
Poly-encoders: architectures and pre-training strategies for fast and accurate
multi-sentence scoring
非官方github : https://github.com/chijames/Poly-Encoder
https://github.com/sfzhou5678/PolyEncoder
1.摘要
Cross - encoder 对句子对进行完全self-attention ,Bi - encoder分别对句子对进行编码。前者往往性能更好,但实际使用起来太慢。在这项工作中,作者开发了一种新的Transformer 架构:Poly - encoder,它学习全局而不是token级的self-attention功能。
2.介绍
本文对BERT模型进行改进,将其用于多句子评分:给定一个输入上下文,给一组候选标签的评分。这是检索和对话任务的常见形式,它们必须考虑两个方面:
- 预测质量(Cross - encoder √)
- 预测速度(Bi - encoder √)
因此提出Poly - encoder,相比于Cross - encoder 速度更快,预测质量比 Bi - encoder更高。并且发现,使用与下游任务更相似的数据对Poly - encoder进行预训练相比于BERT带来了显著的受益。
3. task
考虑两个任务:
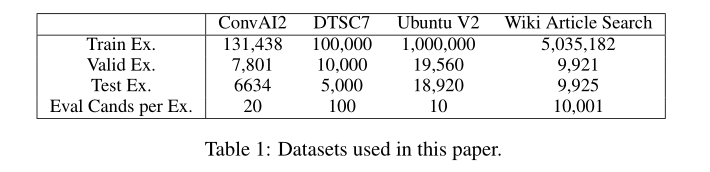
3. 对话任务(句子选择):ConvAI2 , DSTC7,Ubuntu V2
4. IR任务(文章检索):Wikipedia Article Search
4.方法
4.1 Transformer 和pre-train策略
Transformers:本文的transformer(Bi , Cross,Ploy)在后面描述,它们与BERT有相同大小和尺寸,12层,12个attention heads,hidden size 768。除了考虑预训练的BERT权重外,作者还重新训练了两个Transformer:
- 使用类似于BERT-base中的训练设置,对从维基百科和多伦多图书语料库中提取的1.5亿个[INPUT,LABEL]示例进行训练
- 使用从在线平台Reddit 中提取的1.74亿个[INPUT,LABEL]示例进行训练,这是一个更适合对话的数据集。
前者是为了验证再现类似BERT的设置给我们提供了与之前报告相同的结果,而后者测试对更类似于感兴趣的下游任务的数据的预训练是否有所帮助。
Input Representation:本文的预训练输入[INPUT,LABEL]的连接,其中两者都被特殊的标记[ S S S]包围。
在Reddit上进行预训练时,输入的是上下文,label的是下一句话。当在维基百科和多伦多图书上进行预训练时,
