爬虫项目实战一:基于Scrapy+MongDB爬取并存储糗事百科用户信息
一、前言
做这个小项目的初衷就是帮助自己初步掌握Scrapy+MongoDB的使用,积累爬虫技术,完成入门。
写这篇总结,也是帮助自己重新梳理这个小项目中遇到的问题以及对学到的一些知识进行总结记录,方便日后查看。
如果你也是爬虫小白,并且也在尝试学习Scrapy框架的话,那么这篇文章可能对你会有所帮助。我会对自己在这个小项目中遇到的所有问题进行一个回顾和总结。尽管最后代码很少,确实也相当简单,但是对于一个小白来说,其中的经历只有自己知道,也许一个小bug就要自己去看几个小时的资料。不过不用担心,我把自己遇到的bug基本都总结了,希望你也能坚持下去,多用Google解决问题,顺利复现我这个小项目。加油,小伙伴!
二、项目目标
项目的主要目的是爬取糗事百科网站上的用户名、用户年龄、用户性别、段子内容、段子好笑数、段子评论数这6个主要的数据信息。
选取这些数据的原因是,通过爬取这些用户信息,有助于我们去分析糗事百科上的用户性别比例、年龄比例以及热门段子等,从中去发现用户行为规律,辅助商业决策,实现数据的价值。当然这些都是后话了。不过一个要有的意识就是:爬取数据不是最终目的,实现数据的价值才是最终目的。因此数据的选取也是前期要认真考量的。
三、项目的环境配置
博主用的是Win10(64)+Pycharm2018版+MongoDB3.4版+Anaconda(Python3.7)版+Robomongo 1.1-Beta
注意:Pycharm如果是学生的话,可以注册免费使用。
Anaconda下载地址
其他软件统一放到网盘里,需要的可以下载 提取码:vpo1
PS:建议先按里面的崔庆才大佬的视频教程,安装和配置好基本的开发环境(Anaconda+Pycharm+MongoDB+Robomongo 1.1-Beta),然后结合里面的Pycharm使用教程,熟悉一下Pycharm的基本使用。再自己按里面的Scrapy框架的基本使用教程练习这个很重要,起码得先大致知道scrapy的每个模块干什么的才行。(视频资源仅供学习使用,如有侵权,请联系,立即删除)
四、项目实现
1. 创建QSBK项目
- 先找到一个合适的的盘,新建一个QSBK的文件夹,–>win+R–>cmd–>打开命令行–>cd到QSBK的目录下。如果是不同盘符,要先换盘符,直接输入盘符名:如(D:),再cd QSBK的路径
- scrapy startproject QSBK # 创建工程

- cd QSBK # 切换到工程目录下,这时注意这时QSBK项目目录下还有一个scrapy.cg文件,这个文件很重要,主要是配置这个项目的基本信息否则爬虫无法运行,不能删除,具体使用可以参照官方文档这也是自己下载别人项目下来,尝试运行过程中遇到的一个坑。
- scrapy genspider QSBKSpider www.qiushibaike.com # 创建QSBKSpider,注意项目名和爬虫名不要一样,否则后面调用可能会报错,这是自己踩过的一个坑。
