一、实验目的
通过一张含有车牌的车的照片,分割出车牌并识别出图片上车的车牌号
二、具体内容
- 车牌定位
- 车牌字符分割
- 车牌字符识别
三、实验过程
1.车牌定位
具体过程:
1.灰度转换:将彩色图片转换为灰度图像,常见的R=G=B=像素平均值。
2.高斯平滑和中值滤波:去除噪声。
3.二值化处理:图像转换为黑白两色,通常像素大于127设置为255,小于设置为0。
4.canny边缘检测
5.膨胀和细化:放大图像轮廓,转换为一个个区域,这些区域内包含车牌。
6.通过算法选择合适的车牌位置,通常将较小的区域过滤掉或寻找蓝色底的区域。
7.标注车牌位置并提取车牌
读入原始图像

BGR转换为灰度图像

图像二值化处理
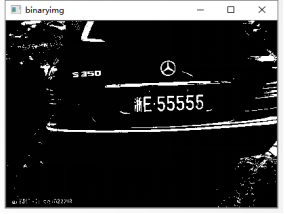
canny边缘检测
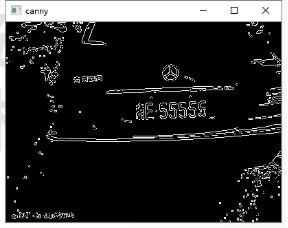
进行闭运算与开运算,消除小的区域,保留大块的区域,从而定位车牌位置

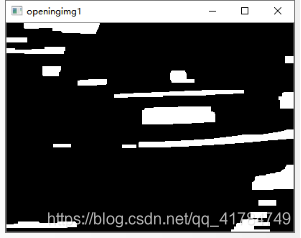
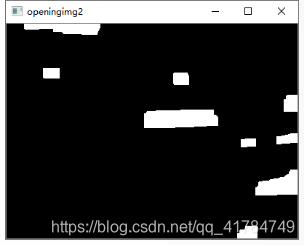
找出轮廓的左上点和右下点,由此计算它的面积和长度比。找出面积最大的三个区域。
在这三个最大的区域中使用颜色识别判断找出最像车牌的区域。
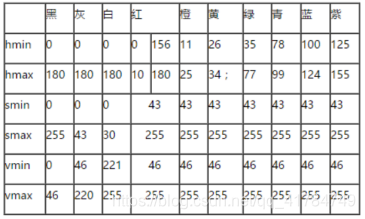
目前支持识别三种颜色的车牌,遍历所有像素点根据每个点的HSV值的区间来判断颜色。
统计所有点的颜色值,根据统计的所有 黄色、蓝色、绿色点的数量来确定车牌的颜色
HSV 颜色空间范围:
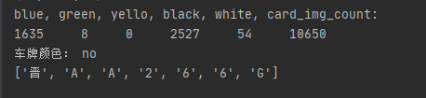
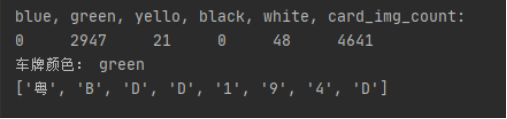
颜色识别结果:
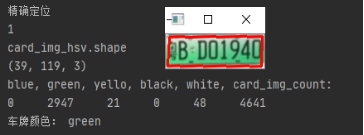
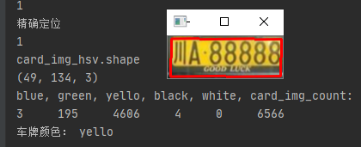
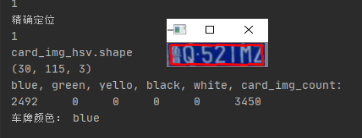
2.车牌字符分割
由于图像中只有黑色和白色像素,因此可以通过图像的白色像素和黑色像素来分割开字符。即分别通过判断每一行每一列的黑色白色像素值的位置,来定位出字符。
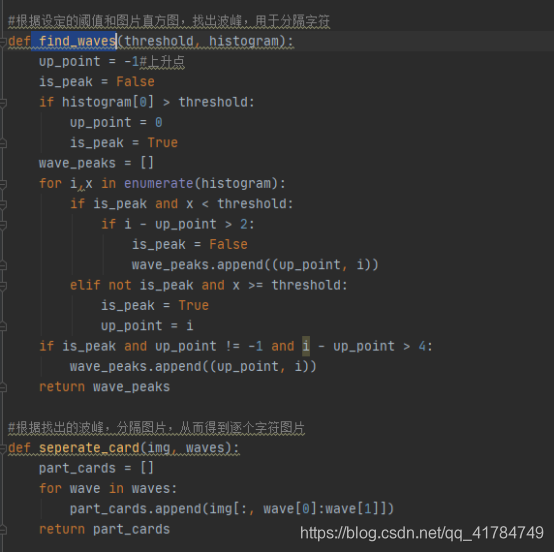
分割结果:
转灰度

