在本练习中,您将学习如何使用 Amazon Kinesis 流式传输数据到 Elasticsearch 并进行分析,这是两项完全托管的基于云的服务,用于实时传输大型分布式数据流和查询,分析等。
为了使练习更加贴近实际业务场景,我们将模拟从 EC2 的应用程序中生成交易订单事件。
在此教程中,您将完成以下三个组件的实验:
• 创建Amazon Kinesis Data Stream
• 创建Amazon Kinesis Data Firehose
• 部署Amazon Elasticsearch
本实验的架构图如下:
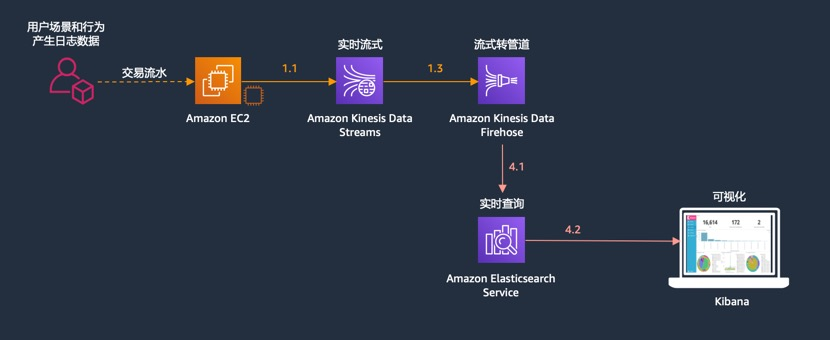
构建宽表
因为 Elasticsearch 最多只支持 2 个表的 Join 查询,而我们的表有 4 个,所以为了更好的在 Elasticsearch 里面使用,我们通过脚本对数据进行了一定的处理,做成了宽表的模式。
准备表数据
登录之前部署的 EC2 客户端,上传这三个文件,放到一个专门的目录下,例如/home/ec2-user/csv下
https://imgs.wzlinux.com/aws/tbl_address.csv
https://imgs.wzlinux.com/aws/tbl_customer.csv
https://imgs.wzlinux.com/aws/tbl_product.csv
[ec2-user@ip-172-31-77-126 csv]$ ll
total 176
