为什么Kafka新版本API将offset提交到默认主题,而不是ZK
- 1.Kafka野心很大,他
想逐步摆脱对其他框架的依赖,所以新版本中不再把offset提交ZK - 2.
如果把offset提交到zk,当消费者很多的时候,每次消费都得提交,会导致zk压力多大 zk不适合频繁写
为什么需要消费者组?
-
1.消费者组可以
方便对于消费者的管理–分组管理 -
2.
提高并发、可扩展、高容错的消费者机制 -
如下图:
- 不使用消费者组/或者组里只有一个消费者时消费者压力大
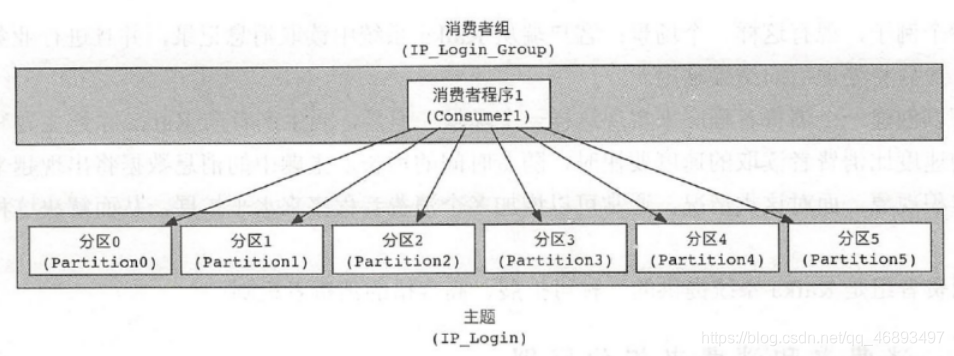
- 再或者消费者数量 < 分区数量,消费者压力还是大
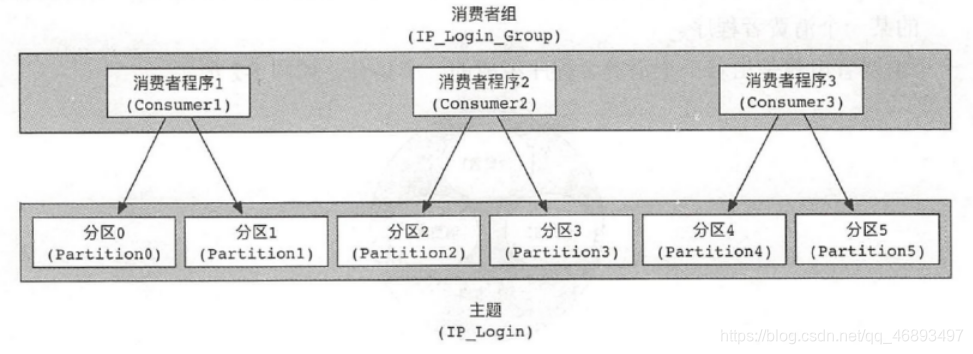
- 消费者数量 = 分区数量 ,消费者压力正好,干活不累
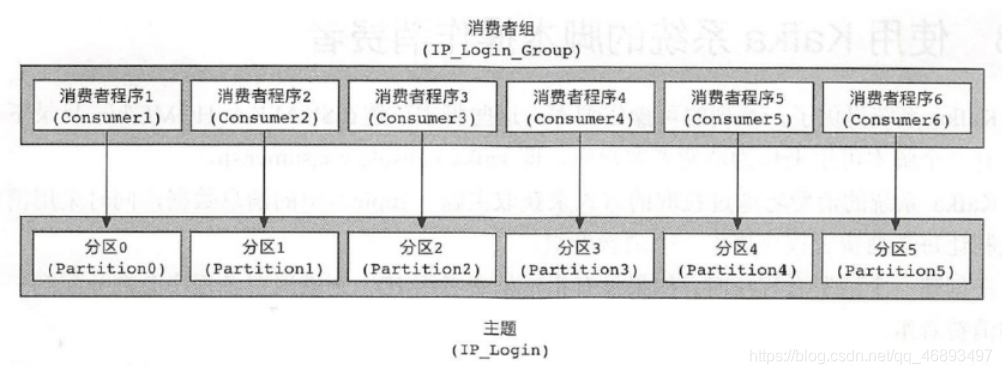
- 消费者数量 > 分区数量 ,会有消费者空闲,存在资源浪费!
