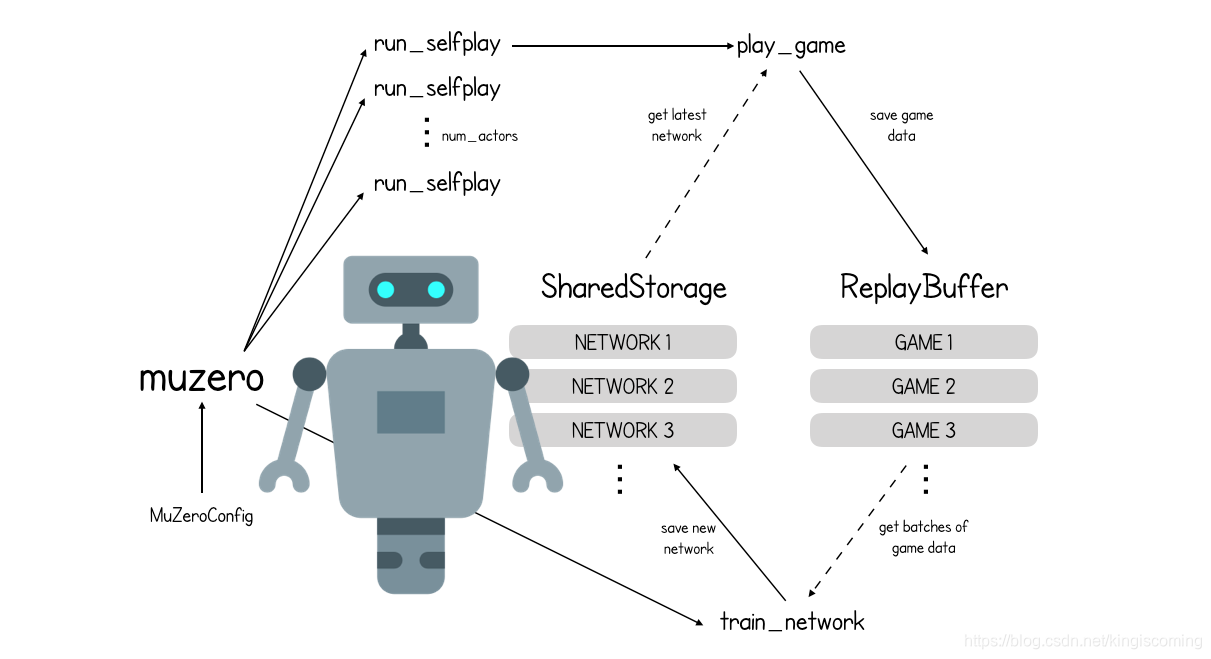
背景
上次,我们介绍了MuZero,并看到了它与AlphaZero有何不同。
在没有国际象棋的规则实际,MUZERO CRE一个TES新游戏的脑子里面,它可以控制和使用该计划未来。一起优化了这三个网络(预测,动态和表示),以使在设想的环境中表现良好的策略在实际环境中也表现良好。
在本文中,我们将play_game逐步介绍该功能,并查看MuZero如何决定每个转弯处的下一个最佳动作。
在没有国际象棋的实际规则的情况下,MuZero会在自己的脑海中创建一个新游戏,它可以控制并使用它来计划未来。一起优化了这三个网络(预测,动态和表示),以使在设想的环境中表现良好的策略在实际环境中也表现良好。
Playing a game with MuZero (play_game)
# Each game is produced by starting at the initial board position, then
# repeatedly executing a Monte Carlo Tree Search to generate moves until the end
# of the game is reached.
def play_game(config: MuZeroConfig, network: Network) -> Game:
game = config.new_game()
while not game.terminal() and len(game.history) < config.max_moves:
# At the root of the search tree we use the representation function to
# obtain a hidden state given the current observation.
root = Node(0)
current_observation = game.make_image(-1)
expand_node(root, game.to_play(), game.legal_actions(),
network.initial_inference(current_observation))
add_exploration_noise(config, root)
