本项目实现了对知乎用户信息的爬取,并没有用数据库等,只是简单地用一些提取了一些字段然后存储在了一个csv文件中,但是同样可以实现无线爬取,理论上可以实现万级数据的爬取(当然取决于网速了)
其实想爬取知乎网站是不需要进行登录的,通过一个个人账号就可以直接进行爬取了。
事先准备:要求不多,其实掌握了基本的scrapy爬虫编写的方式就可以了,当然对python的基本语法要有了解,还有就是一定的逻辑处理能力。
好了,我们来开始进行项目的解析:
我们首先从一个 个人账户的首页进行解析数据,比如我们最爱的——轮子哥
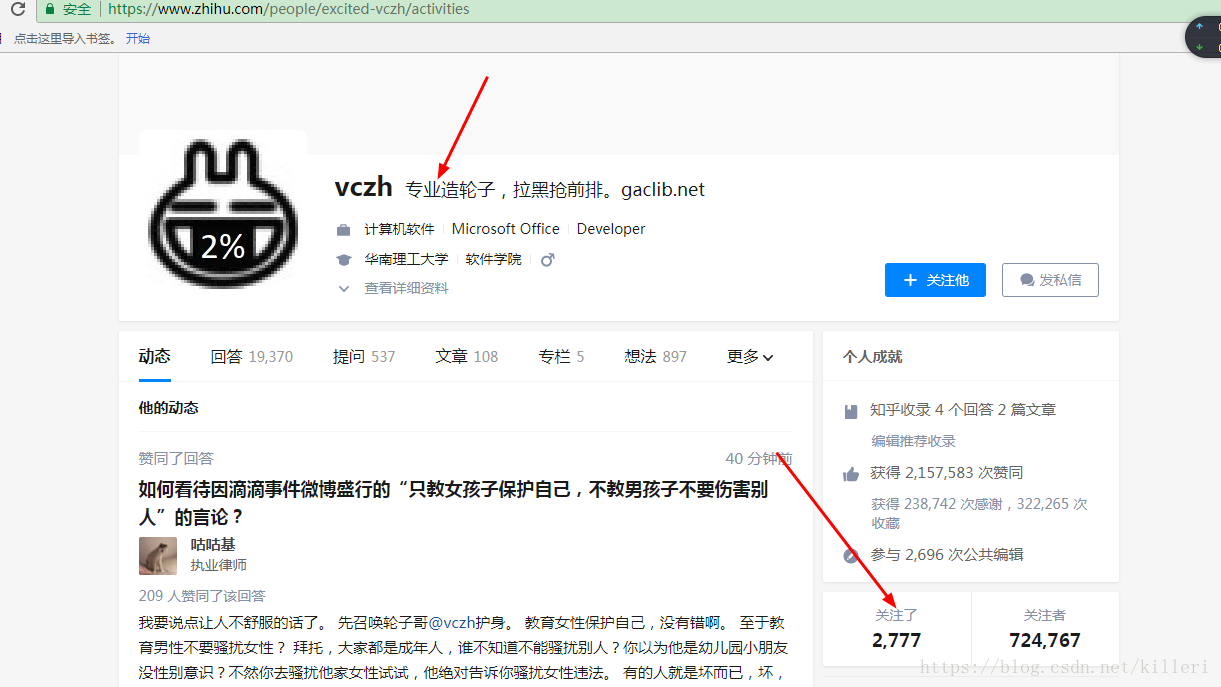
两个箭头的位置使我们接下来要重点分析的地方,我们要爬取的就是轮子哥的详细信息,我们打开开发者工具,找到页面的源码,找出轮子哥的详细信息在源码中的位置
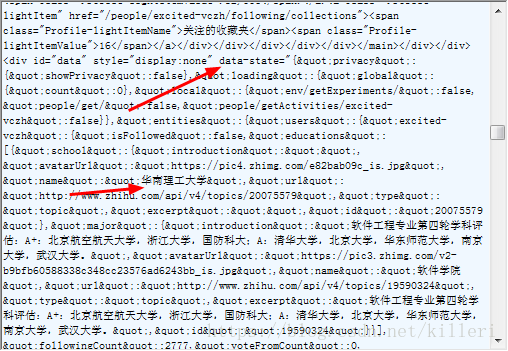
我用的fiddler找到请求,在响应中,我发现轮子哥的详细信息都在一个data-state的变量中,而且变量明显是一个json类型的数据("是双引号),那我们接下来就是提取这个json数据中我们需要的数据
第一步:把json数据提取出来,用正则表达式re提取json数据
x = response.body.decode('utf-8')
# 用utf8解码响应的数据流
y = re.search('data-state="({.*?})"', x).group(1).replace('"', '"')
