从零搭建微服务(Springboot + SpringCloud)
初始化工程
可以直接用IDEA的SpringInitialize,也可以在Spring的官网上来初始化项目,右边是需要用到的组件依赖,主要有注册中心Eureka的客户端和服务端,网关zuul,熔断器Hystrix,服务监控仪表盘HystrixDashbord,负载均衡Ribbon等
注册中心Eureka
在单体应用的时候,不同系统之间的交互无论是通过Webservice、Http还是ESB等都是用固定IP的方式来进行请求,那么就存在一个问题,当服务器的地址进行变更或者新增服务器做集群部署的时候,既要修改请求方代码中的IP地址,又需要去修改被调用方nginx的配置来完成负载均衡,这是相当麻烦的过程。注册中心的作用就是帮我们来管理这些服务,以及当服务集群中某个节点宕机了,会自动切换到其他存活的节点。
我用过的注册中心有两种,一种是Zookeeper一种是Eureka,这两者有什么区别呢?
Zookeeper是通过临时节点的方式来完成注册,当服务A在Zookeeper上注册后,会在内存中生成一个临时节点,服务B会对这个节点进行监听
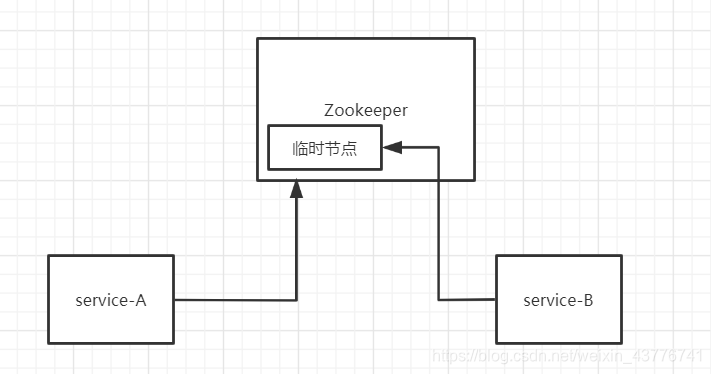
当服务A下线了,临时节点会消失。Zookeeper会自动通知到服务B,服务A已经下线了,服务B就不会将服务A的信息保存在本地的服务列表中了。面试官很喜欢问的一个问题是,当Zookeeper挂掉了,会影响服务A访问服务B吗?答案是不会的,因为服务B已经将服务A的信息存在了本地列表上,只有当服务A下线了,Zookeeper才会通知服务B将服务A的信息进行删除。
Eureka是拉取式,连接到Eureka的服务,在默认配置下每30秒到Eureka上拉取注册在Eureka上的服务信息。Eureka服务端的多级缓存和客户端增量的拉取机制都是在优化服务的注册和服务信息同步的性能和效率。
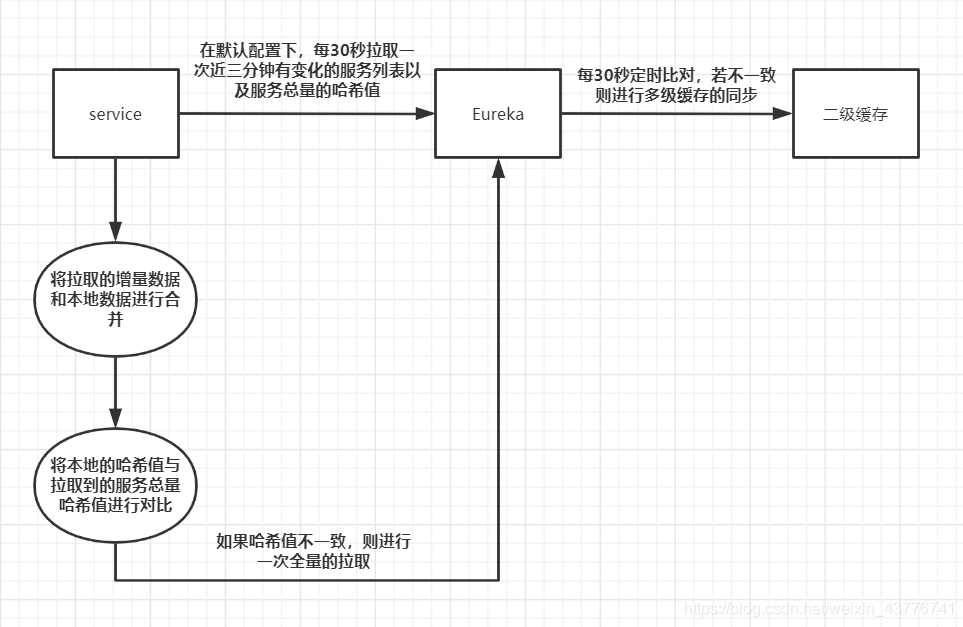
在注册中心领域来说,Eureka显然是更好的选择。原因如下,先说一下CAP是什么,
Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。通过上面的介绍,可以看出Zookeeper是CP,Eureka是AP。Zookeeper当某个节点挂点后,会直接导致不可用,这个在生产上是很可怕的事情。Eureka因为有多级缓存的存在,保证了高可用,并且通过多级缓存的同步来保证了服务信息的最终一致性。