输入是一句话,标签是文本中的下一句话。每个输入令牌都表示为三个嵌入的总和:token嵌入、position嵌入和
segment嵌入,输入标记的段为0,标签标记的段为1。
Pre-training Procedure:对于维基百科数据,与BERT相同,采用MLM训练。在Reddit上的预训练中添加了一个下一个话语预测任务,它与BERT略有不同,因为一个话语可以由几个句子组成。在训练过程中,一半时间是真实的下一句话,另一半时间是从数据集中随机抽取的一句话。
使用Adam优化器,其学习率为2e-4,β1= 0.9,β2= 0.98,没有L2权重衰减,线性学习率预热,以及学习率的平方根倒数衰减。在所有层上使用0.1的dropout。
batch size :32000个由相似长度的连接[INPUT,LABEL]组成的token。在32个GPU上训练模型14天。
Fine-tuning:经过预训练后,考虑三种架构来微调Transformer :Bi - encoder,Cross - encoder Poly - encoder。
预先定义颜色标志
4.2 Bi - encoder
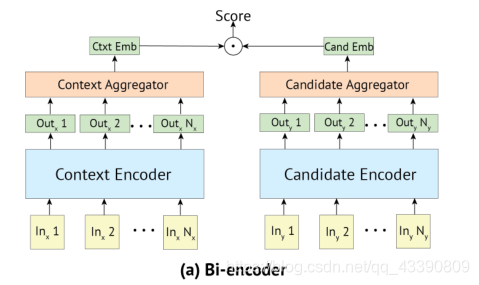
在Bi - encoder中,输入上下文和候选标签都被编码成向量:

其中 T 1 T_1 T1和 T 2 T_2 T2是两个预训练好的Transformer ,它们最初以相同的权重开始,但在微调期间可以单独更新。 T T T( x x x) = h 1 h_1 h1,…, h N h_N hN是Transformer T T T的输出, r r r e e e d d d ( ( ( ) ) )是一个函数,它将向量序列简化为一个向量。由于输入和标签是分开编码的,因此两者的段标记都是 0 0 0。
h 1 h_1 h1对应于token : [S]。本文考虑了通过 r r r e e e d d d ( ( ( ) ) )将输出减少为一个表示的三种方法:
- 选择Transformer的第一个输出(对应于特殊token [S])
- 计算所有输出的平均值
- 前m ≤ N个输出的平均值。
结果在实验中展示。
Scoring : 由点积 s s s( c c c t t t x x x t t t, c c c a a a n n n d d d i _i i) = y y y c _c c t _t t x _x x t _t t ⋅ · ⋅ y y y c _c c a _a a n _n n d _d d i _i i给出的候选 c c c a a a n n n d d d i _i i的分数。网络被训练成最小化交叉熵损失,其中logits是 y y y c _c c t _t t x _x x t _t t ⋅ · ⋅ y y y c _c c a _a a n _n n d _d d 1 _1 1,…, y y y c _c c t _t t x _x x t _t t ⋅ · ⋅ y y y c _c c a _a a n _n n d _d d n _n n,其中 c _c c a _a a n _n n d _d d 1 _1 1是正确的标签,其他标签是从训练集中选择的(每个batch 中其他标签为负例)。
