我们已经知道了在我们的代码中,在一个地方定义为指针,那么在声明的时候也要用指针;在一个地方声明定义用了数组,那么在声明的时候也要用数组。
1、数组与指针的对比:
指针用来保存数据的地址,任何存入指针变量p的数据都会被当作地址来处理。p本身的地址由编译器另外储存。存储在哪里,我们并不知道,间接访问数据,首先取得指针变量p的内容,把它作为地址,用来写入或者读取数据。用于动态数据结构,通常指向匿名数据。
数组用来保存数据,数组名a代表数组首元素的首地址而不是数组的首地址,&a才是数组的首地址,a的地址由编译器另外存储。数组直接访问数据,数组名a是整个数组的名字,数组元素没有名字,只能通过“具名+匿名”的方式来访问某个元素。可以以下标的形式访问,也可以以指针的形式访问,其本质是a所代表的数组首元素de 地址加上i*sizeof(类型)个字节,作为元素真正的地址。
2、指针数组与数组指针:
指针数组:首先它是一个数组,数组元素都是指针,数组占多少字节由数组本身决定。是存储数组的指针。
int *p[10]//指针数组
因为与[]的优先级是一样的,结合从右到左,构成了一个数组,int是修饰数组的内容。
数组指针:首先它是一个指针,它指向一个数组,在32为系统下永远是4个字节,是指向数组的指针。
int (*p)[10];//数组指针
通过()改变了优先级,p先与*结合,构成以一个指针,int修饰的是数组的内容,数组在这里没有名字,是匿名数组,即p是一个指针,它指向的是一个包含十个int类型的数组。
3、二维数组和二级指针
由于内存是线性的,所以二维数组的布局为:
char[3][4]
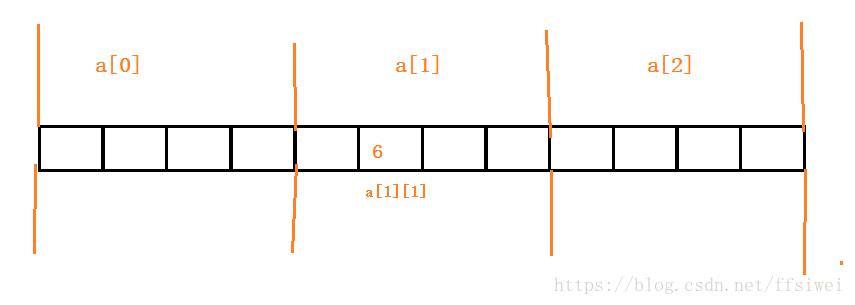
编译器总是将二维数组当作一维数组处理,而一维数组每个元素 又是一个一维数组。所以a[3]这个数组中的元素为a[0]a[1]a[3],这三个元素的首地址分别为:&a[0],&a[0]+1*sizeof(char)*4,&a[0]+2*sizeof(char)*4,,现在考虑a[i]中的内容,a[i]里面有四个char类型的元素,其中每个元素的首地址为:&a[i],&a[i]+1*sizeof(char),&a[i]+2*sizeof(char),&a[i]+3*sizeof(char),所以a[i][j]的首地址为&a[i]+j*sizeof(char),也就是a+1*sizeof(char);
二级指针的内存布局:
char **p;
定义了一个二级指针变量p,保存的是一级指针的地址。
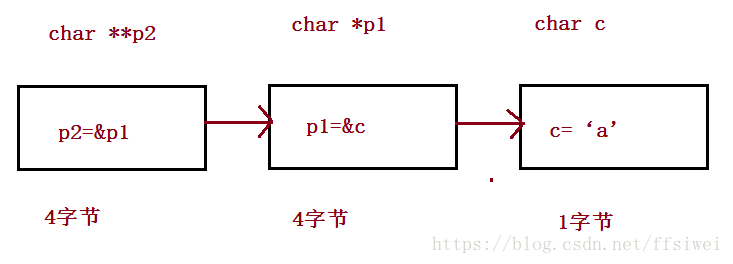
那么怎么使用呢?
一、根据p这个变量,取出它里面的地址;
二、找到这个地址所在的内存;
三、打开这块内存,取出它里面的地址,也就是*p
四、找到第二次取出的地址;
五、打开这块内存,取出它的真正内容,这才是真正的数据**p的值。
4、数组参数与指针参数:
一维数组参数,无法向一个函数传递一个数组,原因是因为当一维数组作为函数参数时,编译器总把它解析为一个指向其首元素首地址的指针。
一级指针参数,无法将一个指针本身传递给一个函数。
在C语言中,当一维数组作为函数参数时,编译器总将它解析为指向其首元素和首地址的指针。这条规则不是递归的,当超过一维时,后面的维数不可以改写。a[3][4][5]可以被改写为(*p)[4][5];