背景
上一次,我们浏览了play_game函数,并看到了MuZero如何决定每个回合中的下一个最佳动作。我们还更详细地探讨了MCTS流程。
在这篇文章中,我们将了解MuZero的训练过程,并了解其试图将损失函数减至最小的程度。
我将总结为什么我认为MuZero是AI的重大进步及其对该领域未来的影响的总结。
train network
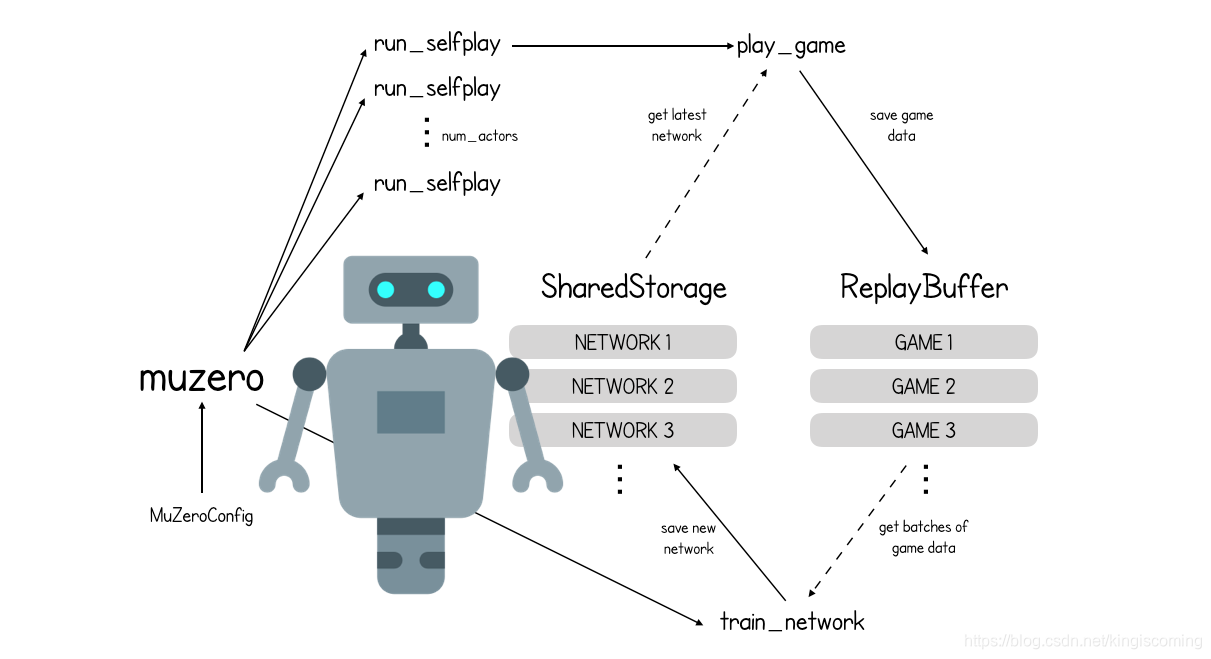
原始入口点函数的最后一行(还记得第1部分中的内容)启动了train_network使用来自重播缓冲区的数据连续训练神经网络的过程。
def train_network(config: MuZeroConfig, storage: SharedStorage,
replay_buffer: ReplayBuffer):
network = Network()
learning_rate = config.lr_init * config.lr_decay_rate**(
tf.train.get_global_step() / config.lr_decay_steps)
optimizer = tf.train.MomentumOptimizer(learning_rate, config.momentum)
for i in range(config.training_steps):
if i % config.checkpoint_interval == 0:
storage.save_network(i, network)
batch = replay_buffer.sample_batch(config.num_unroll_steps, config.td_steps)
update_weights(optimizer, network, batch, config.weight_decay)
storage.save_network(config.training_steps, network)
它首先创建一个新Network对象(存储随机初始化的MuZero的三个神经网络实例),然后根据已完成的训练步骤数将学习率设置为递减。我们还创建了梯度下降优化器,它将在每个训练步骤中计算重量更新的大小和方向。
该函数的最后一部分只是循环training_steps(对于国际象棋,纸张等于1,000,000)。在每个步骤中,它都会从重播缓冲区中采样一批位置,并使用它们来更新网络,然后将其保存到checkpoint_interval每批存储中(= 1000)。
因此,我们需要涉及两个决赛部分-MuZero如何创建一批训练数据以及如何使用它来更新三个神经网络的权重。
创建训练批次
ReplayBuffer类包含一种sample_batch从缓冲区中采样一批观察值的方法:
class ReplayBuffer(object):
def __init__(self, config: MuZeroConfig):
self.window_size = config.window_size
self.batch_size = config.batch_size
self.buffer = []
def sample_batch(self, num_unroll_steps: int, td_steps: int):
games = [self.sample_game() for _ in range(self.batch_size)]
game_pos = [(g, self.sample_position(g)) for g in games]
return [(g.make_image(i), g.history[i:i + num_unroll_steps],
g.make_target(i, num_unroll_steps, td_steps, g.to_play()))
for (g, i) in game_pos]