-rw-rw-r-- 1 ec2-user ec2-user 91306 Oct 30 09:53 tbl_address.csv
-rw-rw-r-- 1 ec2-user ec2-user 75857 Oct 30 09:53 tbl_customer.csv
-rw-rw-r-- 1 ec2-user ec2-user 6552 Oct 30 09:53 tbl_product.csv加载进入缓存
登录之前部署的 EC2 客户端,上传这三个文件,跟上一步的三个 csv 文件放到一个目录下
https://imgs.wzlinux.com/aws/rds_address.sh
https://imgs.wzlinux.com/aws/rds_customer.sh
https://imgs.wzlinux.com/aws/rds_product.sh
启动 redis 服务,安装 unix2dos 工具
sudo amazon-linux-extras install redis4.0 -y
sudo systemctl enable redis
sudo systemctl start redis
sudo yum install dos2unix -y执行如下脚本导入数据到 Redis(确保导入脚本和 csv 文件在同一个目录下)
[ec2-user@ip-172-31-77-126 csv]$ sh rds_address.sh
unix2dos: converting file ./tbl_address.rds to DOS format ...
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 3252
[ec2-user@ip-172-31-77-126 csv]$ sh rds_customer.sh
unix2dos: converting file ./tbl_customer.rds to DOS format ...
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 4336
[ec2-user@ip-172-31-77-126 csv]$ sh rds_product.sh
unix2dos: converting file ./tbl_product.rds to DOS format ...
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 500生成流式数据宽表
登录之前部署的 EC2 客户端,上传这个可执行文件(例如放到根目录下),如果是其他区域,请修改一下脚本。
https://imgs.wzlinux.com/aws/lab4.sh
执行脚本开始灌数据
sh lab4.sh kds-lab4 2021-03-19 &lab4.sh 会往 kds 流里面灌数据,格式为
- tid: 交易id
- tno: 交易编号
- tdate: 交易日期
- uno: 客户编号
- pno: 产品编号
- tnum: 交易数量
- uname: 下单客户的姓名
- umobile: 下单客户的手机号