接下来我们用Eureka来搭建一个注册中心
在根目录右键New Module后,将最外层POM文件里面的Eureka服务端的依赖复制到新建的Eureka工程中的POM文件来。

接着在启动类上添加@EnableEurekaServer注解,开启Eureka服务端的功能
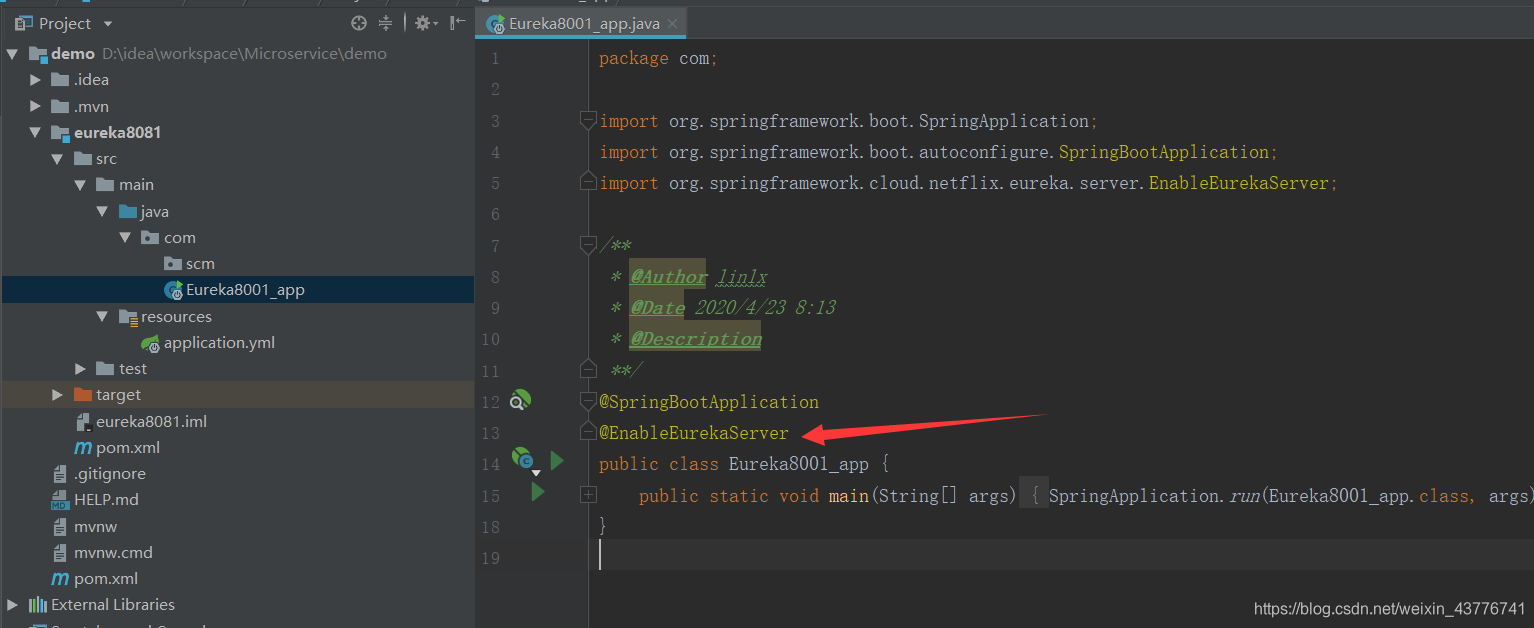
接下来就是最重要的配置文件了
#服务端口号
server:
port: 8081
spring:
application:
# 服务的名称及在Eureka可视化界面上的服务名
name: eureka8001
eureka:
instance:
# 当鼠标移到服务列表时,是否在左下角显示该服务的IP
prefer-ip-address: true
# 注册到Eureka的IP地址
hostname: 127.0.0.1
client:
# Eureka是否要去其他实例中拉取注册列表信息,单点部署的时候为false,集群部署的时候必须为true
fetch-registry: false
# 是否将此服务注册到注册中心上
register-with-eureka: false
serviceUrl:
defaultZone: http://localhost:8001/eureka
这些是最基本的一些配置,后面再说Eureka里面可以优化的配置内容。为了演示服务是否可以注册到Eureka上,我这边将Eureka的服务端的register-with-eureka改为true,然后通过http://localhost:8001进行访问。可以看到相关的配置都已经生效了。

最后说一下Eureka有哪些配置,以及如何优化。
首先我们可以在Eureka服务端jar包里面,找到EurekaServerConfigBean这个类,这里面就是Eureka服务端可以用的配置,以及部分配置的默认值了。
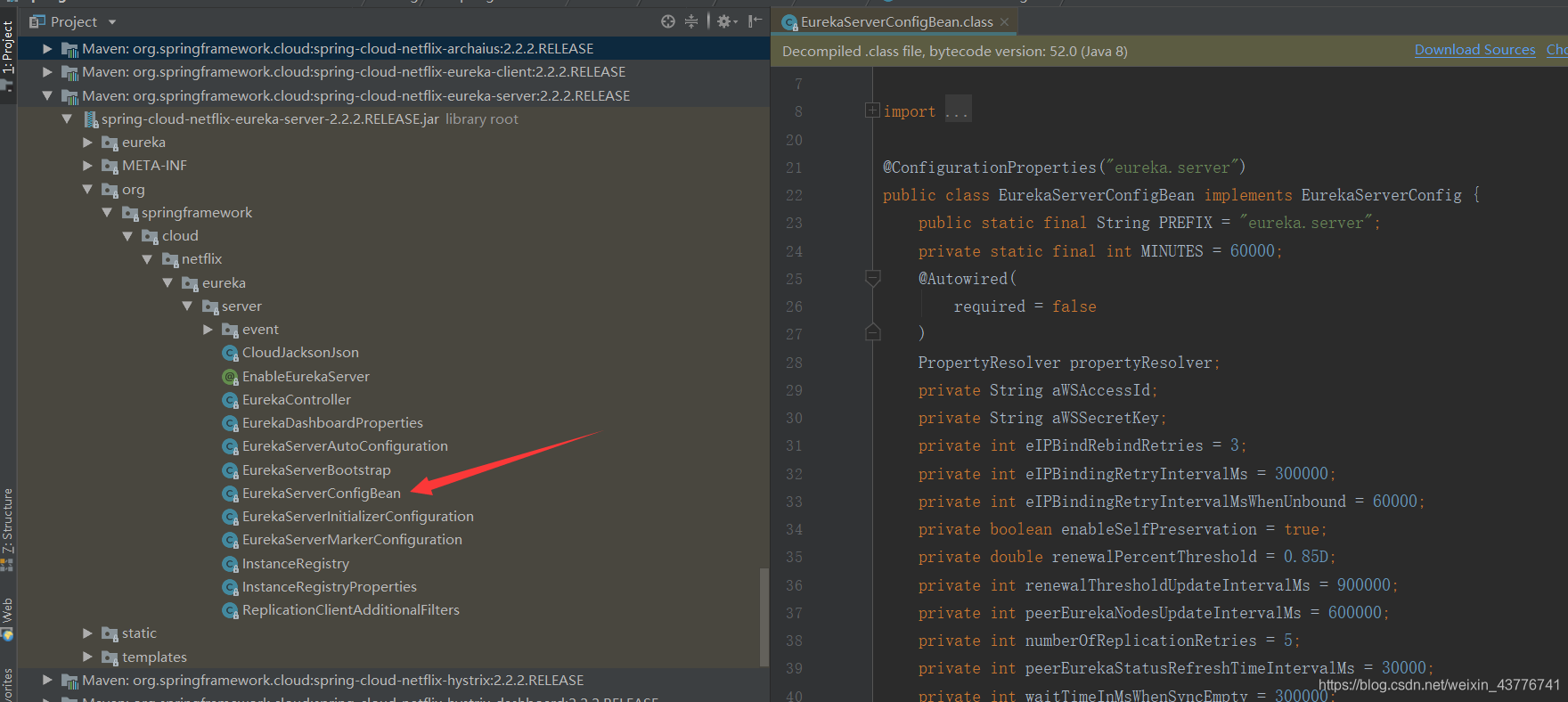
我们可以根据具体的业务场景来进行参数的优化。比如,项目的服务比较少,我要提高服务信息的准确性和一致性,那么我就可以修改Eureka客户端到Eureka服务端拉取服务列表的时间,默认是30秒。
这边我要改成10秒,那可以这样

Eureka的集群部署这边不细说了,大概步骤都差不多,要注意的配置点有两处

负载均衡Ribbon
为了能展示出负载均衡,需要新建三个生产者和一个消费者。
三个serive除了端口号和instance-id外是没有任何差异的,配置文件如下