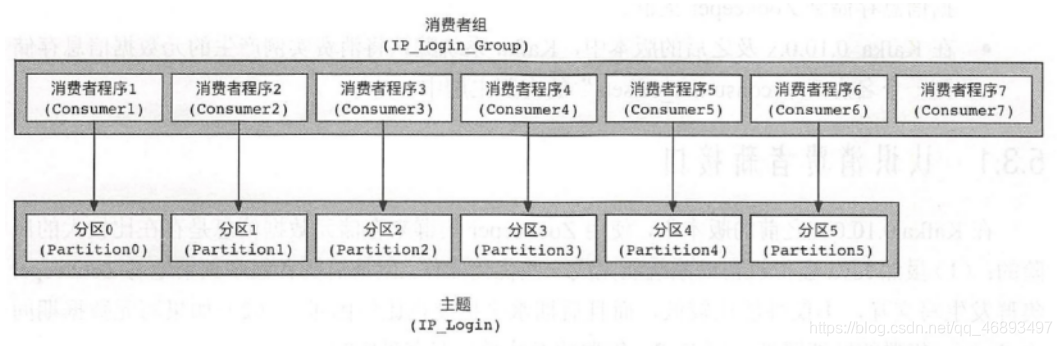
- 不使用消费者组/或者组里只有一个消费者时消费者压力大
-
总结:
- 消费者组,可以
方便我们对于消费者进行分组管理,也可以通过增加组内消费者提高消费者能力 - 但是,需要注意: 开发时建议消费者组内的
消费者线程数=分区数, 这样既可以提高消费效率,也不会浪费资源
- 消费者组,可以
为什消费者数量 > 分区数量 ,会有消费者空闲?
- 因为,消费者和分区数一一对应的时候,消费消息记录偏移量都比较方便
- 如果同一时刻有多个同属于同一个消费者组的消费者消费同一个分区的消息,会导致offset维护困难
- 也就是说:
- Kafka不允许同一个消费者组内的多个消费者同时消费同一个分区!
- 如:
- A组的1号线程消费者消费test主题的0分区
- 那么就不再允许A组的2号线程消费者消费test主题的0分区
- 但是允许 不同的消费者组中的多个消费者消费同一个分区
- 如
- A组中的一个消费者线程消费test主题的0分区
- B中的中的一个消费者线程也消费test主题的0分区
- 这是允许的
Kafka为什么那么快
- 1.Kafka最开始的架构设计就考虑到了分布式高并发高吞吐,所以设计了很多的细节来实现该目标
- 如:
- 1.
分区/分段可以提高并发, - 2.
消息发送时是推, 消费时是拉, 也就是让生产者和消费者自己去做,而不是Kafka去找生产者要消息,也不是Kafka把消息发给消费者,所以Kafka整个集群压力不是很大,就给他的其他方面节省了性能
- 1.
- 2.底层实现上面也有很多设计的巧妙之处–扩展的
- 1.
Sequence I/O将消息顺序写入磁盘(追加到segment分段文件) - 2.充分利用操作系统的
PageCache(页缓存),如果生产者消费者速度类似,直接使用内存即可(当然之后还是会在磁盘存一份防止还有其他消费者组来订阅) - 3.
零拷贝技术(Sendfile),直接在内核区完成数据拷贝
- 1.
kafka如何保证数据的不丢失
生产者
消息确认机制–表示是否发送成功0:表示只要发出去就认为发送成功,可能会有数据丢失,一般不用,除非对性能要求特别高,且不在乎数据丢失1:表示只要leaader收到就认为发送成功,开发中可以使用,但是如果对于数据安全要求还是较高,该配置不适合-1/all:表示所有的ISR副本(Leader+Follower)都收到才认为发送成功,也就是必须等到Follower把数据从Leader上同步过来得了- 一般使用1表示leader接受认为就成功了, 数据确实进入到kafka了,已经安全了
- 如果要求更高可以使用-1也就是all,所有主从副本都收到才认为成功,觉得安全
- 如果是同步
- 配置如下
producer.type=syncrequest.required.acks=1或-1
- 如果是异步
producer.type=async request.required.acks=1 或-1queue.enqueue.timeout.ms = -1 (-1表示消息会一直在缓冲区直到被发送到Kafka)
broker
- 副本
消费者
- 用
offset维护记录消息消费到哪里了,下次接着消费
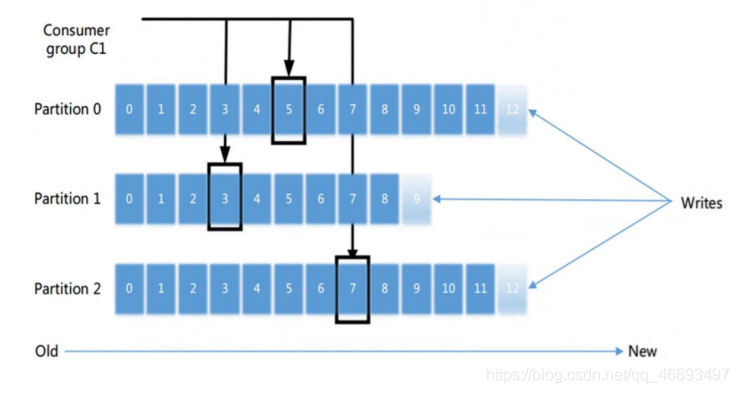
offset什么时候提交?