二值化

分割:







3.车牌字符识别
在这里使用的是OpenCv自带的机器学习框架SVM模型
分别训练两个svm模型用于识别车牌中文省份简称和后面的字母和数字
opencv的svm框架使用:
model = cv2.ml.SVM_create()#生成一个SVM模型
model.setGamma(gamma) #设置Gamma参数,demo中是0.5
model.setC©# 设置惩罚项, 为:1
model.setKernel(cv2.ml.SVM_RBF)#设置核函数
model.setType(cv2.ml.SVM_C_SVC)#设置SVM的模型类型:SVC是分类模型,SVR是回归模型
model.train(samples, cv2.ml.ROW_SAMPLE, responses)#训练
model.predict(samples)#预测
model.load(filepath)#从文件载入训练好的模型
model.save(filepath)#保存训练好的模型到文件中
训练数据集:
SVM训练使用的训练样本来自于github
将训练数据集分成两类,分别训练两个模型
用于识别省份简称和右边的英文字符和数字
0-9,A到Z的数据集:

车牌的省份简写数据集:
训练过程:
使用文件夹的名称作为标签,文件中的图片作为数据
使用os.walk方法,主要用来遍历一个目录内各个子目录和子文件。
可以得到一个三元组(root,dirs,files),
root 所指的是当前正在遍历的这个文件夹的本身的地址
dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
os.path.basename(),返回path最后的名称,作为标签
cv2.imread(filepath) 读入训练数据
标好了训练数据和标签,就可以“喂”给分类器了:
model.train(chars_train, chars_label)
最后将训练好的模型保存到文件中,下次可以直接使用
model.save(“module\svm.dat”)
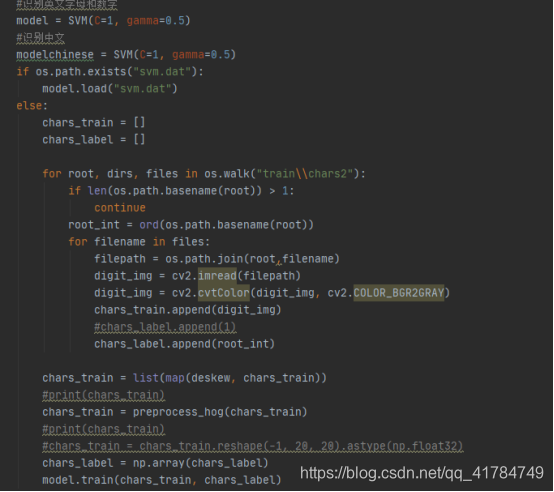

识别过程:
1.先加载之前训练好的模型
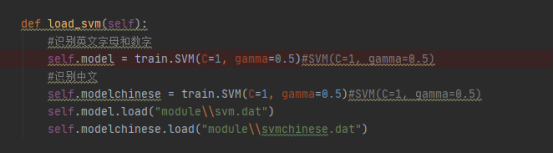
2.遍历所有分割出来的字符图片,调用model.predict(part_card)
依次识别车牌分割出来的所有字符图片
第一个字符调用中文svm识别
其他后续字符调用字母数字svm识别

识别结果:


四、实验结果
部分结果如下:
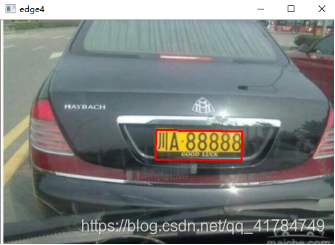


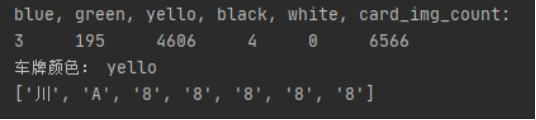
结果:
.






五、总结
目前程序存在一些缺陷,例如,车的颜色,如果本身是蓝色绿色,或者是黄色,则无法通过颜色来确定车牌的位置。训练的数据集有限,识别中文字符时不是很准确等。