Inference speed :使用FAISS库构建索引,存储embedding向量,在推理时,只需要点积操作这一步骤。
4.3 Cross-encoder
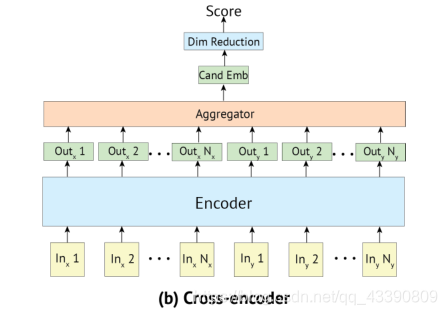
上下文和标签的connection:
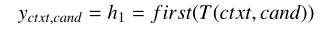
f f f i i i r r r s s s t t t是一个函数,取最后一层输出的第一个向量([S] token )。Cross-encoder能够在上下文和候选之间执行self-attention,从而产生比Bi - encoder更丰富的提取机制。
Scoring : 用一个线性层 W W W映射Transformer的输出为一个标量作为评分:

L L L o o o s s s s s s与Bi - encoder同为交叉熵函数。与Bi - encoder不同,Cross-encoder不能将同batch内的其他标签作为负例回收,因此在训练集中采样负例。Cross-encoder使用的内存比Bi - encoder多得多,导致batch小得多。
Inference speed:在推理时,每个候选对象都必须与输入上下文相连接,并且必须通过整个模型的正向传播。所以并不适用大规模对象。
4.4 Poly-encoder
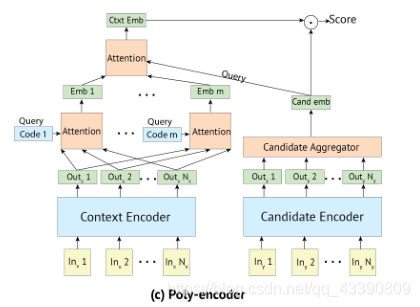
Poly-encoder目标是从上述两个类型encoder中获得最佳结果。
像Bi - encoder一样,Poly-encoder对上下文和标签使用两个独立的Transformer,候选对象被编码成单个向量 y y y c _c c a _a a n _n n d _d d i _i i。因此,可以使用预计算缓存来实现Poly-encoder方法。
但是,输入的上下文通常比候选长得多,Poly-encoder用 m m m个向量聚合Transformer输出表示为:( y y y 1 ^1 1 c _c c t _t t x _x x t _t t,…, y y y m ^m m c _c c t _t t x _x x t _t t),其中 m m m将影响推理速度。为了获得代表输入的这 m m m个全局特征,学习 m m m个上下文codes ( c 1 c_1 c1,…, c m c_m cm),其中, c i c_i ci通过关注前一层的所有输出来表示 y y y i ^i i c _c c t _t t x _x x t _t t。也就是说,获得 y y y i ^i i c _c c t _t t x _x x t _t t:(这里其实就是Inner - attention的想法)
