Visualize a decision tree two different ways
Prune a decision tree to avoid overfitting
刘建平博客:
sklearn 文档:
API 文档:
sklearn.tree.DecisionTreeClassifier
sklearn.tree.DecisionTreeRegressor
刘建平博客关键句提炼
splitter=random:随机的在部分划分点中找局部最优的划分点max_depth:推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。min_samples_split:这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。min_samples_leaf:限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。- 决策树的数组使用的是numpy的float32类型,如果训练数据不是这样的格式,算法会先做copy再运行。
- 如果输入的样本矩阵是稀疏的,推荐在拟合前调用csc_matrix稀疏化,在预测前调用csr_matrix稀疏化。
ccp_alpha :non-negative float, default=0.0
Complexity parameter used for Minimal Cost-Complexity Pruning. The subtree with the largest cost complexity that is smaller than ccp_alpha will be chosen. By default, no pruning is performed. See Minimal Cost-Complexity Pruning for details.
New in version 0.22.
回归树的criterion有一个friedman_mse的实现
What is the difference between Freidman mse and mse?
it resumes in the fact that this splitting criterion allow us to take the decision not only on how close we’re to the desired outcome (which is what MSE does), but also based on the probabilities of the desired k-class that we’re going to find in the region l or in the region r (by considering a global weight w1*w2 / (w1 + w2)).
这个分裂标准不仅允许我们决定我们离期望结果有多近(MSE就是这么做的),而且还基于我们在区域l或区域r中找到的期望k类的概率(通过考虑全局权重w1*w2/(w1+w2))。
主流程代码:
sklearn.tree._classes.BaseDecisionTree#fit
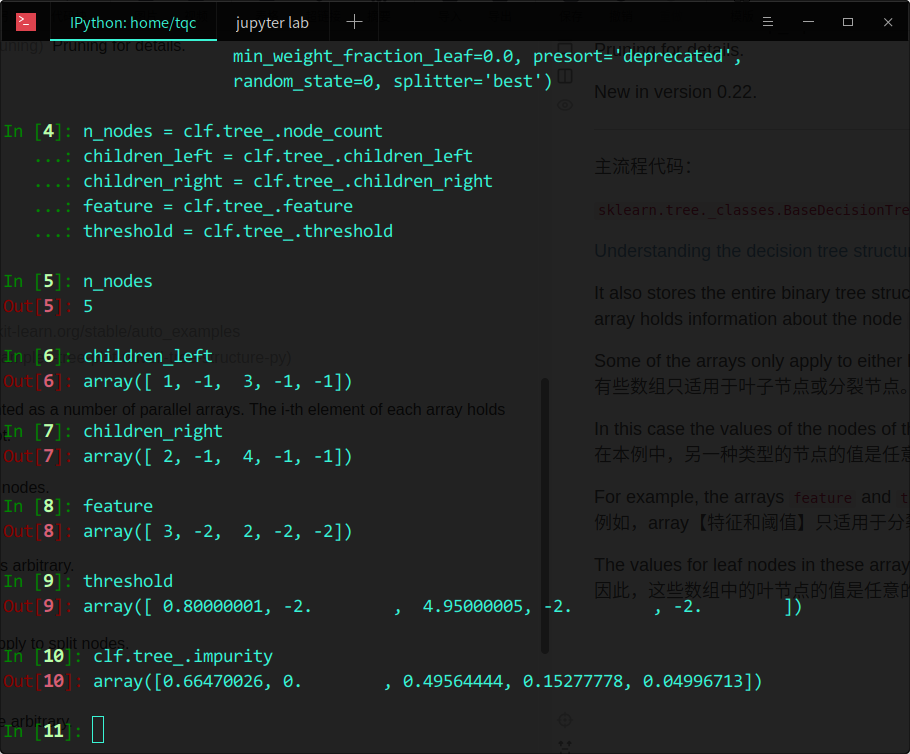
Understanding the decision tree structure
It also stores the entire binary tree structure, represented as a number of parallel arrays. The i-th element of each array holds information about the node i. Node 0 is the tree’s root.
Some of the arrays only apply to either leaves or split nodes.
有些数组只适用于叶子节点或分裂节点。
In this case the values of the nodes of the other type is arbitrary.
在本例中,另一种类型的节点的值是任意的。
For example, the arrays feature and threshold only apply to split nodes.
例如,array【特征和阈值】只适用于分裂节点。
The values for leaf nodes in these arrays are therefore arbitrary.