- scrapy crawl QSBKSpider # 运行爬虫

报错,网页访问失败,原因301。通过之前一篇博客,我们已经知道糗事百科网站设置了验证,需要添加User-Agent字段才可以访问。
所以建议在用scrapy爬取前,可以先用一些requests库在shell里面验证一下, 了解这个网址访问有哪些限制。测试之后再到scrapy里面验证。
所以这里我们需要到setting.py里面去设置 - 用Pycharm打开项目,设置settings.py,启用DEFAULT_REQUEST_HEADERS,并添加User-Agent字段,同时设置不遵守robots协议,即:ROBOTSTXT_OBEY = False

PS:这里可以使用Ctrl+/来快速进行批量注释和取消注释。可以用Ctrl+F来快速查找。
在Pycharm的Terminal终端,再次运行结果,发现状态码变为200,代表成功爬取。

PS:命令行中的历史命令可以通过键盘的上下键来查询,从而不用反复输入同一命令。
2. 实现Spider
1. 实现一页网页上的内容提取
- 在pycharm的Terminal终端输入:scrapy shell https://www.qiushibaike.com/hot/page/1/,进入交互模式。这个功能非常强大,可以帮助我们先测试提取方案的可能性,提取成功我们再写到spider代码里面。要退出,输入quit()回车即可。
- 打开https://www.qiushibaike.com/hot/page/1/,右键检查,可以看到用户信息都放在<div…class=“col1”>…里面的子节点
…标签中,因此我们需要先把所有包含用户信息的div标签提取出来。这里我选用的是scrapy中的xpath选择器,至于为什么没有选用re来匹配,后面我会再写一篇文章总结。
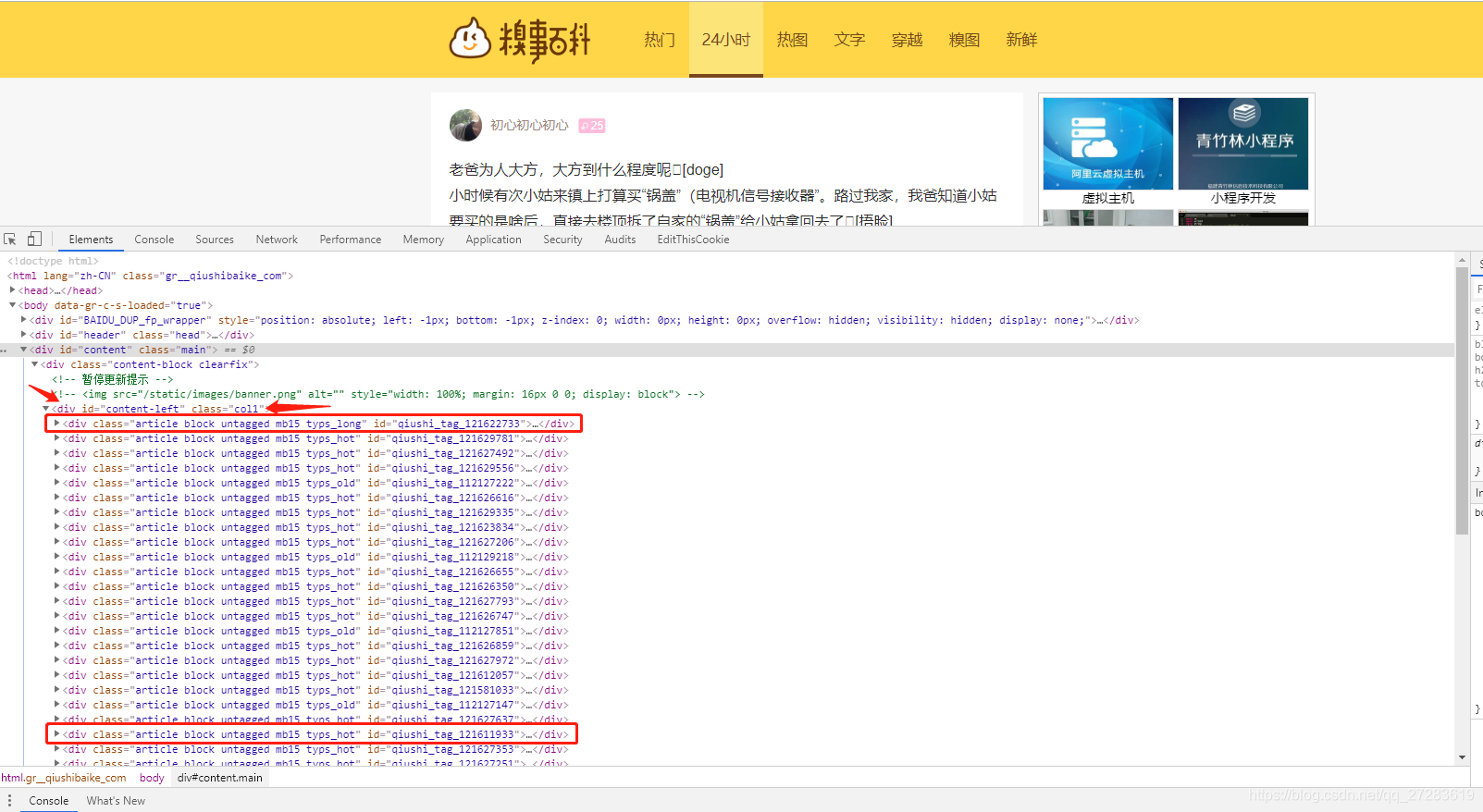
这里用到的xpath知识:
//div:表示跳级选取
/:表示根目录选取
.:表示当前节点
./div:表示当前节点的div子节点 - 选取所有用户信息div标签

- 对用户信息div标签进行迭代,提取相应信息
打开div标签,发现用户名/性别/年龄等信息在第一个子节点div标签中,用户评论在第一个子节点a标签中,好笑数和评论数在<div 属性class="stats"的标签中。
所以依次分别提取即可。代码如下:
# 依次迭代每个tag,进行信息提取
for user in users:
item = DuanZi()
# 因为存在匿名用户,所以需要分类判断
if user.xpath('./div/a/h2/text()').get():
# 获取用户名
user_name = user.xpath('./div/a/h2/text()').get().strip()
# 获取用户年龄
user_age = user.xpath('./div/div/text()').get().strip()