- 1.
先提交再消费–提交完立马挂了,没来得及消费,那么下次接着消费就会少消费上次提交的那条—所以不用 - 2.
消费完再提交–消费了再提交就能保证消息不丢,但是会重复消费,如已经消费了,但没来得及提交,那么下次又会重复消费这条消息!
Kafka如何避免重复消费
- 一般会
在消费完再去改偏移量,这样可以保证消息不会丢失/漏掉,对于可能重复消费,可以使用以下办法: - (1)
去重:将消息的唯一标识保存到外部介质中(Redis)或者搞个集合,每次消费处理时判断是否处理过;–会耗性能 - (2)
不管:大数据场景中,报表系统或者日志信息多或者少几条都无所谓,不会影响最终的统计分析结果(金融相关除外)
如何保证消息消费有序
- 我们前面说过
Kafka只能保证消息区内有序,不保证同时消费多个分区,出来的数据也有序 - 那么如果非得要求发送123,消费出来也是123,那就
只能用一个分区!但是又违背kafka通过分区提高并发的初衷 - 所以这个面试题仅仅是面试官为难你而已,上面那样回答即可
CAP定理和Kafka的CAP
- C:数据一致性:
更新数据后,并发访问情况下后续读操作可以立即感知该更新------很多分布式系统都追求的 - A:服务可用性:
集群中的一个或者某个节点挂掉,仍然可以提供服务------很多分布式系统都追求的 P:分区容错性:集群内部出现通信故障,服务A的数据没法同步到其他节点时,客户端访问服务A,服务A仍然能返回未同步到其他节点的数据------很多分布式系统都追求的- 但是很可惜,上面的CAP已经被科学家证明不能完全同时满足!
- 1988年,加州大学计算机科学家Eric Brewer 提出了分布式系统的三大指标:Consistency、Availability、Partition Tolerance,他指出这三个条件同时最多只能满足两个,目前所有的分布式系统都遵循CAP定律,比如Hadoop、HBASE、Redis集群、es、kafka等都只能同时满足其中的两个!
那么我们的Kafka满足哪2个呢?
kafka满足的是CAP定律当中的CA,其中Partition tolerance通过的是一定的机制尽量的保证分区容错性。其中C表示的是数据一致性。A表示数据可用性。- kafka首先将数据写入到不同的分区里面去,每个分区又可能有好多个副本,数据首先写入到leader分区里面去,
读写的操作都是与leader分区进行通信,保证了数据的一致性原则,也就是满足了Consistency原则。然后kafka通过分区副本机制,来保证了kafka当中数据的可用性。 - 但是也存在另外一个问题,就是Follower副本分区当中的数据与leader当中的数据存在差别的问题如何解决,这个就是Partition tolerance的问题。kafka为了解决Partition tolerance的问题,使用了ISR的同步策略,来尽最大可能减少Partition tolerance的问题每个leader会维护一个ISR(a set of in-sync replicas,基本同步)列表
ISR列表主要的作用就是决定哪些副本分区是可用的,也就是说可以将leader分区里面的数据同步到副本分区里面去,决定一个副本分区是否可用的条件有两个- 1.replica.lag.time.max.ms=10000
副本分区与主分区心跳时间延迟 - 2.replica.lag.max.messages=4000
副本分区与主分区消息同步最大差
- 1.replica.lag.time.max.ms=10000
HDFS保证强一致性C和分区容错性P,降低了可用性AHBase基于HDFS那么也是CPRedis CP