# We then run a Monte Carlo Tree Search using only action sequences and the
# model learned by the network.
run_mcts(config, root, game.action_history(), network)
action = select_action(config, len(game.history), root, network)
game.apply(action)
game.store_search_statistics(root)
return game
首先,Game创建一个新对象并开始主游戏循环。当达到终止条件或移动次数长于允许的最大值时,游戏结束。
我们从根节点开始MCTS树。
root = Node(0)
每个节点都存储与访问次数相关的关键统计信息,访问次数visit_count,谁出手to_play,选择导致该节点的动作的预测先验概率prior的回填值总和node_sum,其子节点children,隐藏状态hidden_state并通过移动到此节点获得预期的奖励reward。
class Node(object):
def __init__(self, prior: float):
self.visit_count = 0
self.to_play = -1
self.prior = prior
self.value_sum = 0
self.children = {}
self.hidden_state = None
self.reward = 0
def expanded(self) -> bool:
return len(self.children) > 0
def value(self) -> float:
if self.visit_count == 0:
return 0
return self.value_sum / self.visit_count
接下来,我们要求游戏返回当前的观测值(对应o于上图中)…
current_observation = game.make_image(-1)
…并使用游戏提供的已知合理行动以及该initial_inference功能提供的有关当前观察的推论来扩展根节点
expand_node(root,game.to_play(),game.legal_actions(),
network.initial_inference(current_observation))
# We expand a node using the value, reward and policy prediction obtained from
# the neural network.
def expand_node(node: Node, to_play: Player, actions: List[Action],
network_output: NetworkOutput):
node.to_play = to_play
node.hidden_state = network_output.hidden_state
node.reward = network_output.reward
policy = {a: math.exp(network_output.policy_logits[a]) for a in actions}
policy_sum = sum(policy.values())
for action, p in policy.items():
node.children[action] = Node(p / policy_sum)
我们还需要在根节点动作中添加探索噪声-这对于确保MCTS探索一系列可能的动作而不是仅探索其当前认为最佳的动作非常重要。对于国际象棋,root_dirichlet_alpha= 0.3
add_exploration_noise(config, root)
# At the start of each search, we add dirichlet noise to the prior of the root
# to encourage the search to explore new actions.
def add_exploration_noise(config: MuZeroConfig, node: Node):
actions = list(node.children.keys())
noise = numpy.random.dirichlet([config.root_dirichlet_alpha] * len(actions))
frac = config.root_exploration_fraction
for a, n in zip(actions, noise):