因此,这些数组中的叶节点的值是任意的。

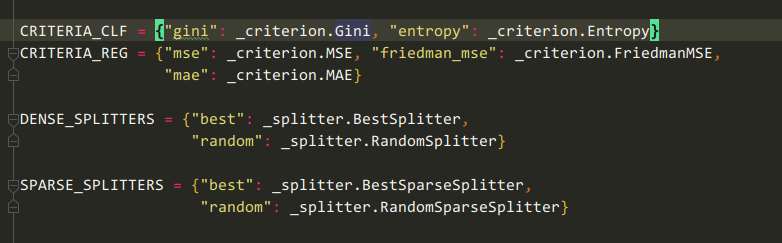
根据criterion和splitter的字符串值取出对应的sklearn.tree._criterion.Criterion和sklearn.tree._splitter.Splitter对象
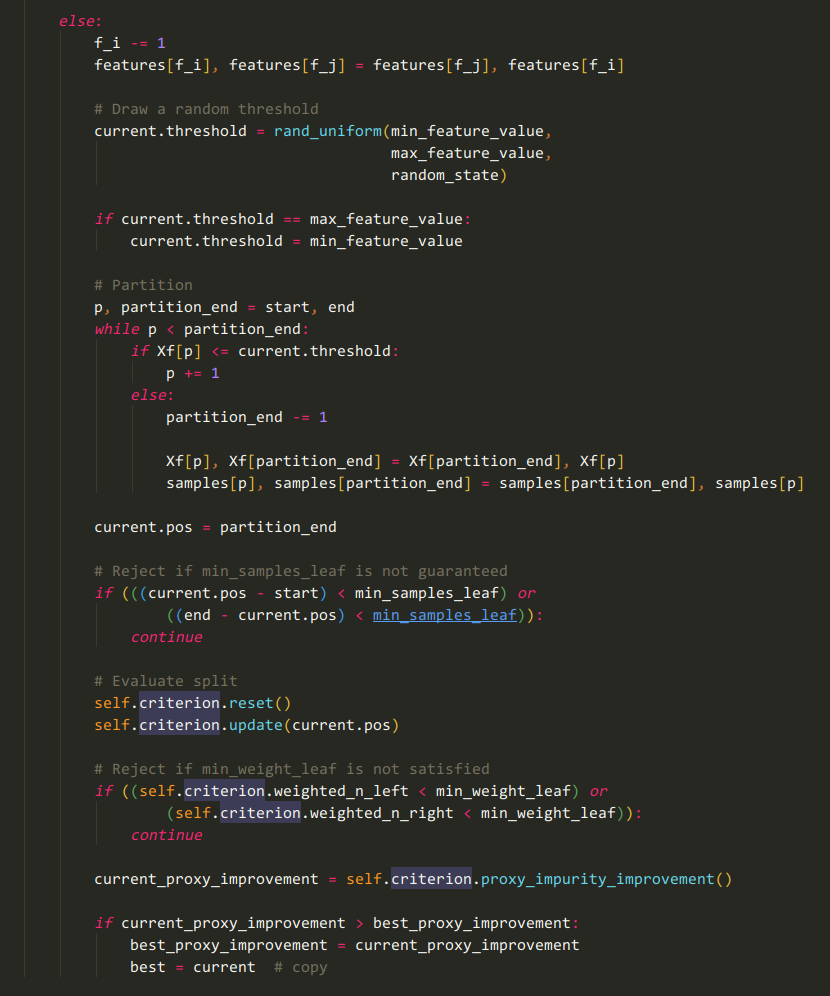
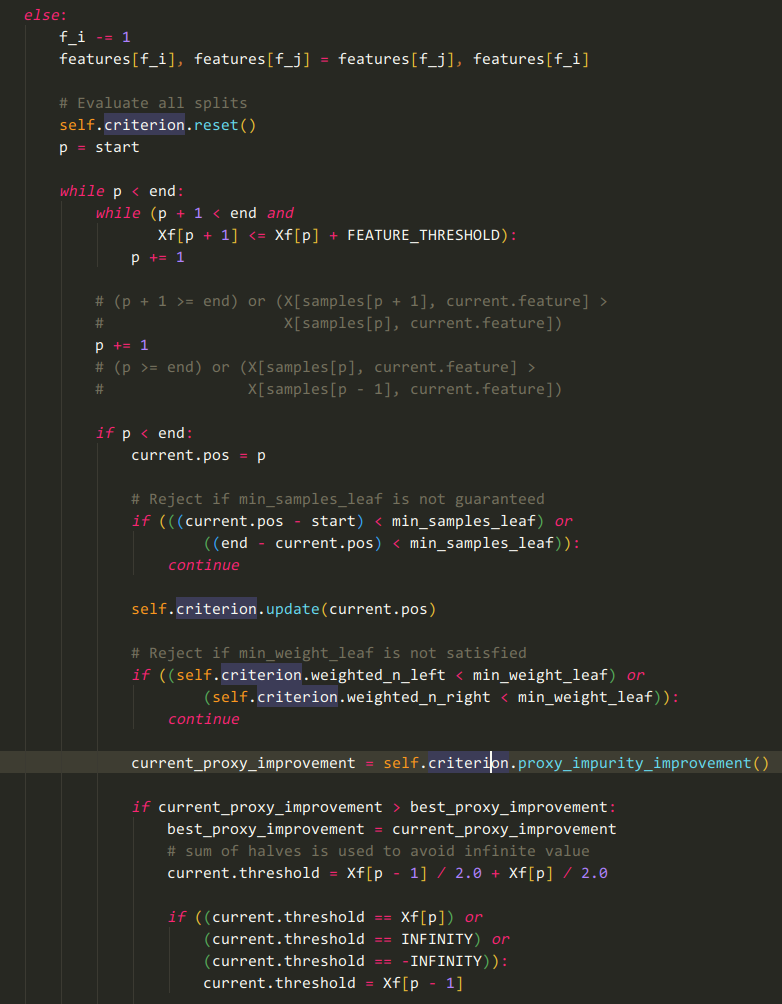
红色代码处应为关键逻辑
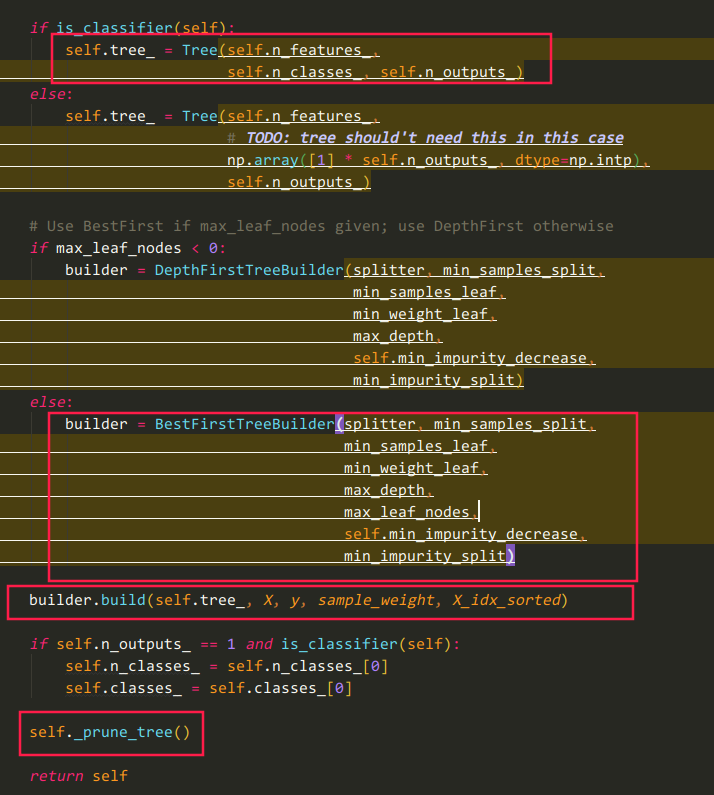