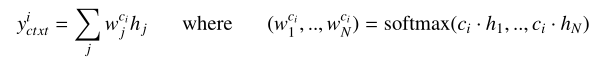
m m m个上下文代码是随机初始化的,并在微调期间学习。最后,给定 m m m个全局上下文特征,使用 y y y c _c c a _a a n _n n d _d d i _i i作为查询来处理它们:(这里就是attention思路)
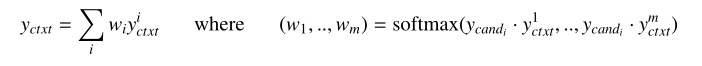
5 Experiments
data
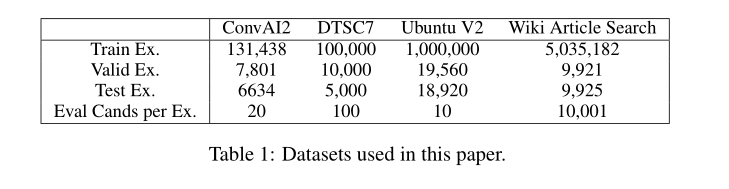
评价指标
Recall@C , MRR
5.1 Bi-encoder and Cross-encoder
首先实验原始BERT的权重 微调。Bi-encoder的情况下,可以通过将其他batch视为负训练样本来使用大量的负样本,从而避免重新计算它们的嵌入。在8个Nvidia Volta v100 GPUs上,使用浮点运算,在ConvAI2上达到512个元素的batch。表2显示,在这种设置下,使用更大的batch获得更高的性能,其中511个负例产生最佳结果。

对于其他任务,将batch大小保持在256,因为这些数据集中较长的序列会占用更多内存。Cross-encoder计算量更大,因为每次都必须重新计算(上下文,候选)对的嵌入。因此,将其批量限制为16,并从训练集中提供负随机样本。对于DSTC7和Ubuntu V2,选15个负例;对于ConvAI2,数据集提供19个负例。
本文尝试了两个优化器:权重衰减为0.01的Adam和没有权重衰减的Adamax ;
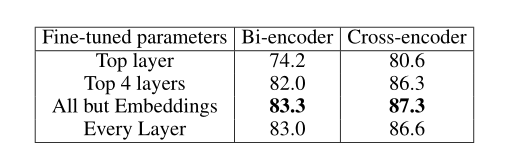
基于验证集的性能,选择在使用BERT权重时与Adam一起微调。学习速率初始化为5e-5,Bi-encoder和poly-encoder预热100次,Cross-encoder预热1000次。在每半个epoch,在有效集合上评估的损失平稳区间,学习率下降0.4倍。 表3显示了使用带有衰减优化器的Adam对BERT提供的权重的各个层进行微调时的验证性能。 除词嵌入外,对整个网络进行微调非常重要。
5.2 Poly-encoder
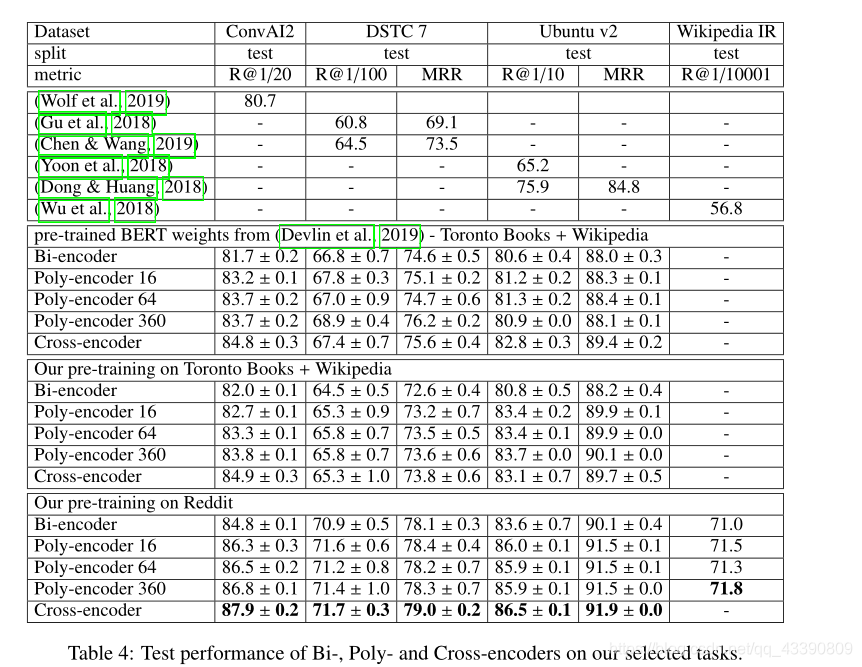
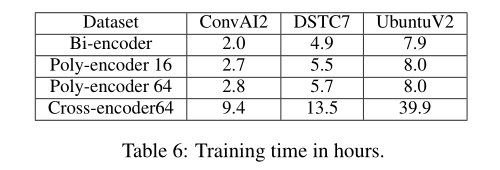
poly - encoder 后面的数字表示为集合codes m m m的大小,得到的结论是,在计算成本允许的情况下, m m m越大,模型性能越好。有些甚至优于Cross-encoder,但是Cross-encoder的计算成本是巨大的。见下图推理时间比较表。
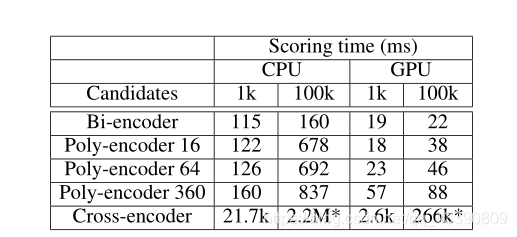
