前言
最近在学习如何从零实现一个完整的实时数仓项目,便自己想了一个需求练练手。模拟词典工具的PV统计,每个用户查询一次单词便记录到日志,实时统计前5分钟查询的人数。
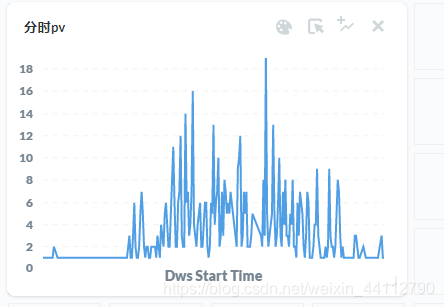
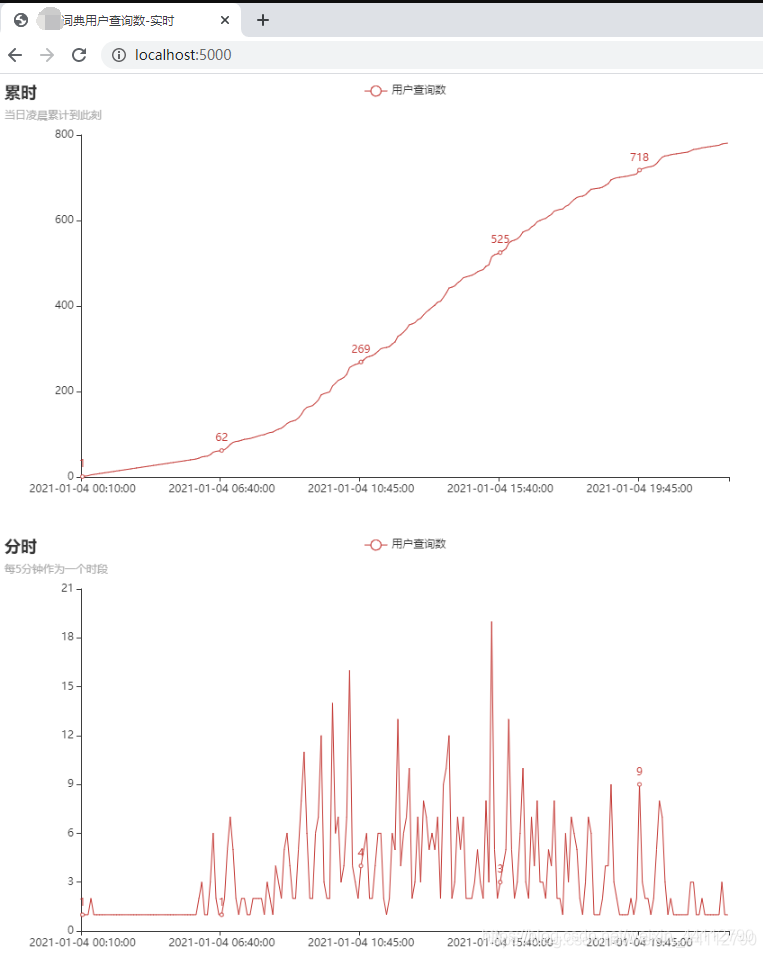
大概的效果如下,需要注意,生产环境中,这个图在不断更新最近五分钟的数据。也就是说,12点的时候只能看到当天12点前的数据,下面这张图是接近24点才能看到的数据。
要做这个项目练手的话,首先要解决数据的问题。为了数据看上去合理一些,夜间低,白天高,我一次生成了全天的数据。
import time
import random
from random_words import RandomWords
def gen(rank):
# 先确认每个小时的查询数目,里面的数都是随机生成的,没有什么特殊含义
query_nums = []
for h in range(0, 6):
query_nums.append(random.randint(1, 10) * rank) # 0点到6点的比较少
for h in range(6, 12):
query_nums.append(random.randint(h * 2, h * 3) * rank) # 6点到12点的逐渐增多
for h in range(12, 24):
query_nums.append(random.randint((24 - h) * 2, (24 - h) * 3) * rank) # 12点到24点逐渐减少
print("每小时访问数"+str(query_nums))
print("总访问数:"+str(sum(query_nums)))
rw = RandomWords() # 用于随机生成一个单词
terminals = ["pc", "android", "iphone"] # 终端,可以分析维度
zero_ts = time.mktime(time.strptime("2021-01-04 00:00:00", "%Y-%m-%d %H:%M:%S")) # 时间戳的起点
res = []
for hour in range(24):
for cnt in range(0, query_nums[hour]): # 生成每小时的具体访问记录
user_id = random.randint(50, 100)
word = rw.random_word()
terminal = terminals[random.randint(0, 2)]
ts = str(int(zero_ts) + hour * 3600 + random.randint(0, 3600))
res.append((str(user_id), word, terminal,ts))
res.sort(key=lambda x: x[3]) # 按时间戳排序
# 写入文件
with open("./user_word.log", mode="w", encoding="utf-8") as f:
for r in res:
f.write(",".join(r) + "\n")
def check():
# 查看生成数据的情况
with open("./user_word_3k+.log", mode="r", encoding="utf-8") as f:
for line in f:
strs = line.split(",")
dt = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(strs[3])))
print(line.strip("\n")+","+dt)
if __name__ == '__main__':
gen(10) # rank用来控制生成数据的量级,10大概是3.5k条,100大概是3.5w条
# check()
下面是三千多条的情况,隔两三分钟差不多有一条数据(三万多条的话,差不多每分钟都有访问)

代码
Flume
flume动态的监测着另一个文件,将刚刚生成的数据缓慢的一条条追加到kafka。
这些数据不能直接cat到kafka,而是按照他对应的小时和分钟一点点交给kafka。因为kafka不保证数据的有序性,如果一次全部提交这么多数据,flink的窗口会漏掉不少数据。
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F -c +0 /home/bduser/user_word_demo/user_word_steam.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a2.sinks.k2.brokerList = node102:9092
a2.sinks.k2.topic = flink_test
a2.sinks.k2.serializer.class=kafka.serializer.StringEncoder
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
Kafka
我这里使用的是0.11.3版本,命令行有较大不同,创建topic就行,
bin/kafka-topics.sh --create --zookeeper localhost:2181 --partitions 1 --replication-factor 1 --topic dwd_user_word_stream
bin/kafka-topics.sh --create --zookeeper localhost:2181 --partitions 1 --replication-factor 1 --topic dws_user_word_5mins
也可以通过控制台测试一下topic能否正常使用
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dwd_user_word_stream
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic dwd_user_word_stream--from-beginning
Flink