您可能想知道为什么每次观察都需要采取多种未来措施。原因是我们需要训练动态网络,而这样做的唯一方法是在小的顺序数据流上进行训练。
对于批次中的每个观察,我们将num_unroll_steps使用提供的操作将位置“展开”到将来。对于初始职位,我们将使用该initial_inference功能预测价值,奖励和政策,并将其与目标价值,目标奖励和目标政策进行比较。对于后续操作,我们将使用该recurrent_inference功能预测价值,奖励和政策,并将其与目标价值,目标奖励和目标政策进行比较。这样,在预测过程中将使用所有三个网络,因此将更新所有三个网络中的权重。
现在让我们更详细地了解目标的计算方式。
class Game(object):
"""A single episode of interaction with the environment."""
def __init__(self, action_space_size: int, discount: float):
self.environment = Environment() # Game specific environment.
self.history = []
self.rewards = []
self.child_visits = []
self.root_values = []
self.action_space_size = action_space_size
self.discount = discount
def make_target(self, state_index: int, num_unroll_steps: int, td_steps: int,
to_play: Player):
# The value target is the discounted root value of the search tree N steps
# into the future, plus the discounted sum of all rewards until then.
targets = []
for current_index in range(state_index, state_index + num_unroll_steps + 1):
bootstrap_index = current_index + td_steps
if bootstrap_index < len(self.root_values):
value = self.root_values[bootstrap_index] * self.discount**td_steps
else:
value = 0
for i, reward in enumerate(self.rewards[current_index:bootstrap_index]):
value += reward * self.discount**i # pytype: disable=unsupported-operands
if current_index < len(self.root_values):
targets.append((value, self.rewards[current_index],
self.child_visits[current_index]))
else:
# States past the end of games are treated as absorbing states.
targets.append((0, 0, []))
return targets
...
该make_target函数使用TD学习中的思想来计算从state_index到的每个状态的目标值state_index + num_unroll_steps。变量current_index.
TD学习是强化学习中的一种常用技术,其思想是,我们可以使用td_steps在不久的将来头寸的估计折现价值加上到那时的折现奖励来更新状态的价值,而不仅仅是使用剧集结束前获得的总折扣奖励。
当我们基于估算值更新估算值时,我们说的是自举。这bootstrap_index是td_steps我们将用来估计未来真实回报的未来头寸指数。
该函数首先检查bootstrap_index情节结束之后是否。如果是,value则将其设置为0,否则value将其设置为位置的折现预测值bootstrap_index。
然后,在current_index和之间产生的折扣奖励bootstrap_index会加到上value。