CPU:80 core Intel Xeon processor CPU E5-2698
GPU:单个Nvidia Quadro GP100 using cuda 10.0 and cudnn 7.4
另外,在与下游任务相似的数据上训练时,性能相比于BERT有相当大的提升。
附录
A . 在四个数据集上的训练时间(小时):
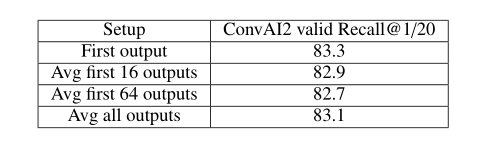
B. : Bi-encoder的输出采样策略比较:(first表示取[ S S S]位置的token输出,Avg first 16 outputs表示取前16个输出( h 1 h_1 h1, h 2 h_2 h2,…, h 1 h_1 h1 6 _6 6)…),可以看到直接取[ S S S]效果最好。
C. 上下文向量的替代选择
本文考虑了其他几种从输出( h h h 1 ^1 1 c _c c t _t t x _x x t _t t,…, h h h N ^N N c _c c t _t t x _x x t _t t )导出上下文向量( y y y 1 ^1 1 c _c c t _t t x _x x t _t t,…, y y y m ^m m c _c c t _t t x _x x t _t t)的方法( m m m 《 《 《 《 《 《 N N N):
- 4.4中介绍的方法,学习 m m m codes ( c 1 c_1 c1,…, c m c_m cm),其中 c i c_i ci表示 y y y i ^i i c _c c t _t t x _x x t _t t关注所有输出( h h h 1 ^1 1 c _c c t _t t x _x x t _t t,…, h h h N ^N N c _c c t _t t x _x x t _t t )。该方法称为“Learnt-codes”或“Learnt-m”。
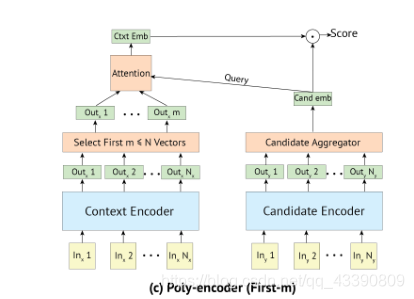
- 考虑前 m m m个输出( h h h 1 ^1 1 c _c c t _t t x _x x t _t t,…, h h h m ^m m c _c c t _t t x _x x t _t t ),然后与候选embedding做普通attention,(见下图(c))这种方法被称为“First-m”。
- 考虑最后 m m m个输出。
- 考虑最后 m m m个输出与第一个输出 h h h 1 ^1 1 c _c c t _t t x _x x t _t t(token :[ S S S])连接。
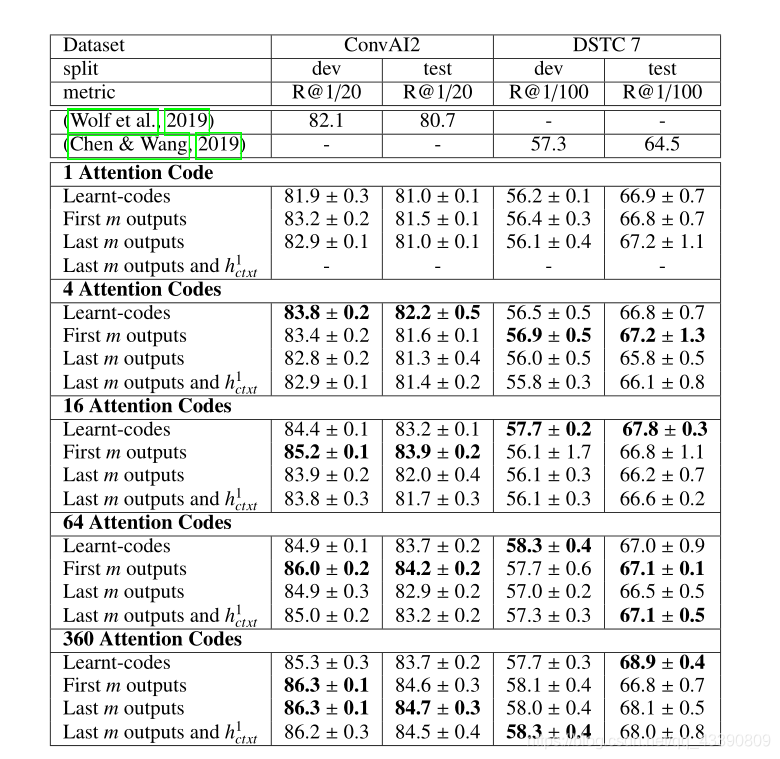
下表报告了m为{1,4,16,64,360}时各个策略的评价指标:
三个数据集上的整体评价:
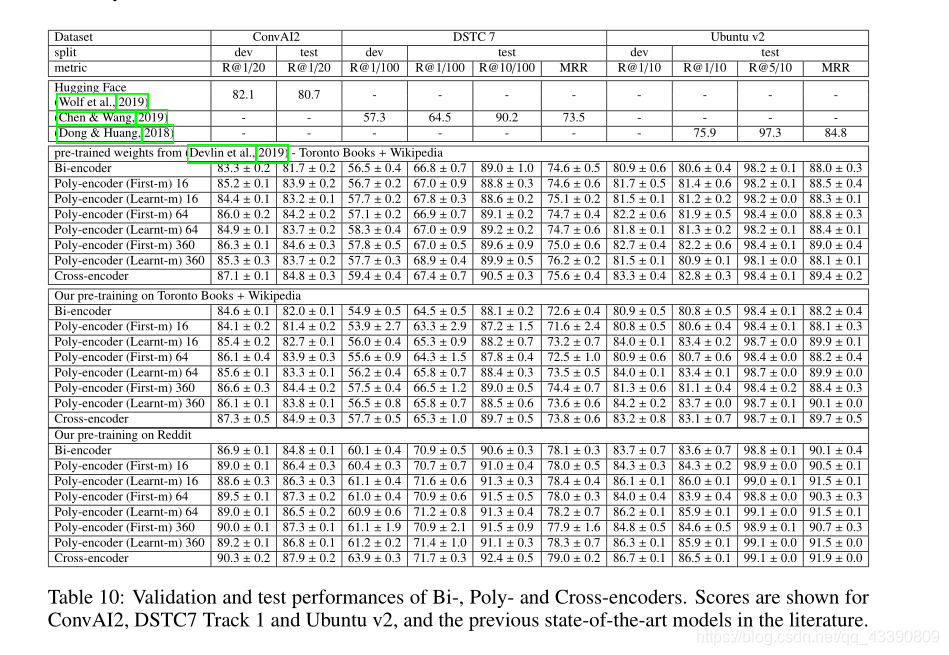
可以看到,在不同数据集上Learnt-m和First-m各有千秋。