maven依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-core -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-csv -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!--https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-scala-bridge-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.40</version>
</dependency>
</dependencies>
<build>
<!-- <finalName>WordCount</finalName>-->
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<archive>
<manifest>
<mainClass>Dwd2Dws</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
dwd到dws的代码,需要修改当中Zookeeper和Kafka的连接信息

package org.nefu
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.{DataTypes, EnvironmentSettings}
import org.apache.flink.table.api.scala._
import org.apache.flink.api.scala._
import org.apache.flink.table.descriptors.{Csv, Kafka, Schema}
import org.apache.flink.types.Row
object Dwd2Dws {
def main(args: Array[String]): Unit = {
/***环境准备***/
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val bsSettings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val bsTableEnv = StreamTableEnvironment.create(env, bsSettings)
/***输入***/
bsTableEnv.sqlUpdate(
"""
|CREATE TABLE dwd_user_word_stream (
| userId STRING,
| word STRING,
| terminal STRING,
| queryTimestamp BIGINT,
| dwsStartTime AS TO_TIMESTAMP(FROM_UNIXTIME(queryTimestamp)),
| WATERMARK FOR dwsStartTime AS dwsStartTime - INTERVAL '1' MINUTE
|) WITH (
| 'connector.type' = 'kafka',
| 'connector.version' = '0.11',
| 'connector.topic' = 'dwd_user_word_stream',
| 'connector.properties.zookeeper.connect' = 'localhost:2181',
| 'connector.properties.bootstrap.servers' = 'localhost:9092',
| 'format.type' = 'csv'
|)
""".stripMargin)
/***窗口聚合计算***/
val dataTable = bsTableEnv.sqlQuery(
"""
|SELECT userId, word, FIRST_VALUE(terminal),COUNT(queryTimestamp),TUMBLE_START(dwsStartTime, INTERVAL '5' MINUTE)
|FROM dwd_user_word_stream
|GROUP BY TUMBLE(dwsStartTime, INTERVAL '5' MINUTE), userId, word
""".stripMargin)
/***输出结果***/
dataTable.toAppendStream[Row].print()
bsTableEnv.connect(new Kafka()
.version("0.11")
.topic("dws_user_word_5mins")
.property("zookeeper.connect", "localhost:2181")
.property("bootstrap.servers", "localhost:9092")
).withFormat(new Csv())
.withSchema(new Schema()
.field("userId", DataTypes.STRING())
.field("word", DataTypes.STRING())
.field("terminal", DataTypes.STRING())
.field("cnt", DataTypes.BIGINT())
.field("dwsStartTime", DataTypes.TIMESTAMP(3))
).createTemporaryTable("dws_user_word_5mins")
dataTable.insertInto("dws_user_word_5mins")
/***执行***/
env.execute("Dwd2Dws")
}
}
dws到ads的代码,需要修改当中zookeeper、kakfa和mysql的连接信息
package com.youdao.analysis.demo
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.{DataTypes, EnvironmentSettings}
import org.apache.flink.table.api.scala._
import org.apache.flink.api.scala._
import org.apache.flink.table.descriptors.{Csv, Kafka, Schema}
import org.apache.flink.types.Row
object Dws2Ads {
def main(args: Array[String]): Unit = {
/***环境准备***/