- ano: 下单配送地址编号
- acity: 下单配送城市
- aname: 下单配送地址
- pclas: 产品类型
- pname: 下单产品名称
- pprice: 单价
- total: 总价(=tnum * pprice)
- tuptime: 时间戳
如下仅供参考
{
"tid": "D123",
"tno": "DwGi20200904131249",
"tdate": "2021-03-19",
"uno": "U1030",
"pno": "P1002",
"tnum": 10,
"uname": "张三",
"umobile": "13800138000",
"ano": "A1001",
"acity": "深圳",
"aname": "福田区**地址",
"pclass": "MOBILE",
"pname": "OPPO-Reno4",
"pprice": 4999,
"total": 4999,
"tuptime": "2021-03-19T13:15:48Z"
}检查 lab4 开头的日志文件输出,看是否运行正常,出现如下所示截图表示正常 表构建完毕后如下图所示

宽表构建完毕,可以开始在Elasticsearch里面开始接受数据并进行实时检索和可视化了。
实时检索和可视化
本实验演示通过 Kinesis Firehose 把流数据通过管道注入 Elasticsearch 实时检索和可视化的过程。
导入数据
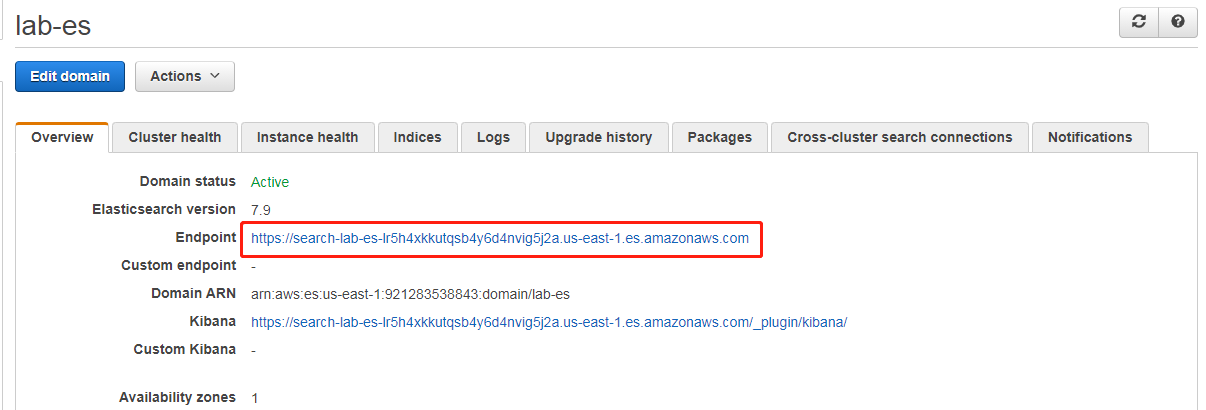