server:
port: 7001
spring:
application:
name: service
eureka:
client:
register-with-eureka: true
service-url:
defaultZone: http://localhost:8081/eureka
instance:
instance-id: SERVICEA
prefer-ip-address: true
SpringCloud的组件使用起来都是三部,第一步是添加POM的GAV坐标完成依赖的导入,第二步就是配置文件中添加相关的配置,第三步则是使用注解开启该组件的功能。这边和Eureka就不一样了,Eureka服务是服务端,需要在Eureka上完成服务注册或者服务发现则为客户端,注解是不一样的。
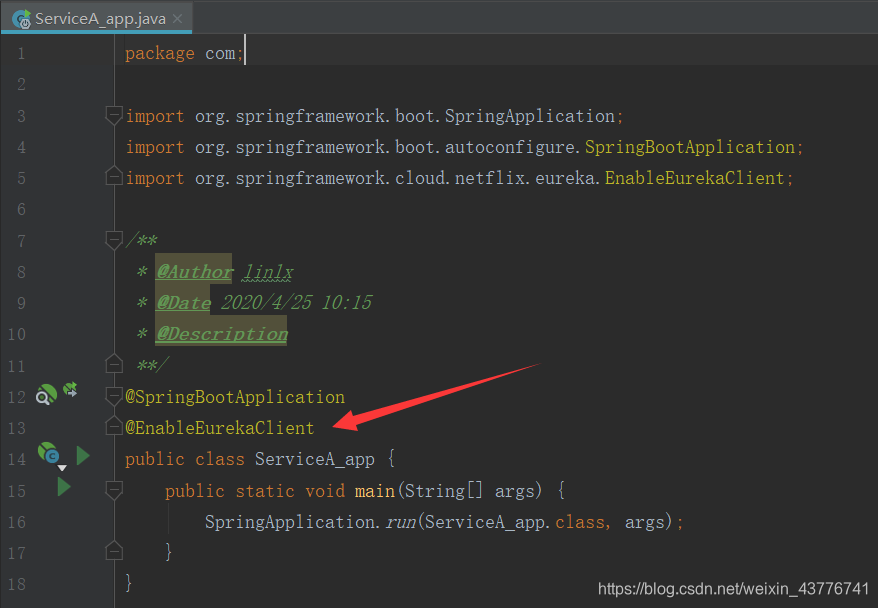
接着我们启动这三个服务,到Eureka的可视化界面看看

可以发现,Eureka上面的Application就是配置文件中的spring.application.name,Status里面展示的则是instance-id。springapplication.name这个属性十分的重要,因为之后无论是Ribbon的负载均衡,还是网关Zuul来Eureka上比对服务信息都是通过这个值来进行判断的,这里面我三个服务都取名为SERVICE来代表是相同服务进行了集群的部署。他们有一个共同的访问路径,为了展示访问同个路径到达的是不同的服务,我对控制器层返回的报文做了不同的标识。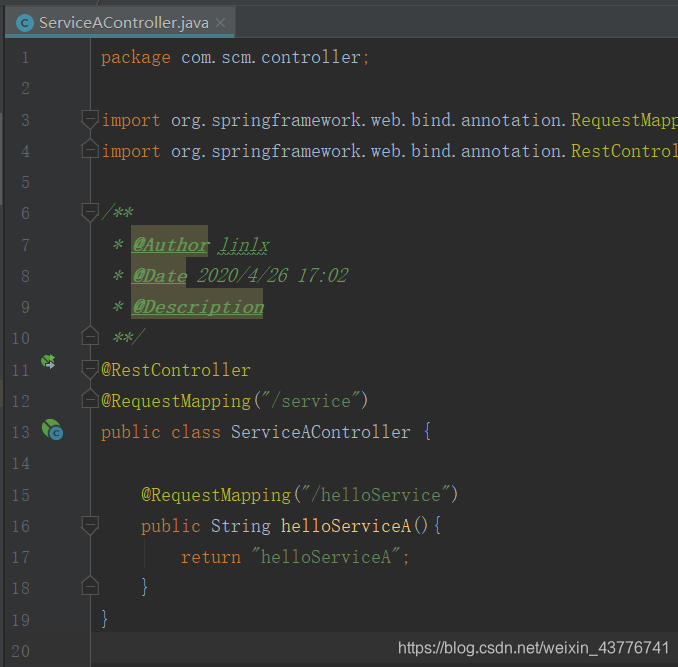
返回的字符串中会有ABC标识来代表访问的是哪个服务。
接下来说一下消费者,消费者只会去Eureka获取服务信息,而不会完成注册,所以在消费者的配置文件中register-with-eureka的值为false。同样在启动器添加ribbon的相关注解
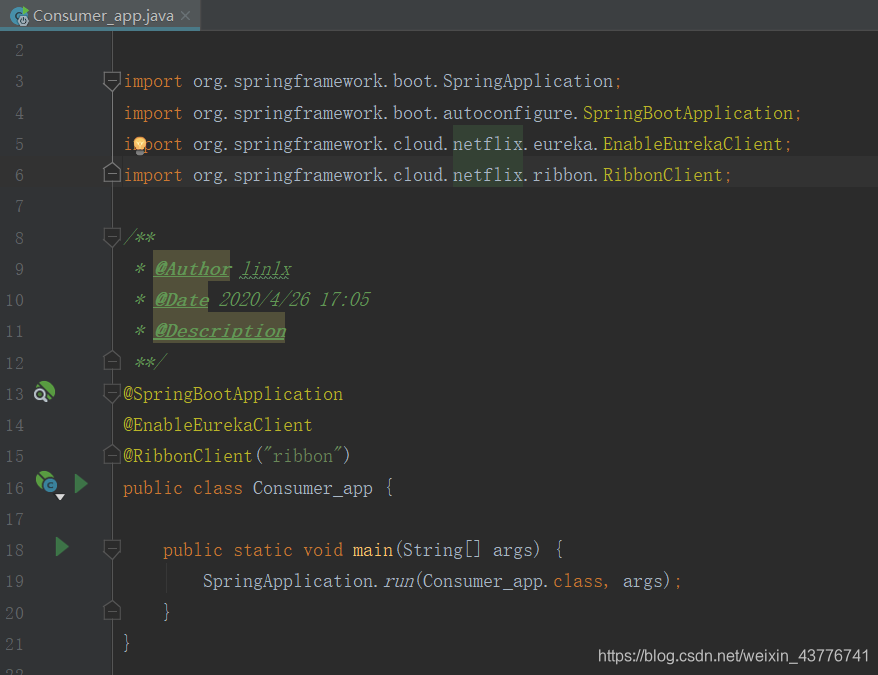
接着对RestTemplate进行配置,通关添加@LoadBalanced注解来开启负载均衡的功能。
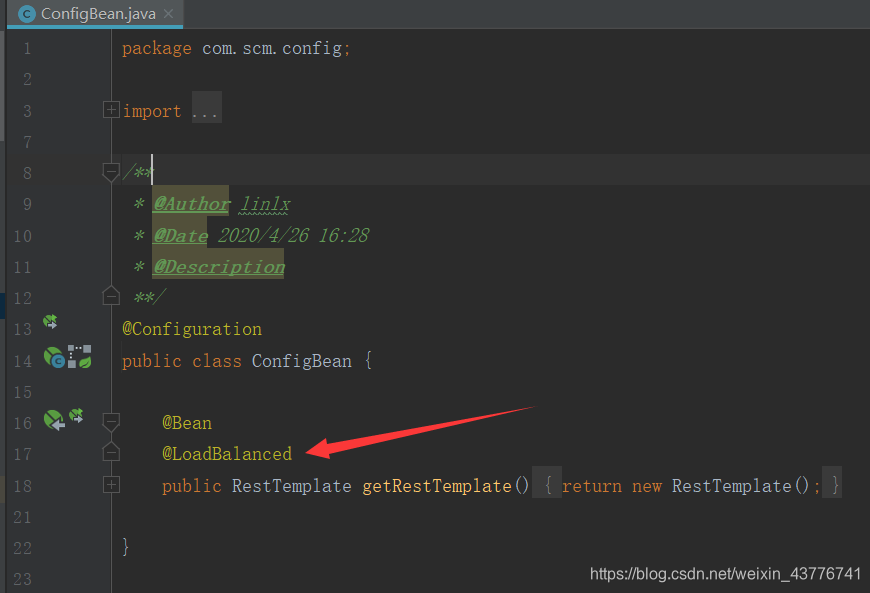
然后在消费者中就可以通过RestTemplate来进行对其他服务的访问了
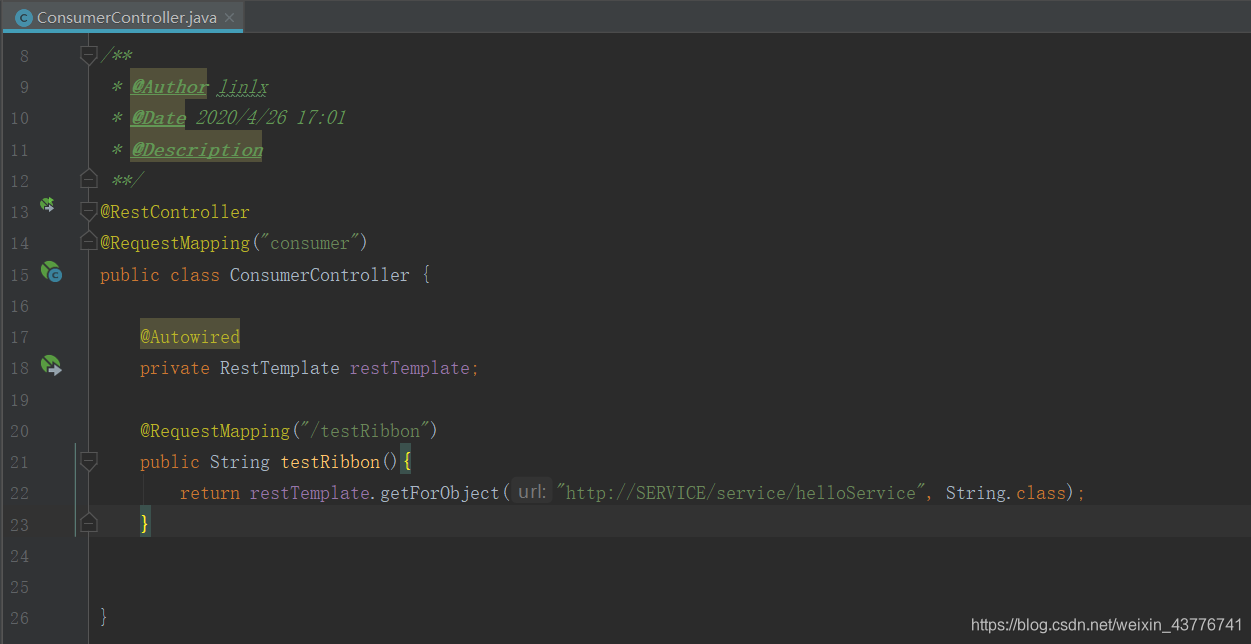
