println("list.size>5偏移量已经提交");
consumer.commitAsync();//异步提交
//consumer.commitSync();//同步提交
//提交完这一批,情况list,重新累计
list.clear();
}
}
try {
while(running) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() -1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
}
- 注意事项:
- 提交的偏移量应始终是应用程序将读取的下一条消息的偏移量。
- 因此,在调用commitSync(偏移量)时,应该 在最后处理的消息的偏移量中添加一个
- 5.了解-可以订阅主题进行消费,也可以订阅主题的指定分区进行消费
//TODO 3.订阅主题
//consumer.subscribe(Arrays.asList("foo"));
//TODO 3.订阅主题的部分分区
//手动指定 消费指定分区的数据---start
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
//手动指定 消费指定分区的数据---end
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records){
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
//subscribe方法和assign方法只能选一个
- 6.消费者归属于消费者组,
一个消费者组中可以有1~n个消费者,如果在创建的时候不指定消费者组,那么会自动分配一个消费组名称,但是不方便后续管理,所以最好还是指定!
总结