现在,我们已经了解了目标的构建方式,可以看到它们如何适合MuZero损失函数,最后,可以看到它们如何在update_weights函数中用于训练网络。
MuZero损失函数
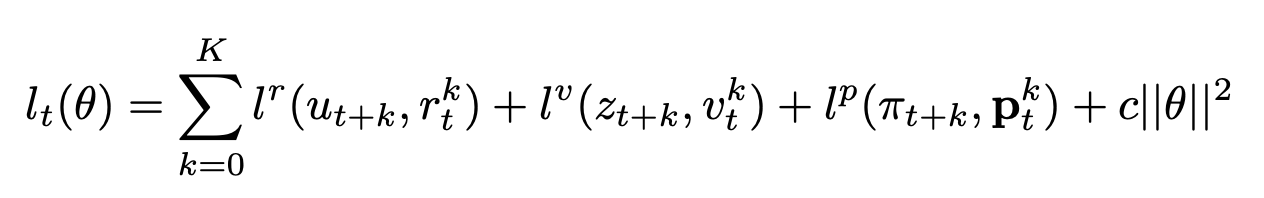
在这里,K是num_unroll_steps变量。换句话说,我们正在尝试将三种损失减至最小:
- 他的预测奖励k步的t ®与实际奖励(u)的区别。
- 他的预测奖励k步的t ®与TD目标奖励(Z)的区别。
- 他的预测奖励k步的policy t §与MCTS policy(pi)的区别。
将这些损失汇总到卷展栏上,以生成批次中给定位置的损失。还有一个规范化术语可以惩罚网络中的较大权重。

更新三个MuZero网络(update_weights)
def update_weights(optimizer: tf.train.Optimizer, network: Network, batch,
weight_decay: float):
loss = 0
for image, actions, targets in batch:
# Initial step, from the real observation.
value, reward, policy_logits, hidden_state = network.initial_inference(
image)
predictions = [(1.0, value, reward, policy_logits)]
# Recurrent steps, from action and previous hidden state.
for action in actions:
value, reward, policy_logits, hidden_state = network.recurrent_inference(
hidden_state, action)
predictions.append((1.0 / len(actions), value, reward, policy_logits))
hidden_state = tf.scale_gradient(hidden_state, 0.5)
for prediction, target in zip(predictions, targets):
gradient_scale, value, reward, policy_logits = prediction
target_value, target_reward, target_policy = target
l = (
scalar_loss(value, target_value) +
scalar_loss(reward, target_reward) +
tf.nn.softmax_cross_entropy_with_logits(
logits=policy_logits, labels=target_policy))
loss += tf.scale_gradient(l, gradient_scale)
for weights in network.get_weights():
loss += weight_decay * tf.nn.l2_loss(weights)
optimizer.minimize(loss)
第一初步观察通过传递initial_inference网络来预测value,reward和policy从当前位置。这些用于创建predictions列表以及给定的权重1.0。
然后,每个动作都依次挂绕和recurrent_inference功能被要求预测下一个value,reward并且policy从目前的hidden_state。这些predictions以权重1/num_rollout_steps()附加到列表中(以便使该recurrent_inference功能的总权重等于该功能的总权重initial_inference)。
然后,我们计算出比较流失predictions到其对应的目标值-这是一个组合scalar_loss的reward和value和softmax_crossentropy_loss_with_logits的policy。
然后,优化程序使用此损失函数来同时训练所有三个MuZero网络。
因此,这就是使用Python训练MuZero的方式。
Reanalyse
正常训练

我们有两组彼此异步通信的作业:
- 接收最新轨迹的学习者,将最新轨迹保存在重播缓冲区中,并使用它们执行上述训练算法。
- 多个参与者定期从学习者那里获取最新的网络检查点,并使用MCTS中的网络选择动作并与环境进行交互以生成轨迹。
为了实施重新分析,我们引入了两个工作:

- 一个重新分析缓冲接收由演员生成的所有轨迹,并保持最近的版本。
- 多个重新分析参与者 6从重新分析缓冲区中采样存储的轨迹,使用学习者的最新网络检查点重新运行MCTS,并将生成的轨迹和更新的搜索统计信息发送给学习者。
对于学习者来说,“新鲜的”和重新分析的轨迹是无法区分的。这使得更改新鲜轨迹与重新分析轨迹的比例非常简单。
reference
muzero-mastering-go-chess-shogi-and-atari-without-rules
Mastering Atari, Go, chess and shogi by planning with a learned model
how-to-build-your-own-deepmind-muzero-in-python
muzero-intuition