如果消费者不连接到注册中心,那么我们这边需要访问服务集群的时候,则需要写三个IP,然后再通过代码来完成负载均衡的策略,无论是轮询还是随机。当消费者连接到注册中心时,IP和端口号则可以用Eureka上的Application进行替换,Ribbon会根据获取到的服务列表,来进行负载均衡的访问,我们通过浏览器来访问消费者开放的接口,可以发现Ribbon默认的负载均衡策略是轮询。
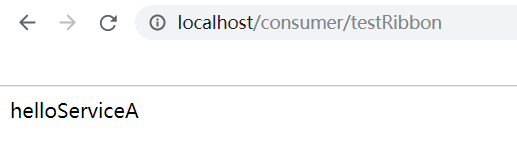
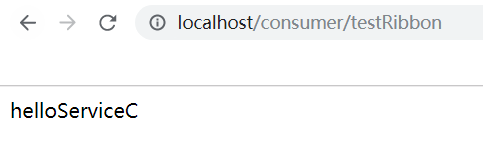
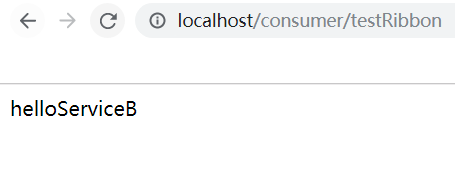
当然Ribbon负载均衡策略也支持进行配置或者重写。还是一样看源码就可以知道有哪些负载均衡策略可以使用
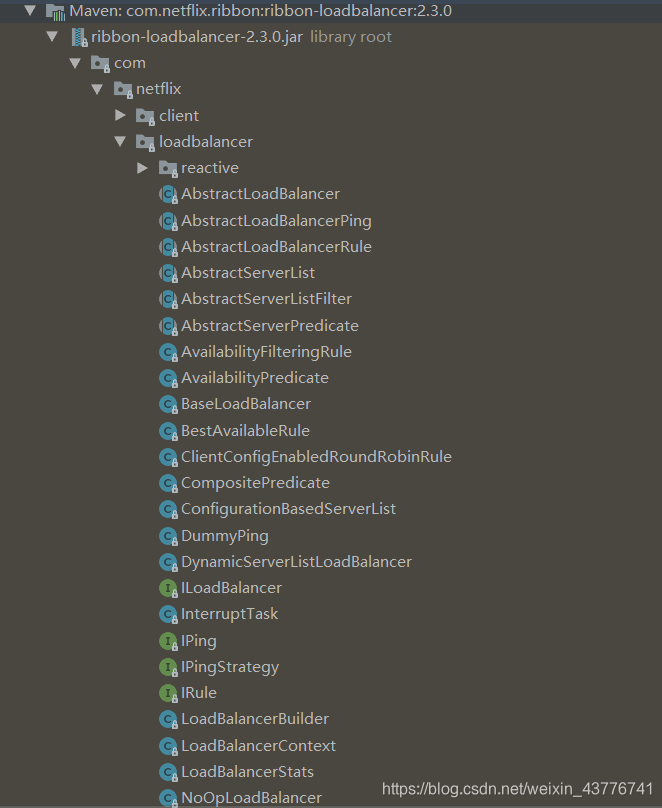
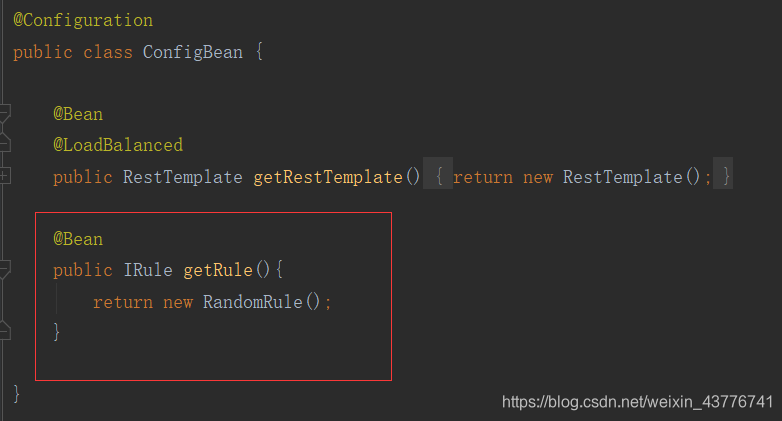
下面就是用随机的负载均衡策略来替换默认的轮询策略
声明式web服务客户端Feign
Feign的功能和Ribbon基本一致,使用的时候会根据业务场景来进行选择,先说一下怎么使用,再来说明两者的区别和技术选型。
导入POM文件的GAV和启动器添加@EnableFeignClients注解就不展示了,主要是Feign接口该怎么写
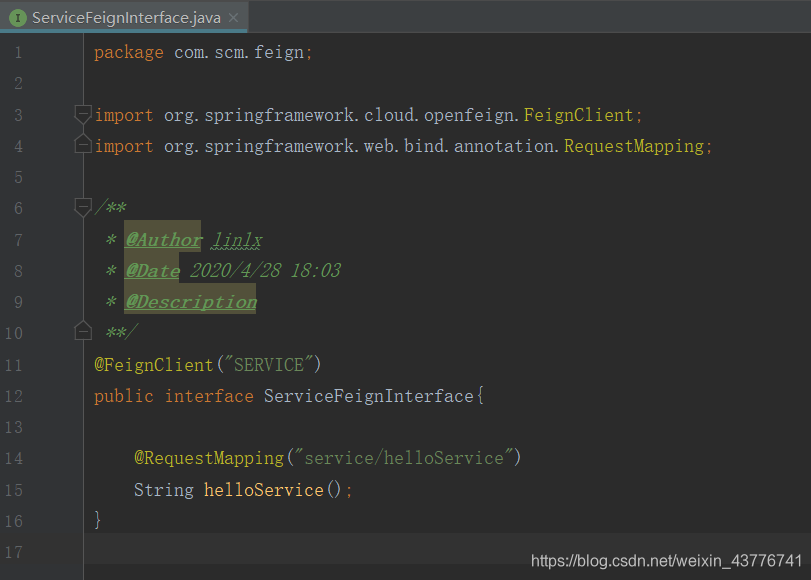
对于Feign接口的命名,有的项目是直接以Controller进行结尾,因为在@FeignClient里面,可以使用controller的所有注解,比如@RequestMapping、@RequestParam等等,但我还是更喜欢以接口的形式来进行命名。@FeignClient里面的参数,就是这个Feign接口要调用Eureka上哪个服务,即Eureka上的Application

方法上@RequestMapping里面的参数,就是的接口提供方的地址
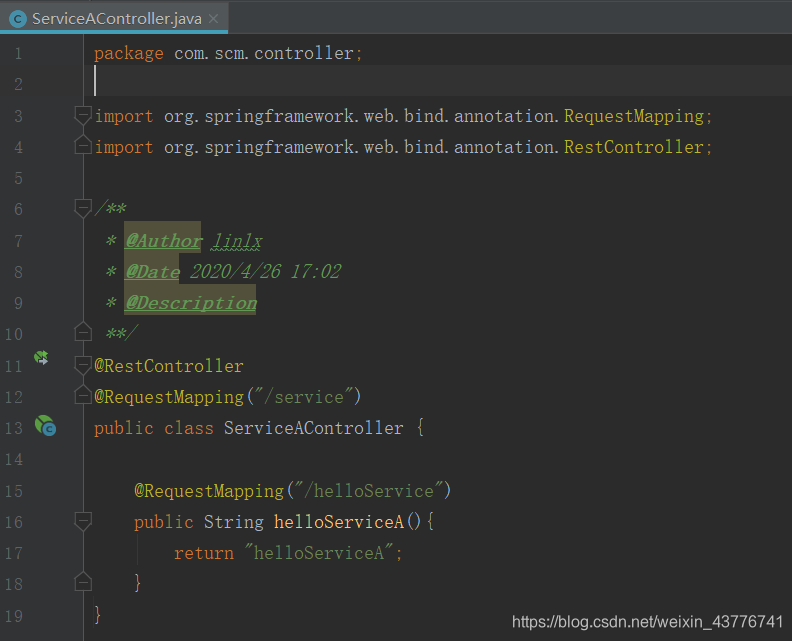
在使用Feign接口时,只需要通过@Autowired注解来注入后即可使用
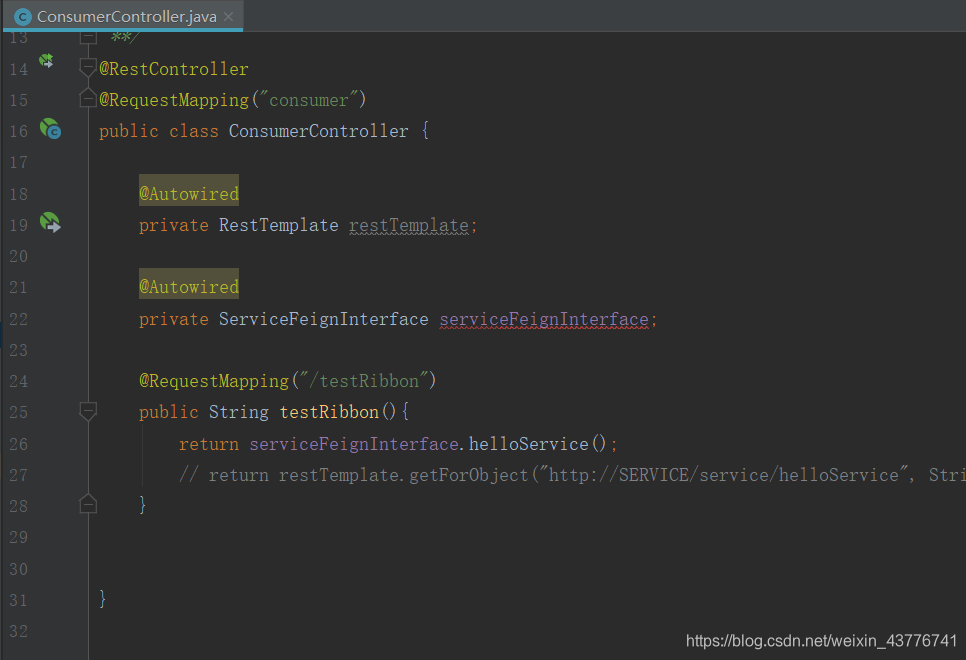
在浏览器上访问后,效果是和使用RestTemplate是一样的。并且,对于Ribbon的负载均衡配置,对Feign也是生效的,这点通过测试就可以很明显的发现了。