# 获取用户性别
user_gender = user.xpath('./div/div/@class').get().strip().split()[1][:-4]
# 获取用户段子
user_content = ''.join(user.xpath('./a/div[@class="content"]/span/text()').getall())
# 获取好笑数
laught_number = user.xpath('./div[@class="stats"]/span/i/text()').get().strip()
# 获取评论数
comment_number = user.xpath('./div[@class="stats"]/span/a/i/text()').get().strip()
else:
# 获取匿名用户名
user_name = user.xpath('./div/span/h2/text()').get().strip()
# 匿名用户age设为None
user_age = None
# 匿名用户gender设为None
user_gender = None
# 获取用户段子
user_content = ''.join(user.xpath('./a/div[@class="content"]/span/text()').getall())
# 获取好笑数
laught_number = user.xpath('./div[@class="stats"]/span/i/text()').get().strip()
# 获取评论数
comment_number = user.xpath('./div[@class="stats"]/span/a/i/text()').get().strip()
这里用到的xpath知识:
user.xpath(’./div/a/h2/text()’).get():这是提取当前节点下的div标签下的a标签下的h2标签下的文本信息。
user.xpath(’./div/div/@class’).get():这是提取当前节点下的div标签下的div标签下class的属性信息。
user.xpath(’./div[@class=“stats”]:这是选取当前节点下div标签中属性是class="stats"的div标签。
get()和getall()方法分别是返回第一个,和返回所有匹配的列表。具体方法,可以参考官方文档.
Ps:其实这里自己一开始遇到了坑, 因为一开始没有注意到匿名用户,导致一遇到匿名用户,程序就中断了。后来发现匿名用户的信息跟非匿名用户不一样,这里的策略引入判断,分类对待。
2. 实现翻页
因为该网站,网页非常有规律,就是1、2、3…这样的顺序。一开始想用直接从网页中提取,然后递归调用parse来实现,翻页后来发现,提取时规律性不强。考虑到只有13页,所以就采用自己构造url的方式。
引入公有属性i,从而实现。这里要注意公有属性i不能放入parse()中,如果在parse()中的就变为了局部变量,每次调用都会初始化为1,所以会导致只能爬取1、2两页,然后程序就结束。这也是一开始自己遇到的坑之一。