登录并打开 Elasticsearch 控制台,确保 ES 集群状态是有效。
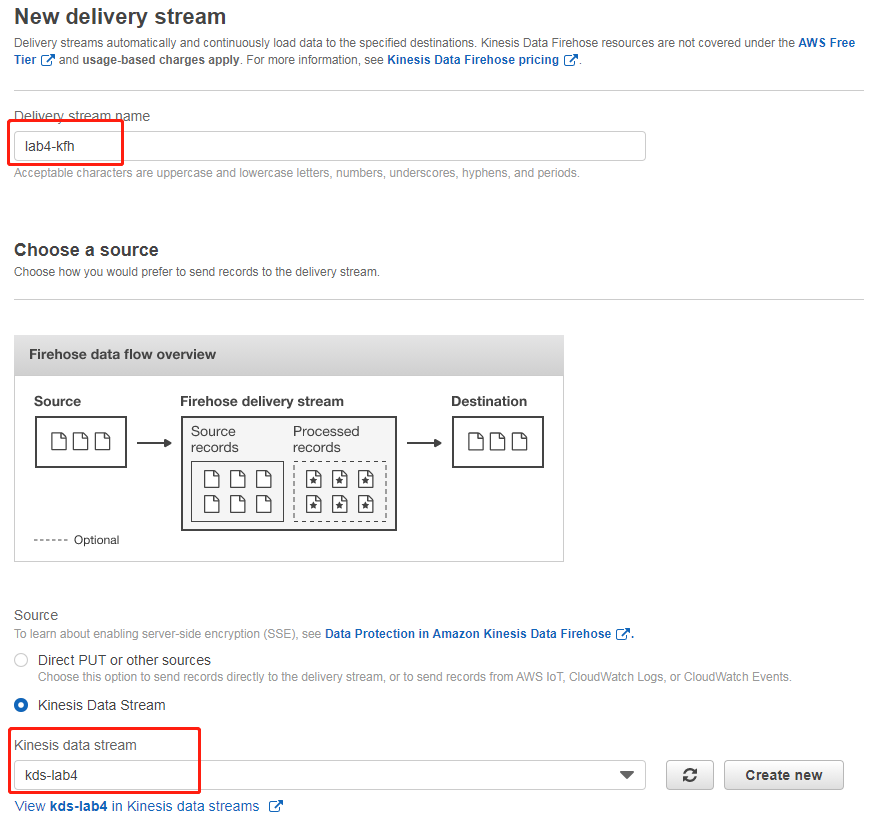
打开 Kinesis Firehose 控制台,选择创建传输流,设置传输流名字“lab4-kfh”,并选择“kds-lab4”为源
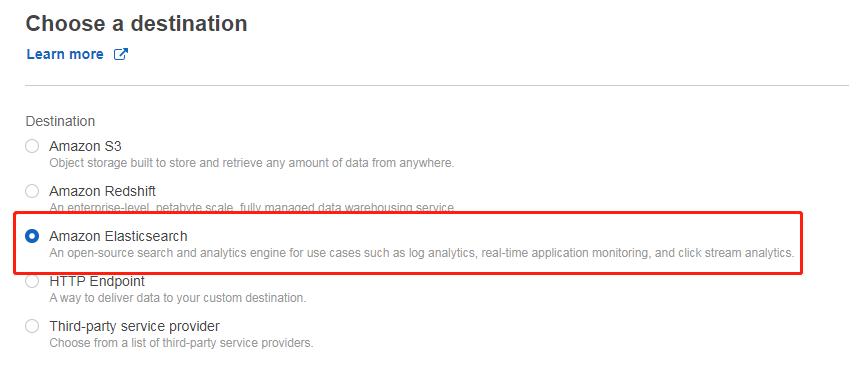
下一步不对记录进行任何处理(选默认值),在下一步的目标里面选择将数据送到 Elasticsearch,并选择我们部署的 ES 集群,以及数据的索引名(此处为 lab4),如下图所示
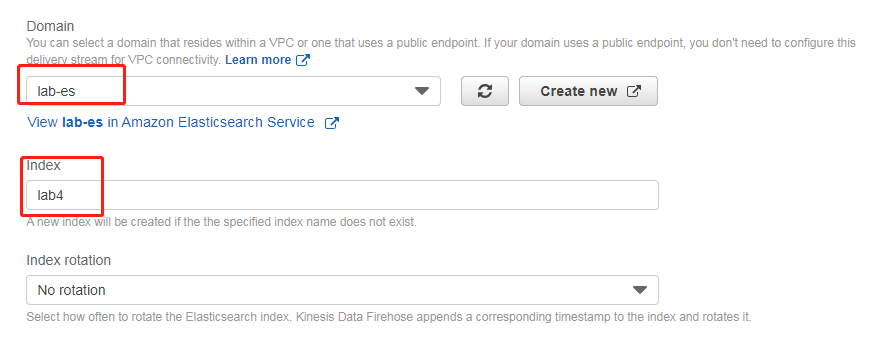
需要配置 S3 转存储一份(或保留发送失败的记录),配置对应桶和路径即可
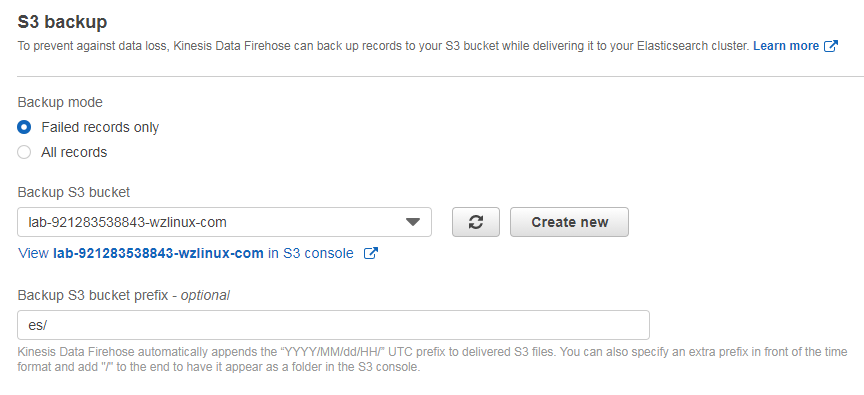
接下来的缓冲区设置为 1M 或者 60 秒即可(其他全部默认)
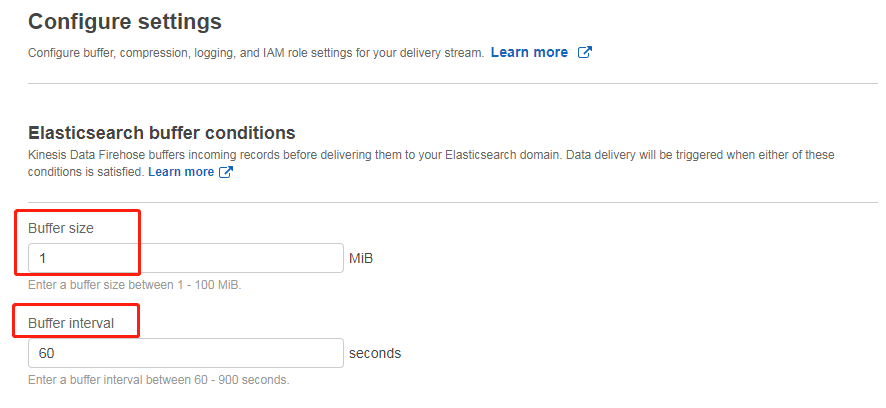
然后选择审核并创建传送流即可,但是此时 KDF 的数据流还没有权限写入 ES,因为 ES 开启了精细访问控制,我们需要登陆到 Kibana 为 KDF 的 Role 加上对 ES 的访问权限。
登录 ES 集群添加权限
在我们这里,Kibana 地址为如下,输入我们创建集群时添加的 master 账户认证即可。