从使用上来说,RestTemplate的使用和JdbcTemplate类似,需要自己去写访问路径,Ribbon的使用会更加的灵活。而Fegin的使用更像是Mybatis,Feign接口类似于Mybatis的Mapper,更符合程序员喜欢的面向接口编程,并且更利于维护。项目中当然是推荐使用Feign,或者说是强制使用Feign。因为对于初级程序员来说,他们只需要关注业务逻辑即可,而不需要去做配置相关的工作。假如是使用Ribbon,对于路径的获取也是使用@Value来读取配置文件中的值,不可能直接写死在代码中,如果项目还使用了配置中心SpringCloudConfig,那么开发人员还需要去GITHUB或者数据库中增加配置、修改配置、检查配置,那会增加很大的工作量以及一系列的有风险操作。
最后说一下Ribbon和Feign的场见配置参数有哪些。Feign都是结合Hystrix来使用,重点的配置还是在Hystrix部分,这边先展示优化行的配置。
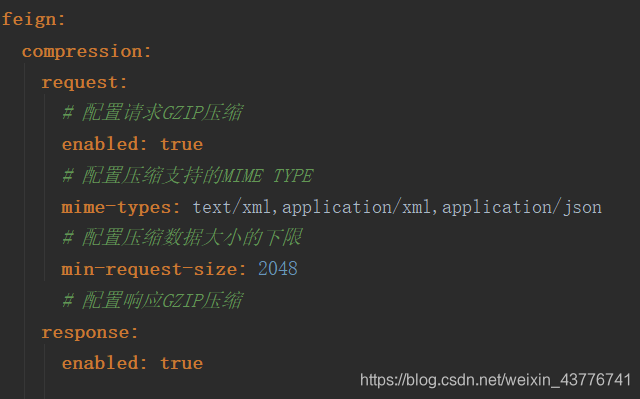
而Ribbon的配置主要是连接时间和重试相关,根据业务场景来进行选用。保证开启重试或者配置多次重试后,接口依然能保证幂等性是相当重要的。
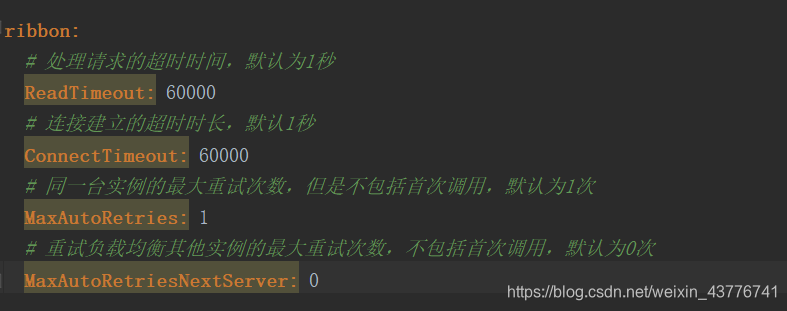
需要注意的是,如果同时对Feign和Ribbon进行配置的话,Feign的ReadTimeout和ConnectionTimeout会覆盖Ribbon的配置。
断路器Hystrix
当微服务越来越多的时候,多个微服务之间调用,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的"扇出",如果扇出的链路上某个微服务的调用相应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统的崩溃。出现服务雪崩的情况就需要有服务熔断的解决措施来进行服务的降级从而保证整体系统的高可用。Hystrix通过隔离服务之间的访问点、停止级联失败和提供回退选项来实现这一点,所有这些都可以提高系统的整体弹性。
添加POM文件里Hystrix的GAV坐标后,在启动器添加@EnableCircuitBreaker,然后在配置文件中添加feign.hystrix.enable=true开启断路器功能。
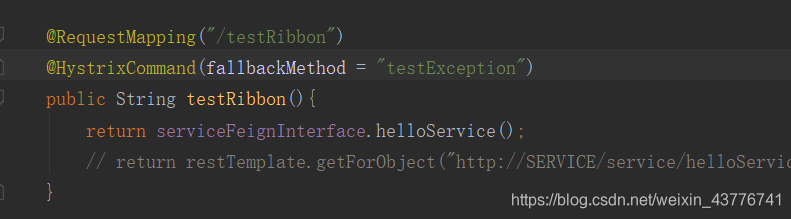
@HystrixCommand的作用是当testRibbon这个方法出现异常时,会去调用fallbackMethod方法,立刻释放资源,而不是继续等待服务提供方的返回。手动抛出异常后,进行测试