node.children[a].prior = node.children[a].prior * (1 - frac) + n * frac
现在,我们开始主要的MCTS流程,我们将在下一部分中介绍。
run_mcts(config,root,game.action_history(),network)
MuZero中的Monte Carlo搜索树(run_mcts)
# Core Monte Carlo Tree Search algorithm.
# To decide on an action, we run N simulations, always starting at the root of
# the search tree and traversing the tree according to the UCB formula until we
# reach a leaf node.
def run_mcts(config: MuZeroConfig, root: Node, action_history: ActionHistory,
network: Network):
min_max_stats = MinMaxStats(config.known_bounds)
for _ in range(config.num_simulations):
history = action_history.clone()
node = root
search_path = [node]
while node.expanded():
action, node = select_child(config, node, min_max_stats)
history.add_action(action)
search_path.append(node)
# Inside the search tree we use the dynamics function to obtain the next
# hidden state given an action and the previous hidden state.
parent = search_path[-2]
network_output = network.recurrent_inference(parent.hidden_state,
history.last_action())
expand_node(node, history.to_play(), history.action_space(), network_output)
backpropagate(search_path, network_output.value, history.to_play(),
config.discount, min_max_stats)
由于MuZero不了解环境规则,因此也不了解在整个学习过程中可能获得的奖励范围。MinMaxStats创建该对象是为了存储有关当前遇到的最小和最大奖励的信息,以便MuZero可以相应地标准化其值输出。替代地,这也可以用诸如国际象棋(-1,1)的游戏的已知界限来初始化。
主MCTS循环进行迭代num_simulations,其中一种模拟是通过MCTS树,直到到达叶节点(即,未探索的节点)并随后进行反向传播。现在让我们进行一次模拟。
首先,history使用从游戏开始至今已执行的动作列表对进行初始化。当前node是root节点,并且search_path仅包含当前节点。
首先,history使用从游戏开始至今已执行的动作列表对进行初始化。当前node是root节点,并且search_path仅包含当前节点。
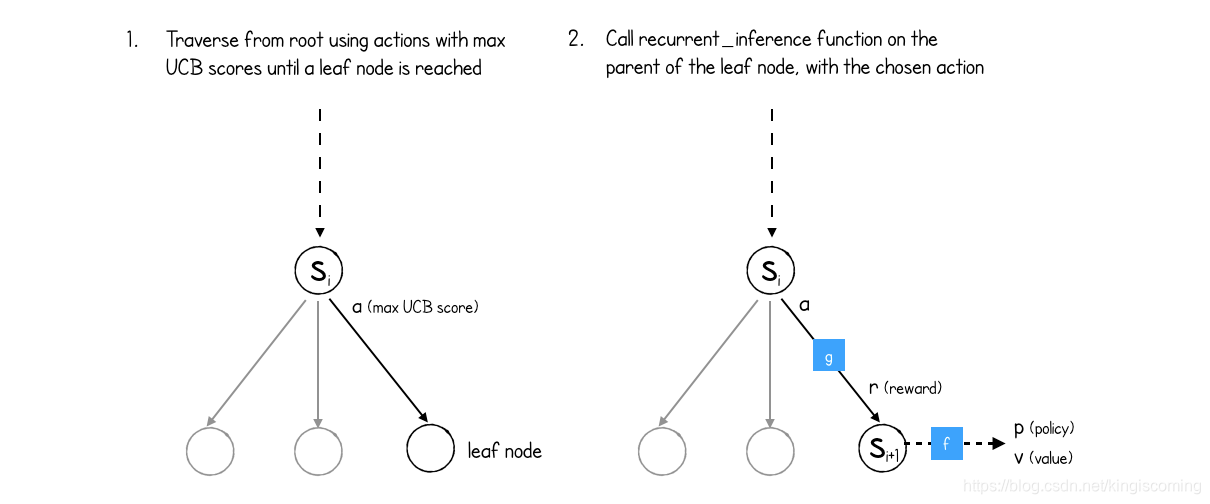
MuZero首先遍历MCTS树,始终选择具有最高UCB(最高可信度)分数的动作:
# Select the child with the highest UCB score.
def select_child(config: MuZeroConfig, node: Node,
min_max_stats: MinMaxStats):
_, action, child = max(
(ucb_score(config, node, child, min_max_stats), action,
child) for action, child in node.children.items())
return action, child
UCB评分是一种平衡Q(s,a)和根据先前选择动作的可能性P(s,a)的和已经选择动作N(s,a)的估计值和探索奖金的量度。
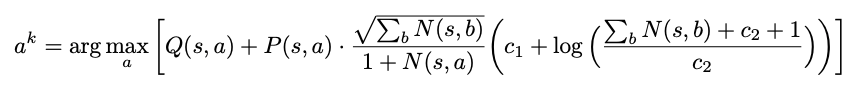
在模拟的早期,勘探奖金占主导地位,但是随着模拟总数的增加,价值术语变得更加重要。
最终,该过程将到达叶节点(一个尚未扩展的节点,因此没有子节点)。