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val bsSettings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val bsTableEnv = StreamTableEnvironment.create(env, bsSettings)
/***输入***/
bsTableEnv.sqlUpdate(
"""
|CREATE TABLE dwd_user_word_stream (
| userId STRING,
| word STRING,
| terminal STRING,
| cnt BIGINT,
| dwsStartTime TIMESTAMP(3),
| WATERMARK FOR dwsStartTime AS dwsStartTime - INTERVAL '1' MINUTE
|) WITH (
| 'connector.type' = 'kafka',
| 'connector.version' = '0.11',
| 'connector.topic' = 'dws_user_word_5mins',
| 'connector.properties.zookeeper.connect' = 'localhost:2181',
| 'connector.properties.bootstrap.servers' = 'localhost:9092',
| 'format.type' = 'csv'
|)
""".stripMargin)
/***窗口聚合计算***/
//user
val userDataTable = bsTableEnv.sqlQuery(
"""
|SELECT userId,FIRST_VALUE(terminal),SUM(cnt),TUMBLE_START(dwsStartTime, INTERVAL '5' MINUTE)
|FROM dwd_user_word_stream
|GROUP BY TUMBLE(dwsStartTime, INTERVAL '5' MINUTE), userId
""".stripMargin)
//word
val wordDataTable = bsTableEnv.sqlQuery(
"""
|SELECT word,SUM(cnt),TUMBLE_START(dwsStartTime, INTERVAL '5' MINUTE)
|FROM dwd_user_word_stream
|GROUP BY TUMBLE(dwsStartTime, INTERVAL '5' MINUTE),word
""".stripMargin)
/***输出结果***/
//user
userDataTable.toAppendStream[Row].print()
bsTableEnv.sqlUpdate(
"""
|CREATE TABLE tb_user_5mins (
| user_id STRING,
| terminal STRING,
| cnt BIGINT,
| dwsStartTime TIMESTAMP(3) -- 支持自动转为mysql中的varchar(255)
|) WITH (
| 'connector.type' = 'jdbc',
| 'connector.url' = 'jdbc:mysql://localhost:3306/db_user_word',
| 'connector.table' = 'tb_user_5mins',
| 'connector.driver' = 'com.mysql.jdbc.Driver',
| 'connector.username' = 'root',
| 'connector.password' = 'root',
| 'connector.write.flush.max-rows' = '2',
| 'connector.write.flush.interval' = '2s')
""".stripMargin)
userDataTable.insertInto("tb_user_5mins")
//word
wordDataTable.toAppendStream[Row].print()
bsTableEnv.sqlUpdate(
"""
|CREATE TABLE tb_word_5mins (
| word STRING,
| cnt BIGINT,
| dwsStartTime TIMESTAMP(3) -- 支持自动转为mysql中的varchar(255)
|) WITH (
| 'connector.type' = 'jdbc',
| 'connector.url' = 'jdbc:mysql://localhost:3306/db_user_word',
| 'connector.table' = 'tb_word_5mins',
| 'connector.driver' = 'com.mysql.jdbc.Driver',
| 'connector.username' = 'root',
| 'connector.password' = 'root',
| 'connector.write.flush.max-rows' = '2',
| 'connector.write.flush.interval' = '2s')
""".stripMargin)
wordDataTable.insertInto("tb_word_5mins")
/***执行***/
env.execute("Dws2Ads")
}
}
打包提交到YARN或者Flink集群
总结
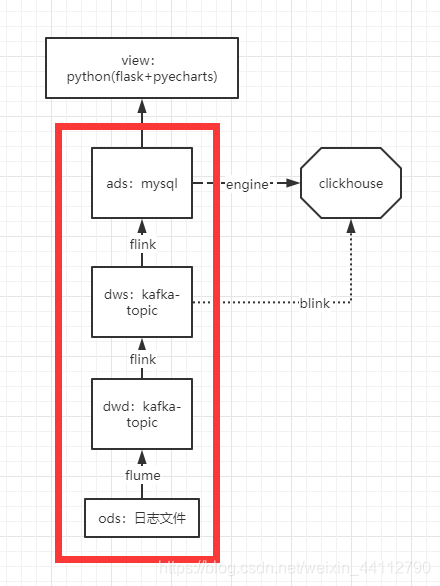
本文给出了项目的核心代码,对应下图红框中的部分。适合已经熟悉Kafka、Flink环境的人尝试,如果没有接触多的话,仅仅靠这些代码是不够的,建议先去搭建好Kafka、Flink的运行环境。
分层的几点注意事项
1.实际的ods日志文件中可能还有登录信息等其他日志,会分主题进入dwd。比如用户查词的进入一个topic,登录信息的进入另一个topic。
2.dwd是按主题划分的明细数据,按一定时间窗口轻度聚合得到dws层。
3.dws层已经聚合了同一个用户单词在5分钟内的访问,并统一了窗口的开始时间(就是想5分钟内一个用户查询的同一个单词聚合到了一起,这样情况可能会出现在查词后误触再重新查询同一个词)
4.ads层分别聚合了用户的数据和单词的数据,以供分析师进行业务分析。
这里用mysql进行的BI报表展示并不是特别合适,如果有条件可以实时ClickHouse
此外,metabase也可用于BI报表展示