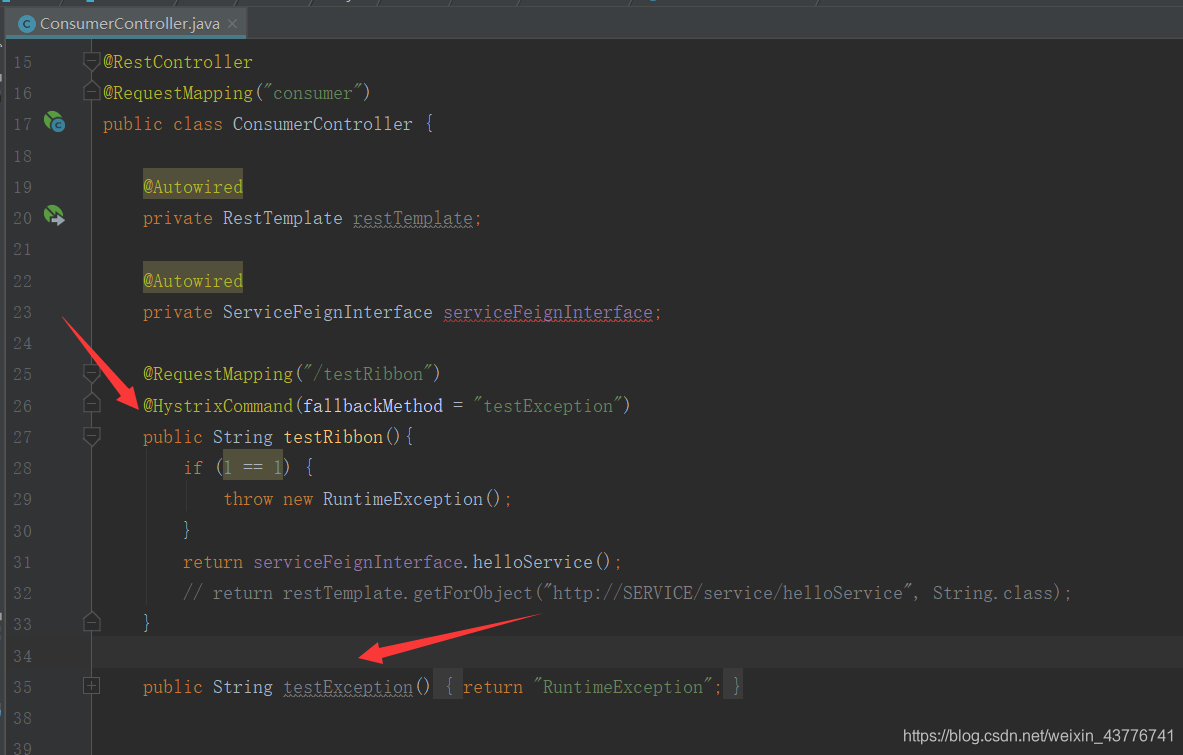
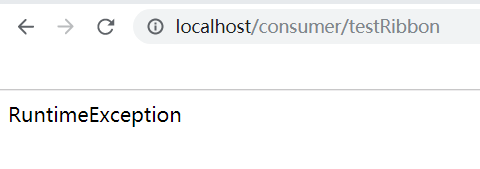
经过测试可以发现,当testRibbon发生异常时,就会去执行@HystrixCommand注解里面的testException方法,从而保证了资源的释放。
但这样的写法明显是不符合Spring的AOP思想的。首先,每个方法都有一个fallbackMethod会使代码膨胀,其次业务逻辑和异常的处理耦合度太高,应该实现分离。所以@HystrixCommand在项目中的使用极少,更推荐使用符合AOP思想的写法。
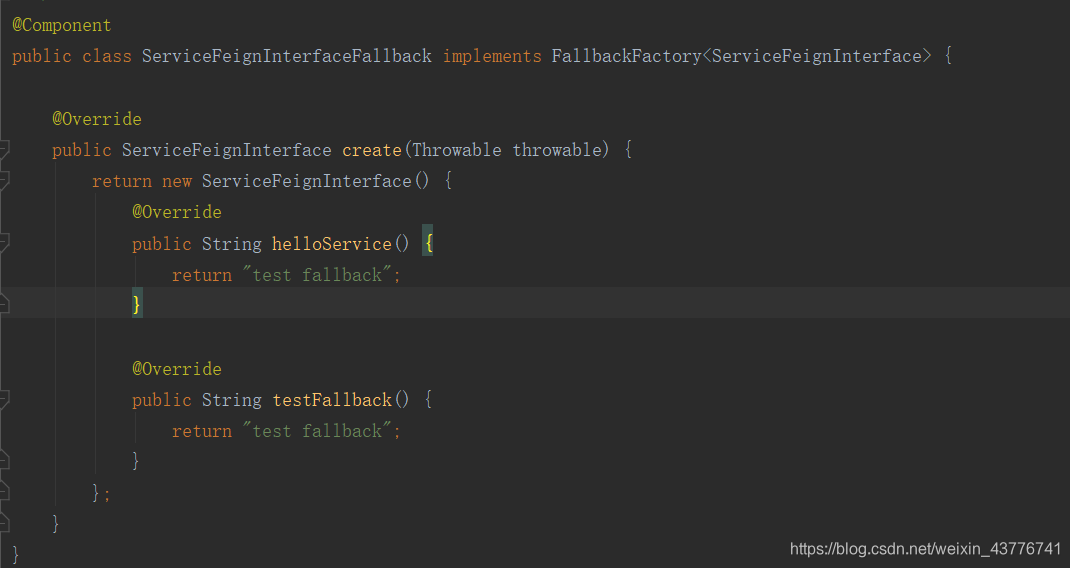
新建FallBack的统一处理类,实现FallbackFactory,记得添加@Component注解,否则该类将无法被Spring加载。
修改Fegin接口的注解参数
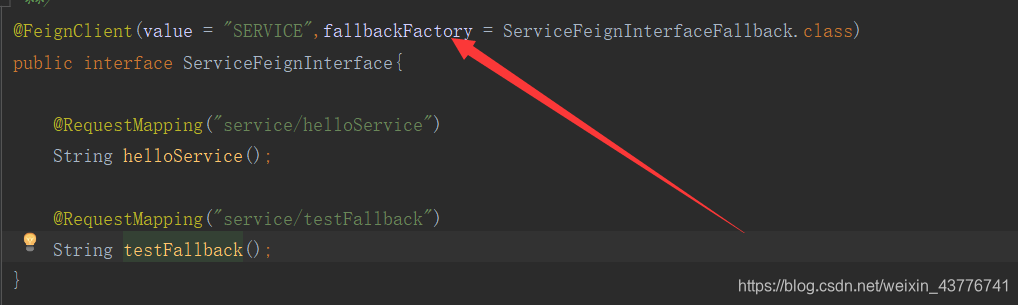
最后分别对两个接口进行测试
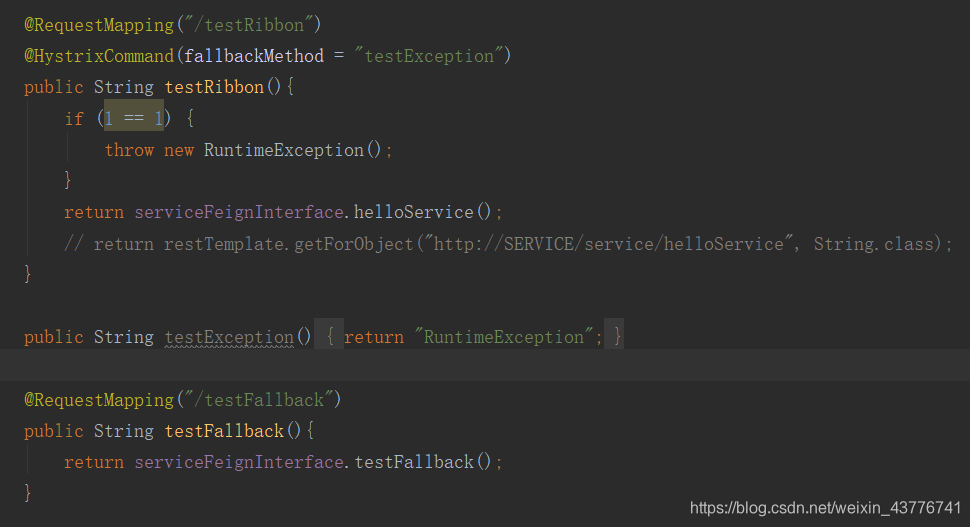
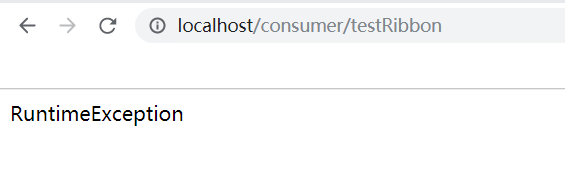
第一个接口的测试结果可以发现,@HystrixCommand的配置是高于全局的配置
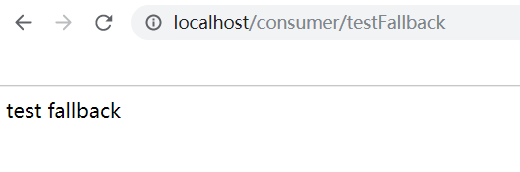
第二个接口的测试结果表明,当请求发生未知的异常,比如我这里根本就没有启动service服务时,feign接口会去走fallback里面实现的方法来完成服务的熔断和服务的降级。
网关Zuul
网关Zuul包含了对请求的路由和过滤这两个最主要的功能。其中路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础,而过滤器功能则负责对请求的处理过程进行干预,是实现请求校验、服务聚合等功能的基础。当外部系统来访问内部接口时,如果需要每个接口都来进行权限校验,代码将十分冗余。网关的出现就是解决了这个问题,外部的请求统一到达网关后完成请求校验后在分发到各个微服务上,这样也使得运维的成本大大的降低了。
Zuul和Eureka进行整合,将Zuul自身注册为Eureka服务治理下的应用,同时从Eureka中获得其他微服务的信息。也即以后的访问微服务都是通过Zuul跳转后获得。下面是Zuul的最简单配置,启动后能在Eureka上看到Zuul则配置无误。