此时recurrent_inference,在叶节点的父节点上调用该函数,以便获得预测的奖励和新的隐藏状态(来自动力学网络)以及新的隐藏状态的策略和值(来自预测网络)。
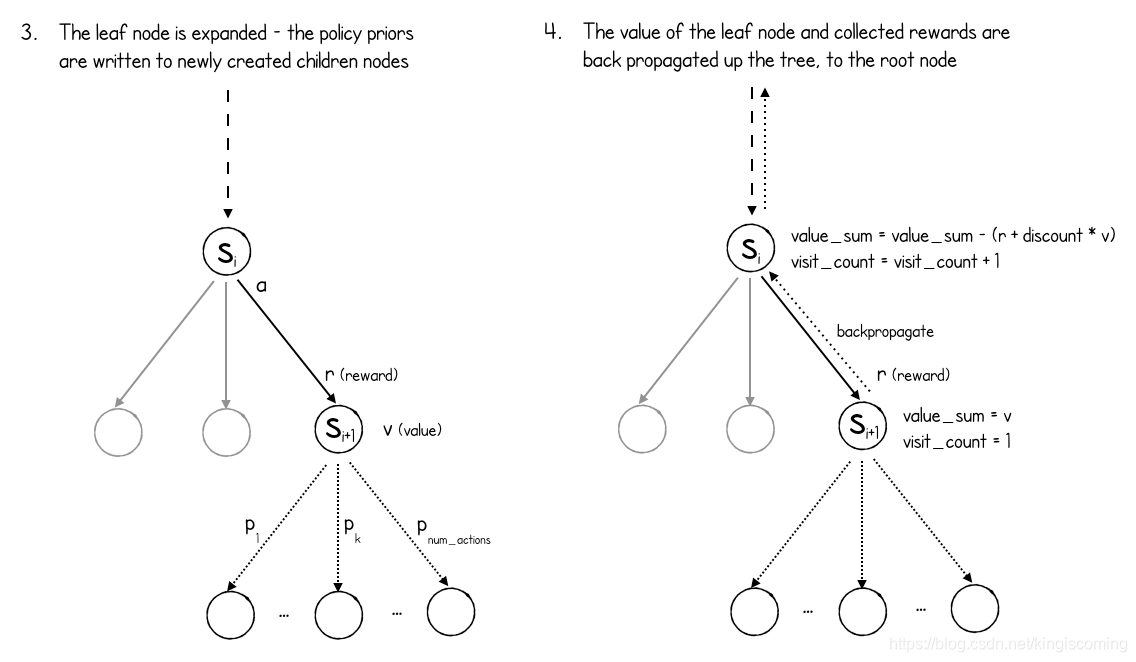
如上图所示,现在通过创建新的子节点(游戏中每个可能的动作一个)并为每个节点分配相应的策略来扩展叶节点。请注意,MuZero不会检查其中哪些动作合法,也不会检查该动作是否导致游戏结束(不能),因此请为每个动作创建一个节点,无论该动作是否合法。
最后,网络预测的值沿着搜索路径沿树反向传播。
def backpropagate(search_path: List[Node], value: float, to_play: Player,
discount: float, min_max_stats: MinMaxStats):
for node in search_path:
node.value_sum += value if node.to_play == to_play else -value
node.visit_count += 1
min_max_stats.update(node.value())
value = node.reward + discount * value
请注意,值是如何翻转的,具体取决于轮到谁(如果叶子节点对要进行游戏的玩家为正,对其他玩家为负)。而且,由于预测网络预测了未来的价值,因此在搜索路径上收集的奖励将被收集并添加到折价的叶节点值上,因为该值将传播回树上。
请记住,由于这些是预测的奖励,而不是来自环境的实际奖励,因此即使对于象棋这样的游戏,奖励的收集也很重要,在象棋这样的游戏中,只有在游戏结束时才奖励真正的奖励。MuZero正在玩自己想像的游戏,其中可能包括过渡性奖励,即使模仿的游戏没有。
这样就完成了对MCTS流程的模拟。
后num_simulations通过树,该过程停止,并且基于所述根的每个子节点已被访问的次数。
def select_action(config: MuZeroConfig, num_moves: int, node: Node,
network: Network):
visit_counts = [
(child.visit_count, action) for action, child in node.children.items()
]
t = config.visit_softmax_temperature_fn(
num_moves=num_moves, training_steps=network.training_steps())
_, action = softmax_sample(visit_counts, t)
return action
def visit_softmax_temperature(num_moves, training_steps):
if num_moves < 30:
return 1.0
else:
return 0.0 # Play according to the max.
对于前30个动作,softmax暂时设置为1,这意味着每个动作的选择概率与它被访问的次数成正比。从第30步开始,选择访问次数最多的操作。
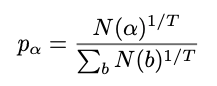
softmax_sample:从根节点选择操作“ alpha”的概率(N为访问次数)
尽管访问次数可能会感觉到选择最终操作的奇怪指标,但事实并非如此,因为MCTS流程中的UCB选择标准旨在最终花费更多时间探索那些认为确实是高价值机会的操作,一旦在此过程的早期就充分探索了替代方案。
然后将所选操作应用于真实环境,并将相关值附加到 game目的。
- game.rewards -在游戏的每个回合中收到的真实奖励的列表
- game.history -游戏每回合采取的行动清单
- game.child_visits —游戏每回合从根节点开始的动作概率分布列表
- game.root_values —游戏每回合的根节点值列表
这些列表很重要,因为它们最终将用于构建神经网络的训练数据!
此过程继续进行,直到每局从头开始创建新的MCTS树,并使用它来选择动作。
所有游戏数据(rewards,history,child_visits,root_values)保存到重传缓冲器和actor是那么自由地开始新的游戏。
reference
muzero-mastering-go-chess-shogi-and-atari-without-rules
Mastering Atari, Go, chess and shogi by planning with a learned model
how-to-build-your-own-deepmind-muzero-in-python