https://search-lab-es-lr5h4xkkutqsb4y6d4nvig5j2a.us-east-1.es.amazonaws.com/_plugin/kibana/登录 Elasticsearch 集群后,打开安全-角色,我们就选择这个最高权限。
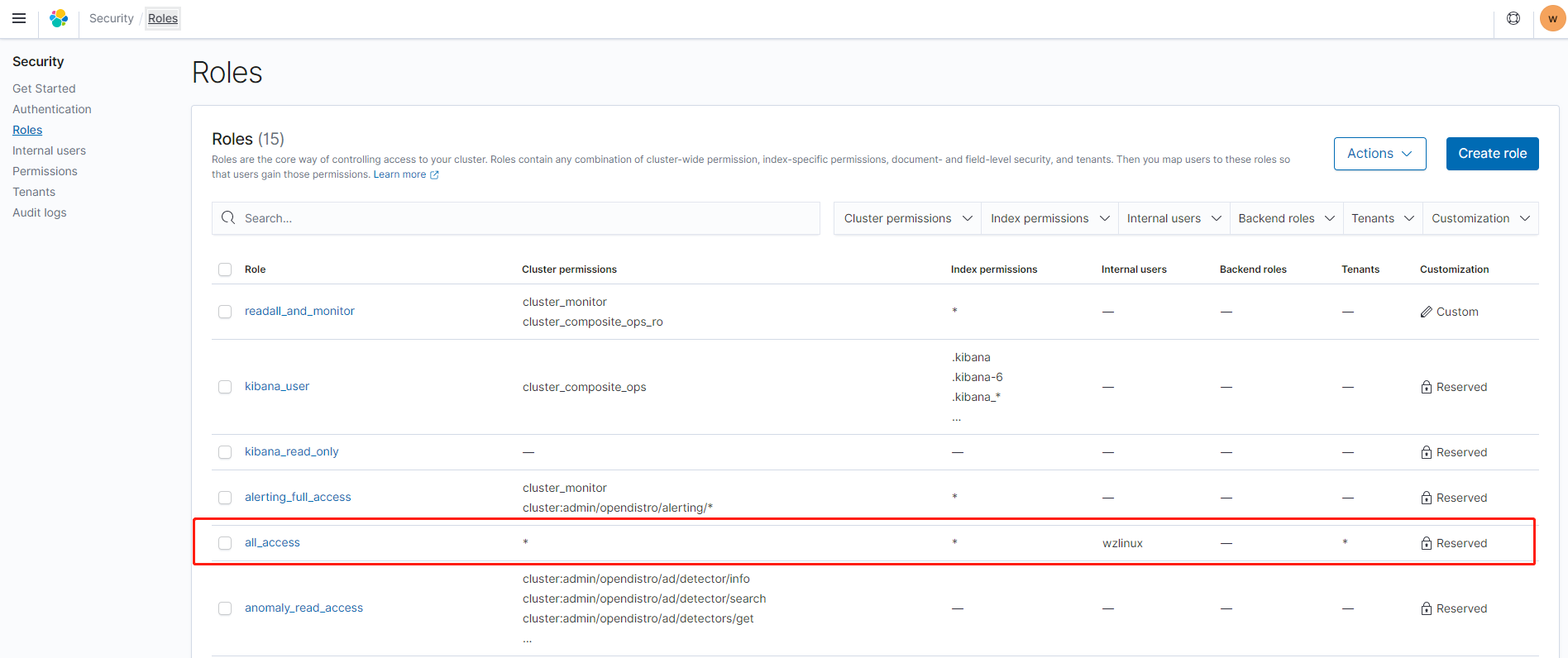
点击 all_access,进入 Mapped users
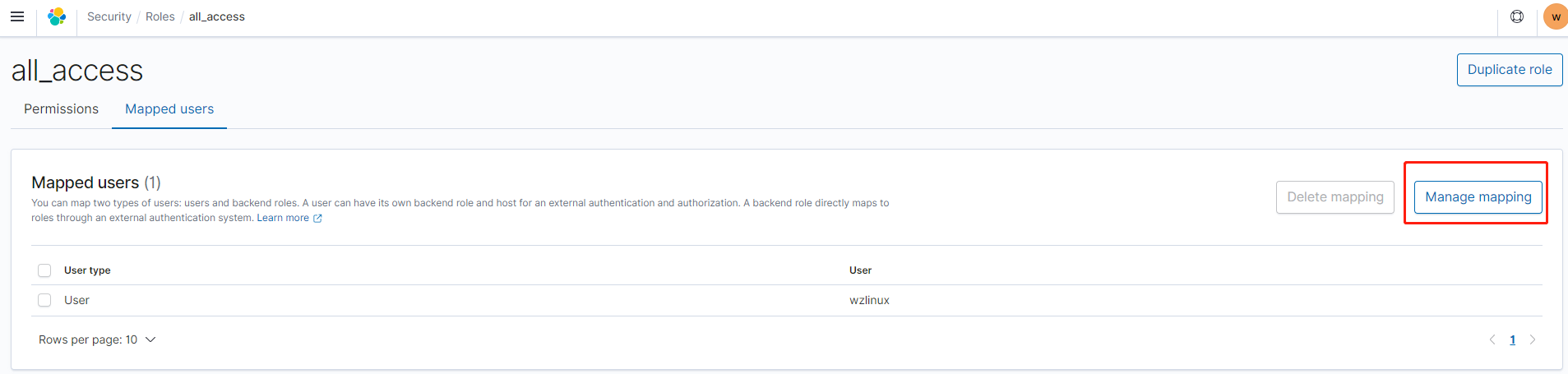
创建角色映射,我们把 KDF 的角色写入到 Backend roles 里面
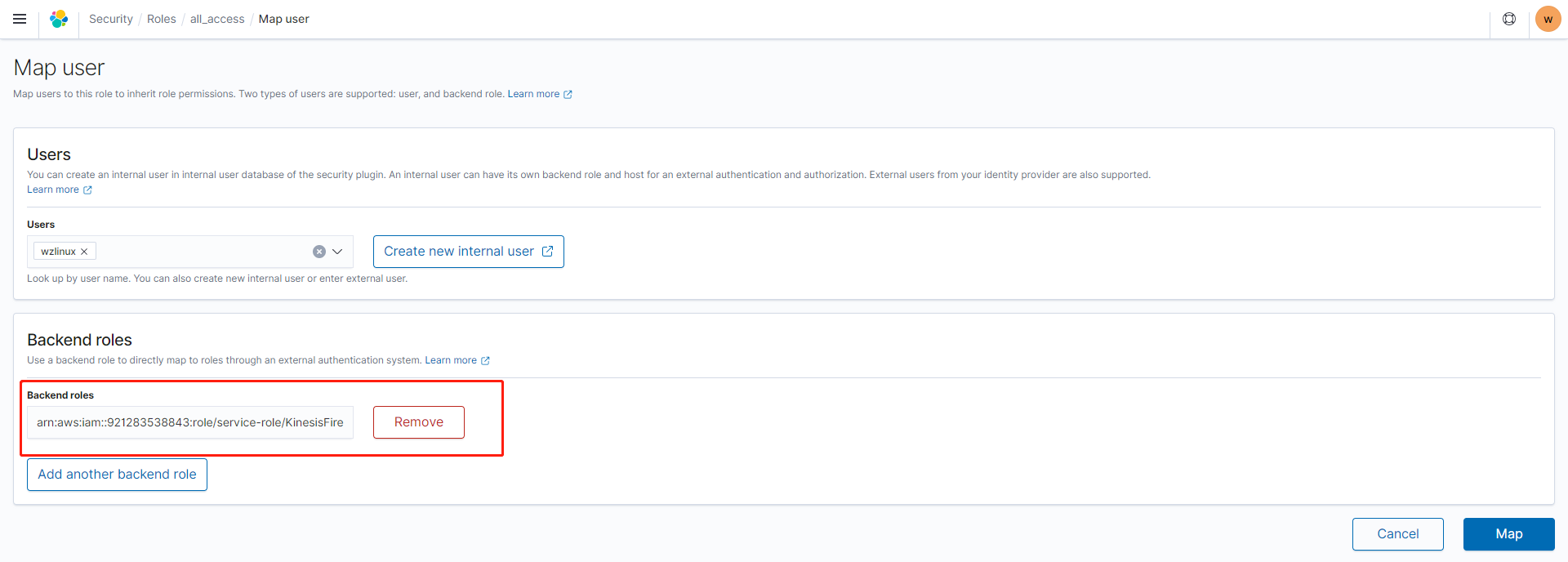
点击映射保存
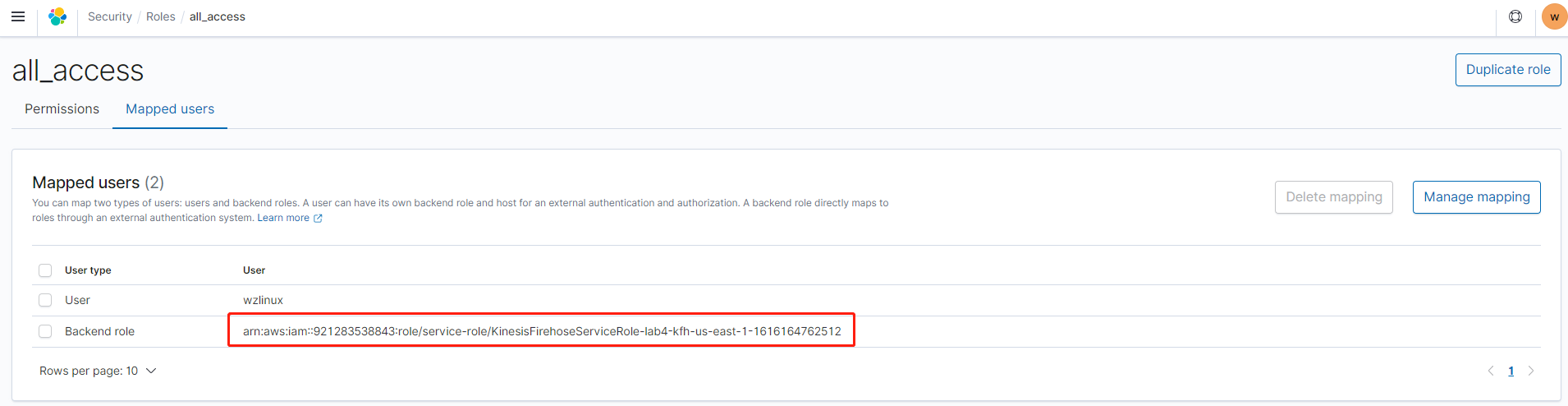
创建 Index
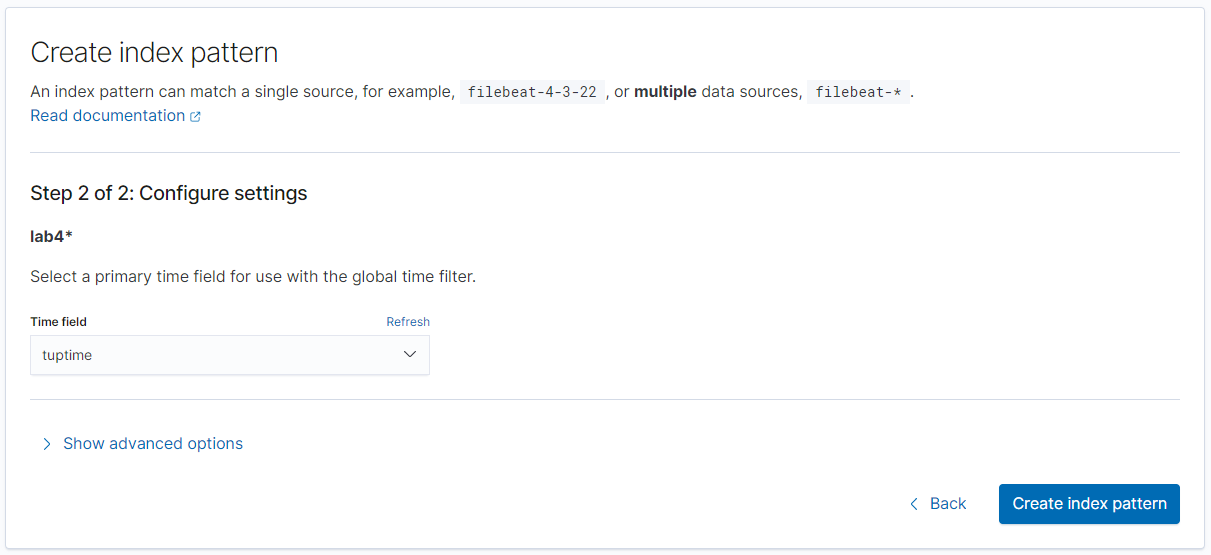
点击主菜单进入 Discover,选择 Create index pattern

系统已经发现了 Index 为 lab4 的相关数据,我们直接输入 lab4 即可(注意:如果此处看不到数据,请略微等待,如果长时间等待依然没有数据,请确认 Kinesis Firehose 的配置是否准确)
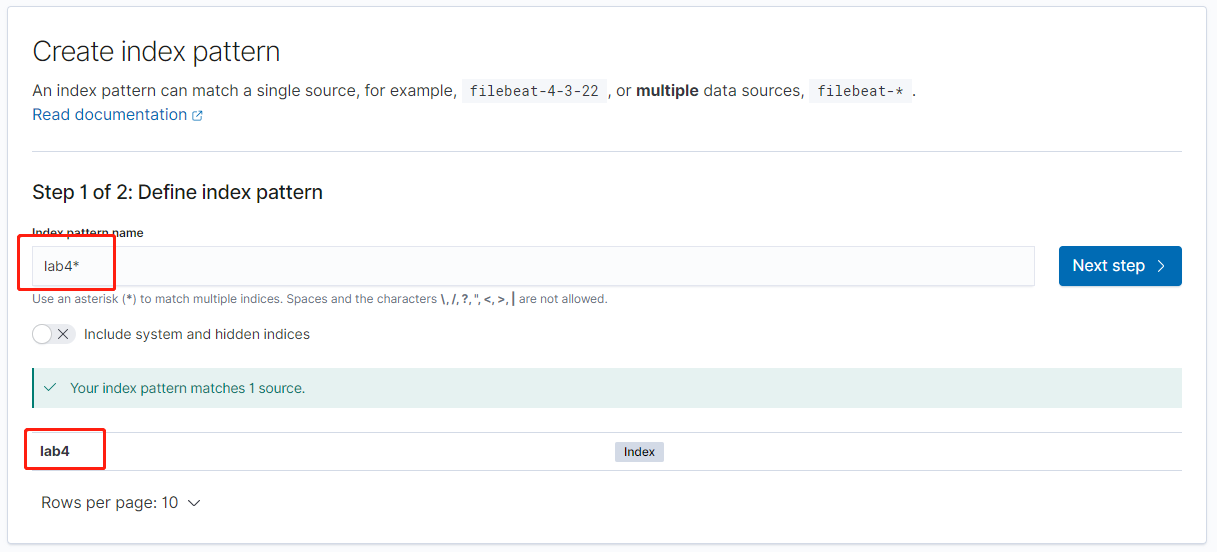
接下来选择tuptime为时间戳即可
通过选择对应字段,我们即可看到对应数据
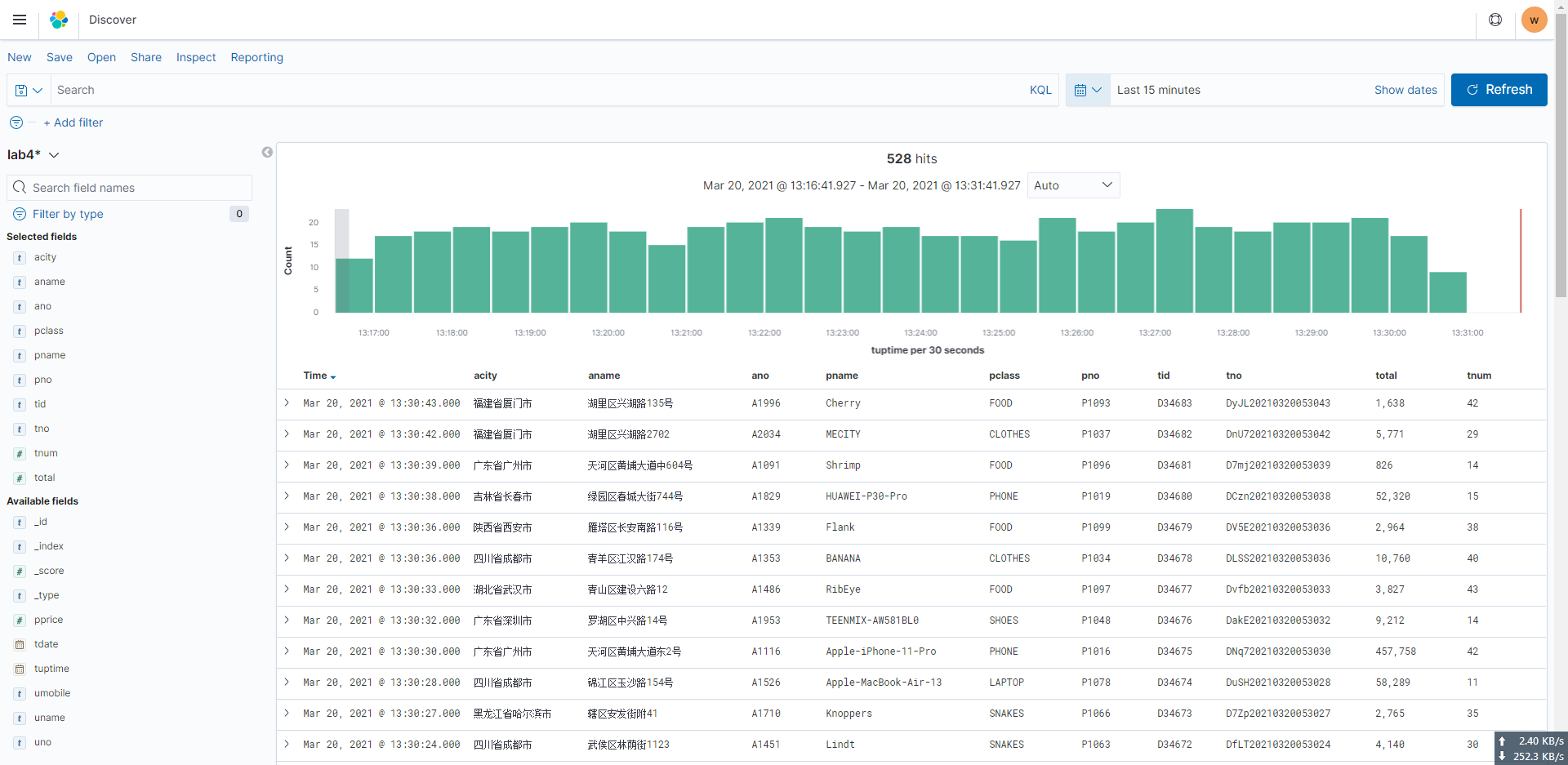
按时间维度查看
接下来我们来创建第一个可视化图表(按时间维度查看销售额),首先创建一个视图