# 用re提取json数据,并用双引号"替换"字符经过上面一步就是y就是一个标准的json数据了,那接下来在这个数据中找信息,这么乱怎么找?
我们可以用一个json在线解析,将json数据进行格式化,如图:
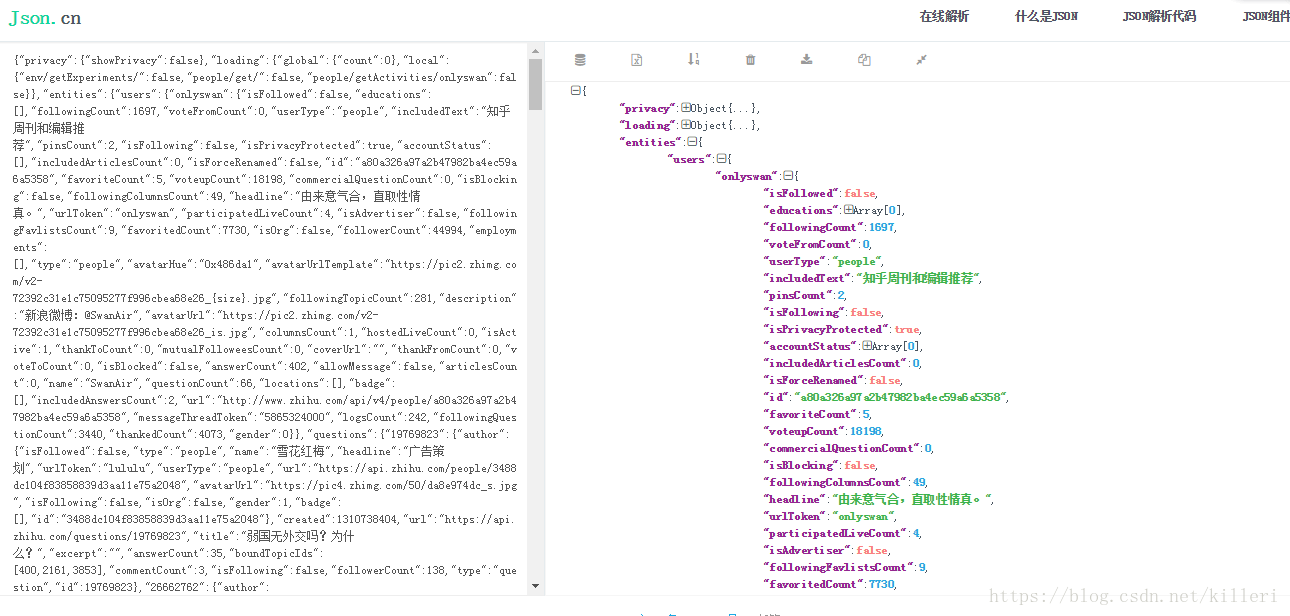
这里只用把json数据放进去就可以自动化在右边输出一个json格式的数据。接下来我们就只剩下解析json数据了。这个应该不难吧!
其实代码的大部分就是一个解析json’数据的过程,用json.loads方法将json数据转化为python字典的形式,然后用字典的方法提取我们想要的信息,明显几乎所有的信息都在users这个键里面。
好了,提取完了轮子哥的基本信息,这是一个魔伴,我们是要提取所有人的信息,所以要实现一个循环,让虫子爬,顺着轮子哥的关注的人爬,然后再爬,一直爬!!!
这就是一个逻辑的问题。
我们再来分析一下我们的start_urls,https://www.zhihu.com/people/excited-vczh/activities 这个链接我们改变的只有一个exci-vczh,也就是说每个人的主页都是这样组成的,那么我们怎么拿到这个东西呢?