self.i += 1
url = 'https://www.qiushibaike.com/hot/page/' + str(self.i)
yield scrapy.Request(url=url, callback=self.parse)
3. 实现items
这部分相对简单,需要哪些数据,就加进去就可以了。同时注意spider也要配置好。
import scrapy
# 定义要储存的字段
class DuanZi(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
page = scrapy.Field()
user_name = scrapy.Field()
user_age = scrapy.Field()
user_gender = scrapy.Field()
user_content = scrapy.Field()
laught_number = scrapy.Field()
comment_number = scrapy.Field()
这里要注意:如果改了items的名字一定要在spider里面进行导入。不然会报错说找不到DuanZi模块。
# 导入DuanZi
from QSBK.items import DuanZi
4. 设置pipelins用MongoDB存储数据
这部分在视频教程里面讲的比较清楚,在官方文档也很详细,基本可以套用,这里就直接上代码了。稍微注意一下要settings里面要启用ITEM_PIPELINES,pipelines才能生效。
# 导入pymongo
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri = crawler.settings.get('MONGO_URI'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
name = item.__class__.__name__
self.db['qsbk'].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
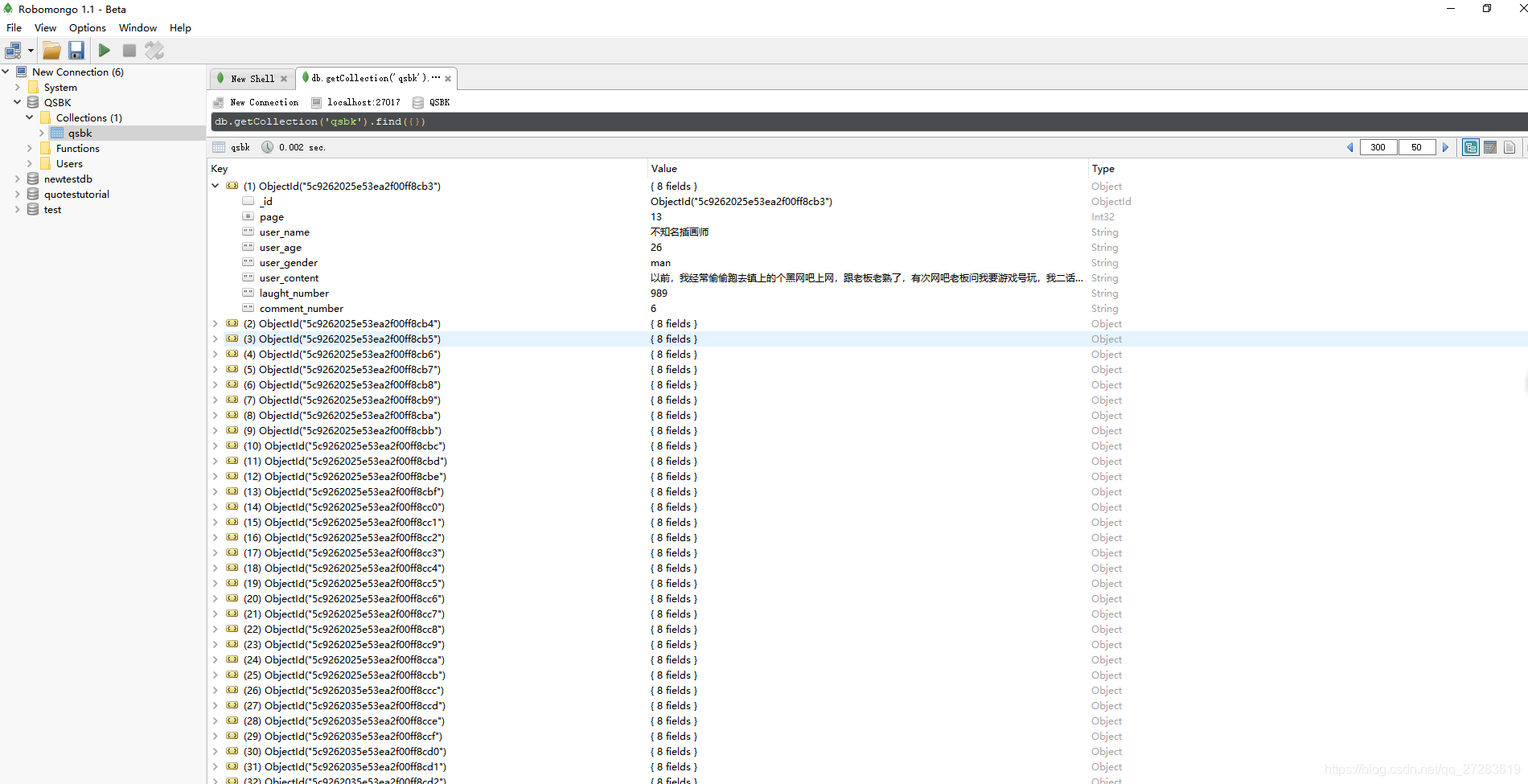
结果输出
五、项目总结
1. 项目优点
基本上实现了一开始自己设定的目标,爬取并存储了需要的信息,对比了一下数据,基本上没有发现错误。同时爬取的速度也还是比较快的。代码逻辑也较为清楚。
2. 项目不足
1) 因为糗事百科是动态更新的,一次性抓取的数据只有350条,这个样本量太小。如何实现动态抓取,做到每隔一段时间自动抓取一次,从而不断的累计数据。
2) 数据库中的数据去重问题,不断抓取的过程中,数据难免有重复,这个去重问题怎么实现?需要继续学习数据库的处理知识。
3) 数据抓取过来了,后续如何继续处理分析,如何作图,辅助我们做出决定。这方面还需要继续去研究。