语义分割模型发展
语义分割网络模型的发展:FCN 、SegNet、Unet、DeepLab、RefineNet、PSPNet、GAN 语义分割。本文主要以FCN 为重点进行分析
一、FCN
FCN(Fully Convolutional Network) 全卷积网络,和之前常用的分类网络的不同的地方就是里面没有全连接层,也就是对一张图的所有的像素点进行分类
为什么会出现全卷积网络(FCN)?
注:图片来源与网络

上图中的第一个网络会将一张图片转换成长度为1000的输出向量,每一个数值都表示的是图像属于每一类的概率,很容易看出这张图片的分类的标签是"tabby cat"
FCN则是通过一系列的卷积和池化得到特征图,再利用反卷积(Deconvolution)对特征图进行上采样重新得到和输入图片一样大小的特征图,由于网络中没有全连接层,所以最后得到的特征图是二维的,保留了原输入图片中空间位置信息
1.FCN主要特点
• 不含全连接层(FC)的全卷积(Fully Conv)网络。从而可适应任意尺寸输入。
• 引入增大数据尺寸的反卷积(Deconv)层。能够输出精细的结果。
• 结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
2.反卷积(Deconvolutional)
在不断生成feature map过程中所用到的池化操作会使图片大小缩小,由于最后网络需要返回一个和原图尺寸详图的输出图所以需要对feature map进行放大,可以使用的操作是:反卷积,上采样+卷积
具体区别见:https://blog.csdn.net/qinghuaci666/article/details/80848642
3.跳跃结构
通过上面两个步骤是可以完成分割任务的,但是最终得到的结果是比较粗糙的,那么解决这个问题就需要结合深层语义信息和浅层外观信息,这样可以达到较好的效果;
深层语义信息和浅层外观信息:
语义信息(全局信息):提取位置是网络的深层;特点是物体的空间信息比较丰富,对应的感受野较大;有助于分割尺寸较大的目标,有利于提高分割的精确度。
外观信息(局部信息):提取位置是网络的浅层;特点是物体的几何信息比较丰富,对应的感受野较小;有利于分割尺寸较小的目标,有利于提高分割的精确度。

对原图像进行卷积conv1、pool1 后原图像缩小为1/2;之后对图像进行第二次conv2、pool2 后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3 缩小为原图像的1/8,此时保留pool3 的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4 的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN 操作中的全连接变成卷积操作conv6、conv7,图像的featureMap 数量改变但是图像大小依然为原图的1/32,此时图像不再叫featureMap 而是叫heatMap。
现在我们有1/32 尺寸的heatMap,1/16 尺寸的featureMap 和1/8 尺寸的featureMap,1/32 尺寸的heatMap 进行upsampling 操作之后,因为这样的操作还原的图片仅仅是conv5 中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征。因此在这里向前迭代,conv4 中的卷积核对上一次upsampling 之后的图进行反卷积补充细节(相当于一个插值过程),最后把conv3 中的卷积核对刚才upsampling 之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。

FCN的具体原理和训练过程:
https://blog.csdn.net/qinghuaci666/article/details/80863032
论文:
https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
二.SegNet
Segnet 是用于进行像素级别图像分割的全卷积网络,分割的核心组件是一个encoder 网络,及其相对应的decoder 网络,后接一个象素级别的分类网络。
encoder 网络:其结构与VGG16 网络的前13 层卷积层的结构相似。decoder 网络:作用是将由encoder的到的低分辨率的feature maps 进行映射得到与输入图像featuremap 相同的分辨率进而进行像素级别的分类。
Segnet 的亮点:decoder 进行上采样的方式,直接利用与之对应的encoder 阶段中进行max-pooling时的polling index 进行非线性上采样,这样做的好处是上采样阶段就不需要进行学习。上采样后得到的feature maps 是非常稀疏的,因此,需要进一步选择合适的卷积核进行卷积得到dense featuremaps 。
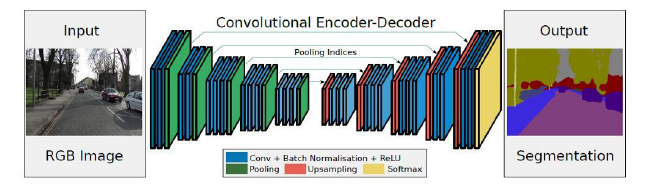
注意:SegNet中的decoder使用的是上采样+卷积的方式
SegNet 的思路和FCN 十分相似,只是Encoder,Decoder(Unsampling)使用的技术不一样。SegNet的编码器部分使用的是VGG16 的前13 层卷积网络,每个编码器层都对应一个解码器层,最终解码器的输出被送入soft-max 分类器以独立的为每个像素产生类别概率。左边是卷积提取特征,通过pooling 增大感受野,同时图片变小,该过程称为Encoder,右边是反卷积(在这里反卷积与卷积没有区别)与unsampling,通过反卷积使得图像分类后特征得以重现,upsampling还原到原图想尺寸,该过程称为Decoder,最后通过Softmax,输出不同分类的最大值,得到最终分割图。
三.Unet
U-net 对称语义分割模型,该网络模型主要由一个收缩路径和一个对称扩张路径组成,收缩路径用来获得上下文信息,对称扩张路径用来精确定位分割边界。U-net 使用图像切块进行训练,所以训练数据量远远大于训练图像的数量,这使得网络在少量样本的情况下也能获得不变性和鲁棒性。

• Encoder:左半部分,由两个3x3 的卷积层(RELU)+2x2 的max pooling 层(stride=2)反复组成,每经过一次下采样,通道数翻倍;
• Decoder:右半部分,由一个2x2 的上采样卷积层(RELU)+Concatenation(crop 对应的Encoder层的输出feature map 然后与Decoder 层的上采样结果相加)+2 个3x3 的卷积层(RELU)反复构成;
• 最后一层通过一个1x1 卷积将通道数变成期望的类别数。
注意:Unet同样使用了类似于FCN的跳跃结构,但是Unet是直接concatenate,而FCN是sum
四.其他
DeepLab、RefineNet、PSPNet、GAN会在后续博客中学习