类型选择 Vertical Bar
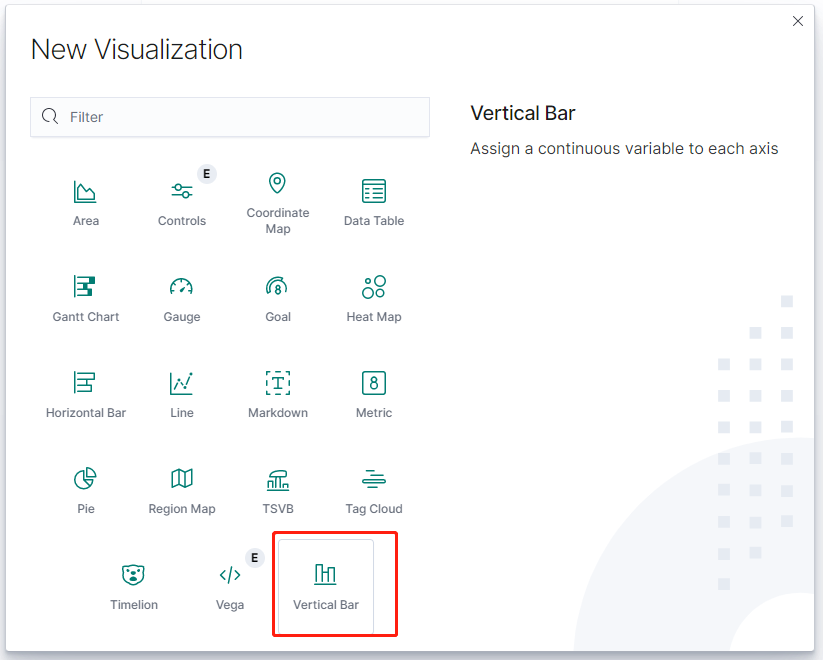
类型选择 数据源
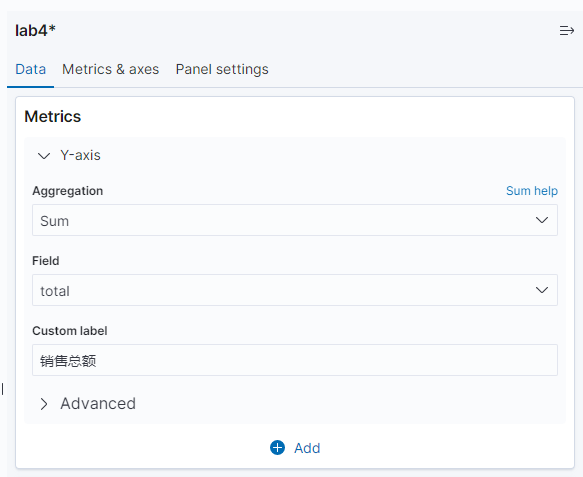
在 Y-axis 界面,aggregation下拉框选择 sum,field 选择 total,并备注为总销售额
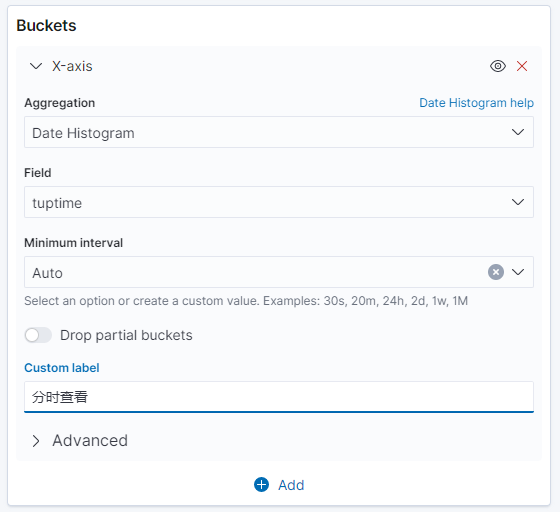
在 Buckets 界面,点击 add,选择 X-axis,Aggregation 选择 Date Histogram,Field 选择 tuptime,Minimum 选择默认值 Auto(因为我们输入数据时间较短,所以难以形成例如以天为单位的汇总数据)
点击更新后获得如下图表,选择左上角的保存
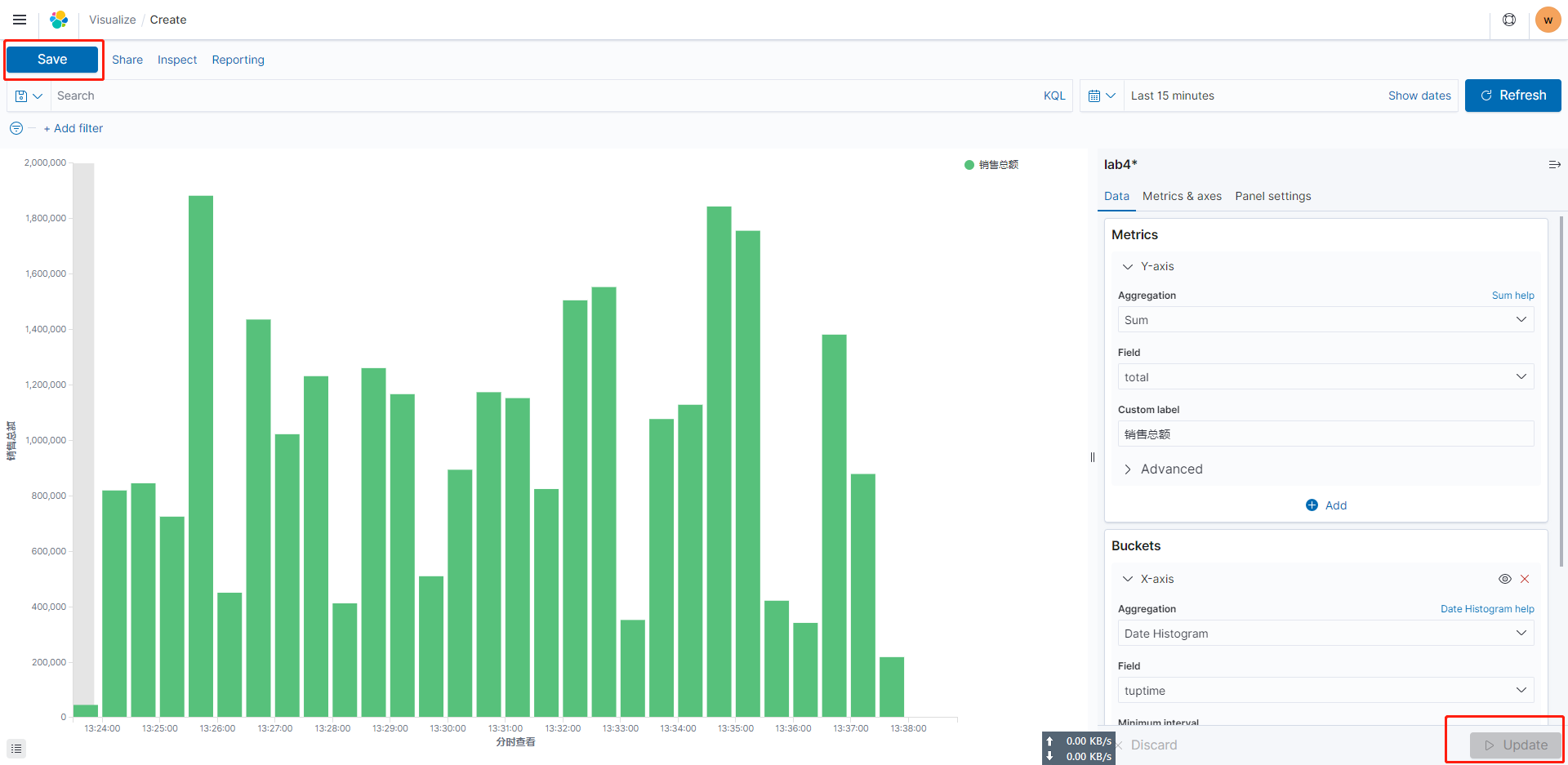
设置保存名称:time_revenue。注意:图表的时间线,可以根据要求在右上角位置进行修改。
按区域维度查看
这一次我们选择表格的方式(取销售额排名前10的城市,选择表格的形式)
配置指标数据为 total 列的和
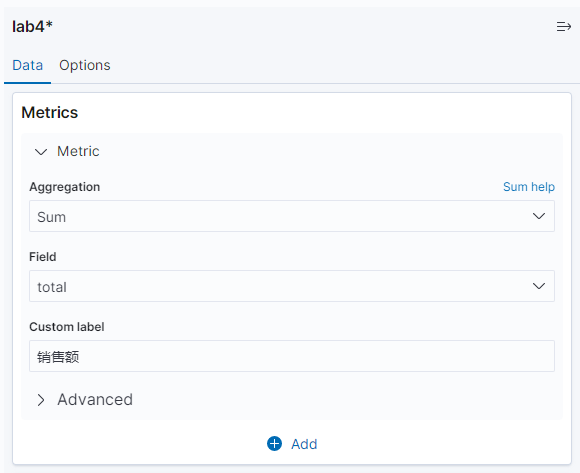
再点击 add,创建 split rows,Sub-aggregation 选择 terms,fields 选择 acity.keyword,单击更新按钮
获得的 Top 10 城市销售金额表(注意:因为流数据一直在注入,所以数据会变),如下图所示