好,我们再分析一下那个json数据

可以看到那个urlToken关键字所对应的值刚好使我们需要的字段,那么没话说,我们需要去找到其他人的这个urlToken。找谁的呢,我们来找轮子哥关注的人的
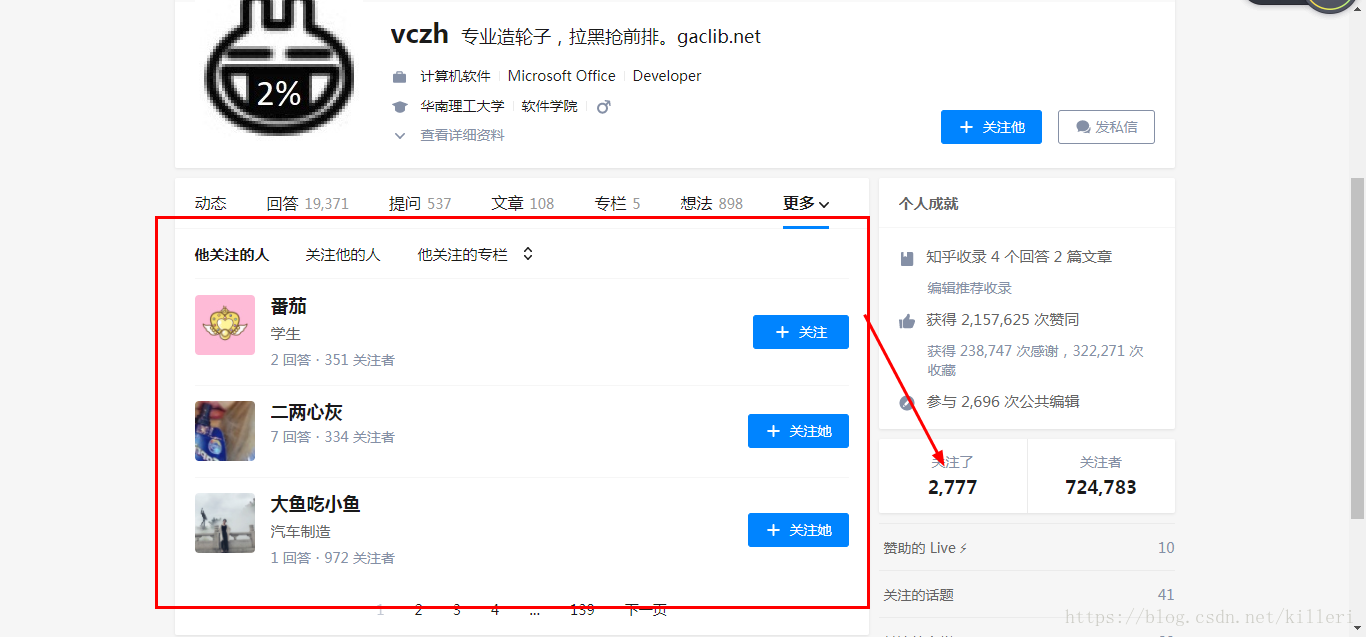
我们点击轮子哥关注的人,然后跳转页面,然后检查页面!
和前面一步一样,我们在这个页面的响应内容里面仍能找到一个data-state变量,也是存储了一个json的数据,我们提取这个数据,然后再json解析器中解析就能找到他关注的人的urlToken,好了,我们接下来只要用URLToken进行替换就可以了!
逻辑代码贴出来:
def parse_fellow(self,response):
x = response.body.decode('utf-8')
y = re.search('data-state="({.*?})"', x).group(1).replace('"', '"')
dict_y = json.loads(y)
users = dict_y.get('entities').get('users')
for user in users.keys():
urlToken = users.get(user).get('urlToken')
url = 'https://www.zhihu.com/people/{}/activities'.format(urlToken)
yield scrapy.Request(url=url,callback=lambda response,name=urlToken: self.parse_urlToken(response,name))
# 当解析函数有多个参数时,我们就可以用这种方式专递多个参数了!这样我们基本上完成了知乎的递归爬取信息,似乎是一个广度优先的爬取方式
由于我们这次只是简单的爬取,就不用数据库了,直接存进一个csv文件中
scrapy crawl zhuhuspider -o zhuhu_massage.csv这样运行起来,我们就可以在文件中找到爬取的数据了!,贴图!!!!
我怕去的字段有:
school_and_major = Field() # 学校和专业
id = Field() # id
favoriteCount = Field()
voteupCount = Field()
headline = Field()
urlToken = Field()
employments = Field()
job_and_company = Field() # 公司和职位


这就是今天的知乎爬虫项目,可以无限爬取,不过图书馆网速比较慢,所以一个小时只爬取了1500条数据,然后就强行终止程序了!
源码就不给了,因为复制了就可以直接运行,可能会给网站造成一定的压力!
对了,强行加一张图!!!