前言
为公众号收集电影图片素材
使用scrapy图片下载
目标网站
https://film-grab.com/

爬取成果
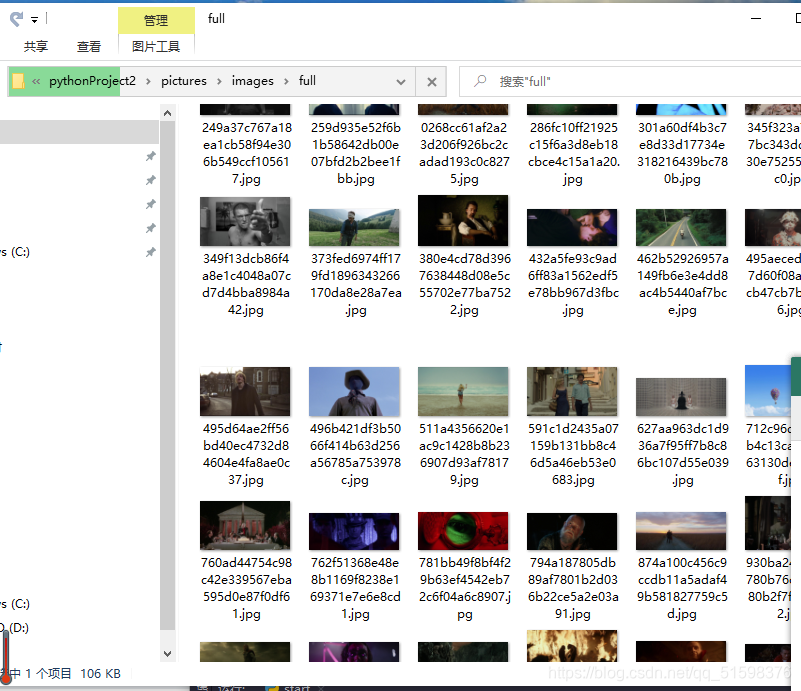
因为已经有了一次爬取成功的基础,再加上这个网站结构跟上个例子差不多,所以很快就达到了目的。
有多快呢
十分钟不到
代码参考
settings.py(已删除多余部分)
BOT_NAME = 'pictures'
SPIDER_MODULES = ['pictures.spiders']
NEWSPIDER_MODULE = 'pictures.spiders'
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
import os
ITEM_PIPELINES = {
#'imagedownload.pipelines.ImagedownloadPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1
}
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
picture.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders.crawl import CrawlSpider,Rule
from scrapy.linkextractors import LinkExtractor
from ..items import PicturesItem
class PictureSpider(CrawlSpider):
name = 'picture'
allowed_domains = ['film-grab.com']
# start_urls = ['http://zcool.com.cn/']
start_urls = ['https://film-grab.com/page/1/']
rules = (
# 翻页的url
Rule(LinkExtractor(allow=r".+film-grab.com/page/\d+"),follow=True),
# 详情页面的url
Rule(LinkExtractor(allow=r"https://film-grab.com/.+"),follow=False,callback="parse_detail")
)
def parse_detail(self, response):
image_urls = response.xpath("//img[@width='1280']/@src").getall()
print(image_urls)
# title_list = response.xpath("//div[@class='details-contitle-box']/h2/text()").getall()
# title = "".join(title_list).strip()
item = PicturesItem(image_urls=image_urls)
yield item
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class PicturesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
pipelines.py默认不变
小结
scrapy真香