看到build函数的Cython代码
sklearn.tree._tree.BestFirstTreeBuilder#build
cdef PriorityHeap frontier = PriorityHeap(INITIAL_STACK_SIZE)
本质上是一个优先队列的BFS
我猜测不纯度高的节点(所谓的结点本质上就是X的子集)会优先被处理
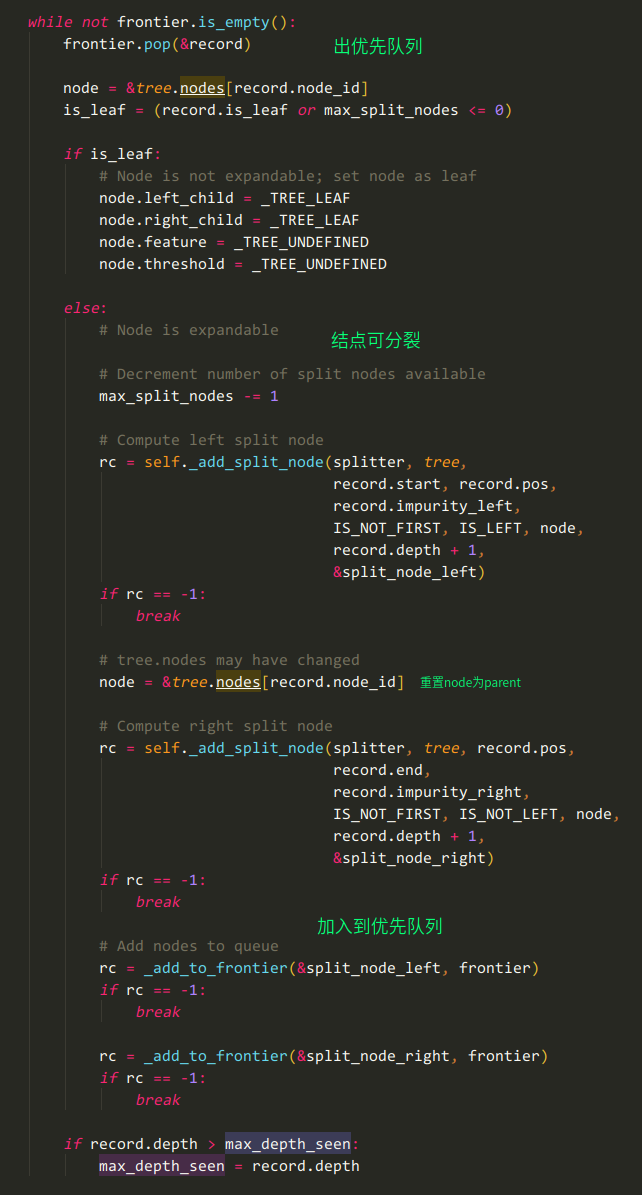
疑问:既然刘建平说RandomSplitter并不是完全随机的,那么在哪里考虑信息增益呢?