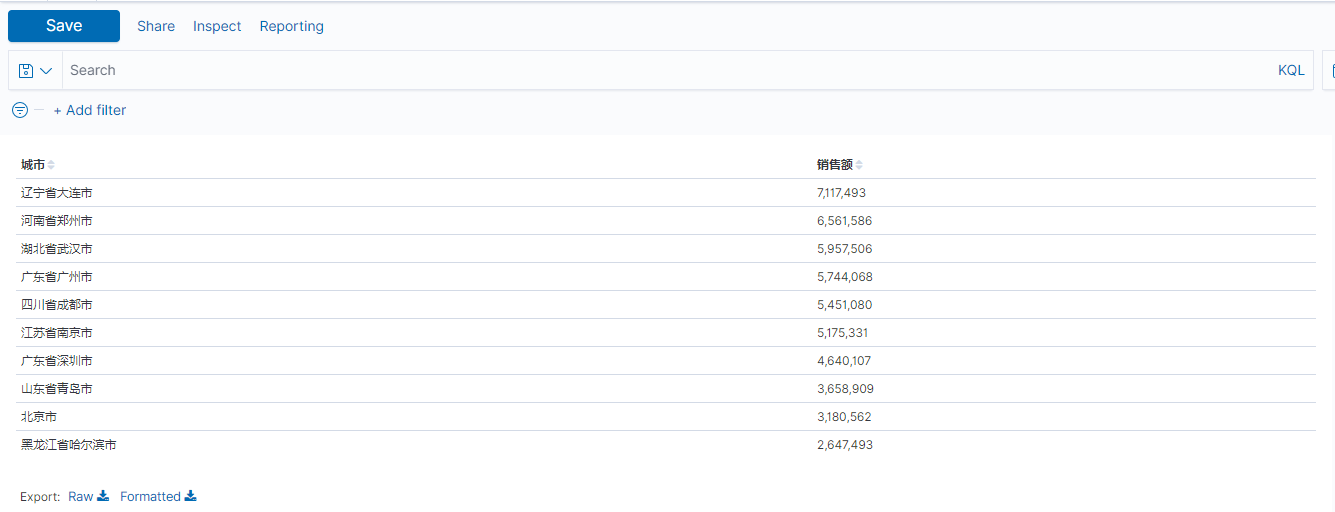
然后点击左上角的“save”按钮进行保存,输入图表的名称 time_city
按产品维度查看
我们选择用饼图的方式来按产品维度查看
配置指标数据为 total 列的和
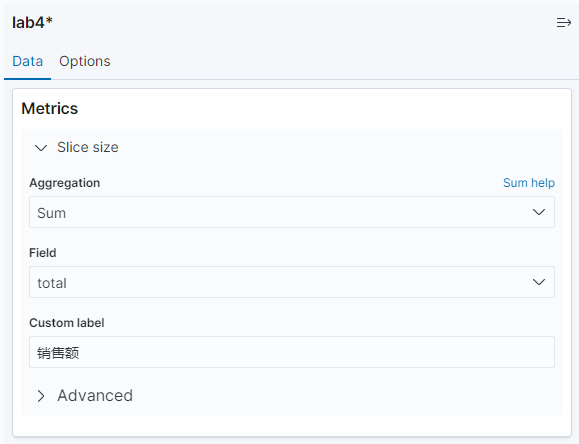
结合产品分类
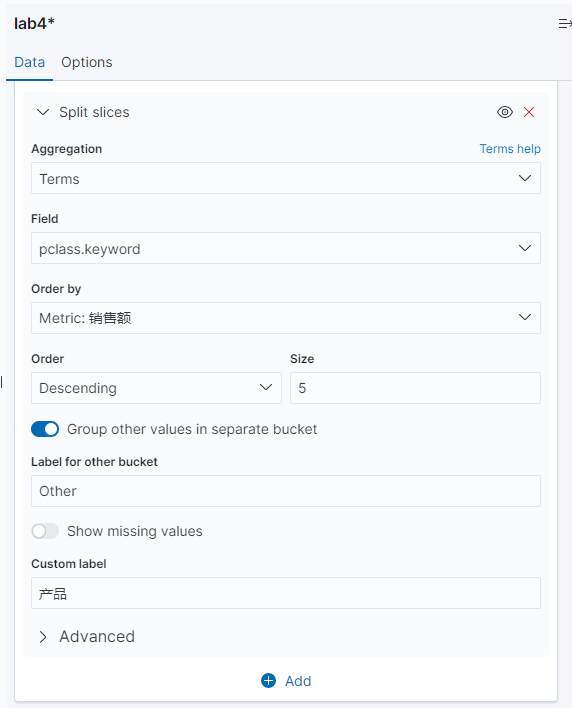
并且配置显示标签(如果未显示标签就只有图,选中了标签以后会显示对应的备注和数据)
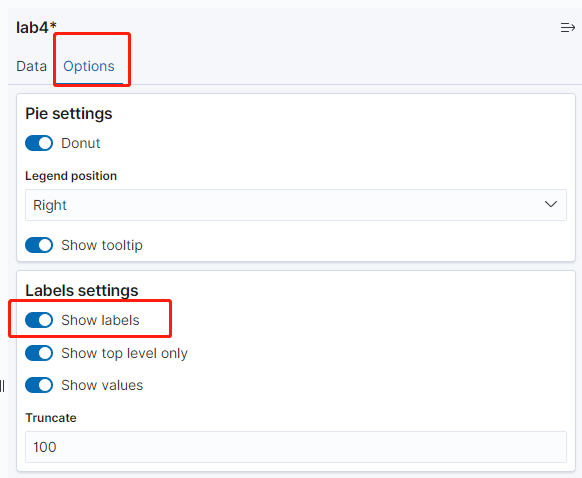
获得如下图所示的饼图(显示Top销量的产品分类,以及其他的汇总),保存成:time_pclass
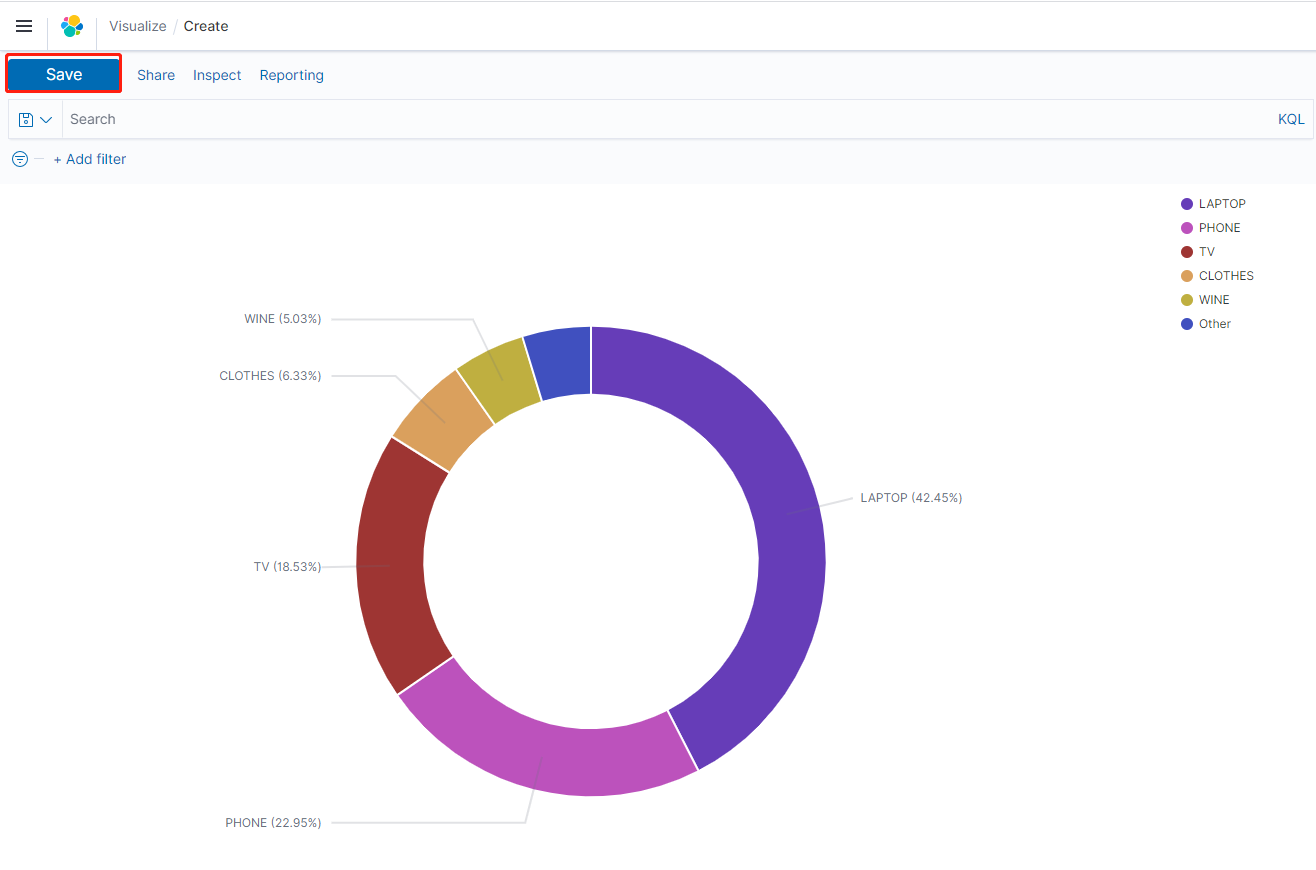
创建仪表盘
在上述章节的实验过程中,我们创建了 3 个可视化报表
这个章节,我们把刚才创建的图表做成仪表盘。点击左侧按钮,创建 Dashboard,点击“create new dashboard”,点击 add 按钮,把刚才的三个图表添加进来
添加已经创建好的各个图表(并保存仪表盘,此处为 MyLab4),效果如下
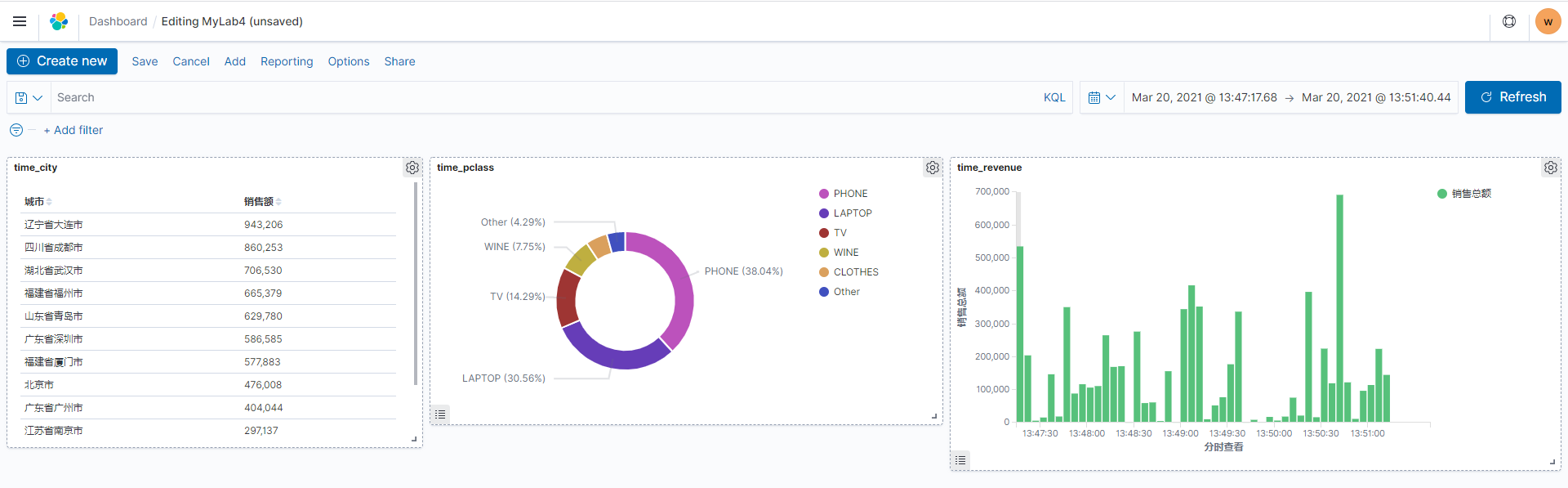
可以根据选择右上角不同的时间区间获得不同的实时统计结果,各位熟悉 Elasticsearch 的学员可以按照自己喜欢的方式在 ES 里面构建各种图表。
欢迎大家扫码关注,获取更多信息
