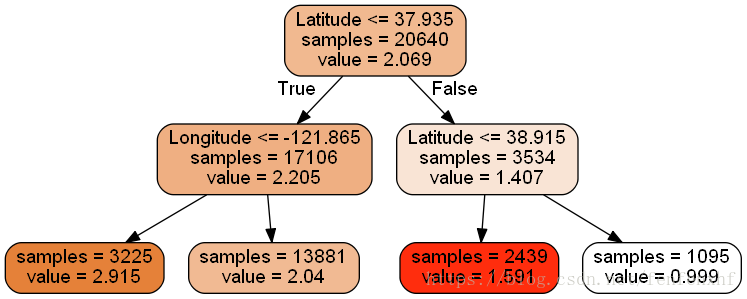
1.可视化树
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import tree
import graphviz #可视化
import pydotplus #画.dot文件
from IPython.display import Image #图片
from sklearn.model_selection import train_test_split #数据集划分为测试集和训练集
from sklearn.datasets.california_housing import fetch_california_housing #sklearn内置的房价的数据集
house = fetch_california_housing()
#print(house.data.shape) #(20640, 8)
dtr = tree.DecisionTreeRegressor(max_depth=2)
dtr.fit(house.data[:,[6,7]],house.target) #指定了第6,7列,fit()传递两个参数X,y
#可视化树
#格式基本上不需要变动,这里生成.dot文件
dot_data = \
tree.export_graphviz(
dtr, #这里是实例的名字
out_file=None,
feature_names=house.feature_names[6:8], #列名
filled= True,
impurity=False,
rounded=True
)
#画树
graph = pydotplus.graph_from_dot_data(dot_data)
graph.get_nodes()[7].set_fillcolor("#FF2DD") #填充颜色
#保存树
graph.write_png(r'C:\\Users\\Administrator\\Desktop\\dtr.png') #保存图片
2.训练数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import tree
import graphviz #可视化
import pydotplus #画.dot文件
from IPython.display import Image #图片
from sklearn.model_selection import train_test_split #数据集划分为测试集和训练集
from sklearn.datasets.california_housing import fetch_california_housing #sklearn内置的房价的数据集
house = fetch_california_housing()
#print(house.data.shape) #(20640, 8)
x_train,x_test,y_train,y_test = train_test_split(house.data,house.target,test_size=0.1,random_state=42)
dtr = tree.DecisionTreeRegressor(random_state=42)
dtr.fit(x_train,y_train)
score = dtr.score(x_test,y_test)
print(score) #0.637318351331017