server:
port: 82
spring:
application:
name: zuul
eureka:
client:
register-with-eureka: true
service-url:
defaultZone: http://localhost:8081/eureka
instance:
instance-id: zuul
prefer-ip-address: true
在启动器开启Zuul功能的时候,会发现有两个注解,@EnableZuulProxy和@EnableZuulServer。
这两者的区别在于,@EnableZuulServer只用到了请求代理,无法实现动态查找要访问的服务后端地址实例有哪些,所以无法和Eureka进行集成。@EnableZuulProxy是加强版,在服务访问的时候,可以使用到动态注册的功能,Zuul有很多过滤器,会加上动态服务访问的控制。如需要自定义过滤器或者监听器则需要在启动器开启@ServletComponentScan,这样Zuul在启动的时候,就会把自定义的过滤器给加载进去。
接下来测试下是否可以通关网关来访问微服务
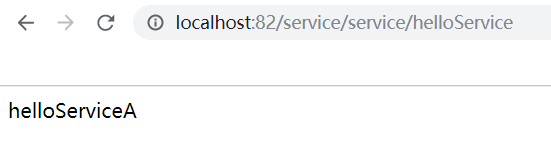
通关网关/微服务名/接口路径的URL来访问是没问题的,但是这边对外暴露的微服务的名称,可以通关修改配置来隐藏真实的微服务名。下面我将微服务service的代理路径改为myservice在进行测试
zuul:
routes:
# 需要代理的服务名。即spring.application.name
service:
# 代理的路径
path: /myservice/**
# Eureka上的application,即各个微服务中配置的instance-id
serviceId: service

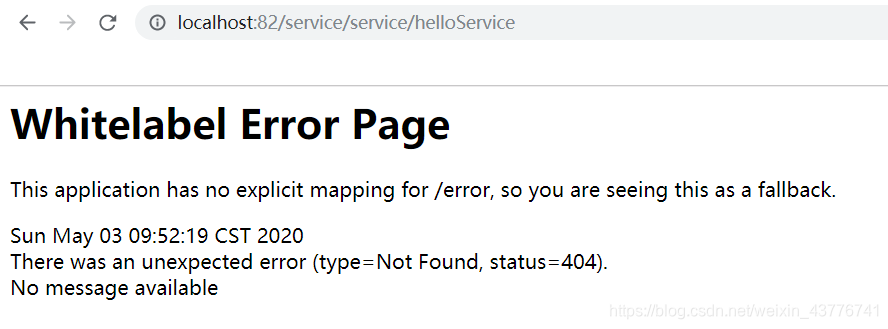
可以发现两个路径都是可以的。那么这边就还存在一个问题,接口提供方有多个入口,这个是要尽量避免的,做到一个接口对外只有一个访问路径。在配置文件中新增zuul.ignored-services=service后在进行测试,可以发现通过网关/微服务名/接口路径的URL来访问是不行的了,只能通过配置文件中的代理路径来进行访问了,确保了一个接口对外只开放一个地址。
Zuul也同样支持前缀的配置来优化域名的管理,还有访问时长和是否重试的参数配置,下面是Zuul完整的配置
zuul:
# 域名前缀
prefix: /scm
# 禁止通过哪个微服务名进行访问,如有多个用逗号隔开,如需全部则用"*"
ignored-services: service
routes:
# 需要代理的服务名。即spring.application.name
service:
# 代理的路径
path: /myservice/**
# Eureka上的application,即各个微服务中配置的instance-id
serviceId: service
# 访问超时设置
host:
socket-timeout-millis: 2000
connect-timeout-millis: 1000
# 是否开启重试
retryable: false
配上域名前缀,通过Zuul来访问接口时,就必须加上域名前缀了
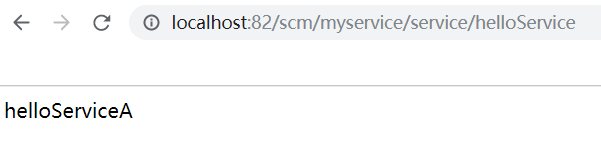
调用监控Hystrix Dashborad
上面介绍了微服务间的调用可以使用Feign并且通过Hystrix来进行服务的熔断和降级。同样,SpringCloud也提供了可视化的组件Hystrix Dashborad来对通过Hystrix发起调用的接口进行监控。
新建Module后,在POM文件里面添加Hystrix Dashborad的依赖,在启动器添加@EnableHystrixDashboard开启该功能,配置文件只需要配置端口号即可。启动工程后就可以通过浏览器来进入Hystrix Dashborad的可视化界面。

Hystrix Dashborad监控的是通过Hystrix发起调用的接口,即开启断路器功能的Feign接口。并且需要在被监控的工程中加入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
然后还需要增加一个监控路径的配置
@Bean
public ServletRegistrationBean getServlet() {
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
最后根据Hystrix Dashboard可视化界面上的使用步骤,来进行配置

监控的路径格式为ip:端口号/hystrix.stream,Delay参数用来控制服务器上轮询监控信息的延迟时间。默认为2000毫秒,可以通过配置该属性来降低客户端的网络和CPU消耗。Title是自定义的名字,配置完成后点击Monitor Stream按钮即可。

刚进来的时候是什么都没有的,接下来用浏览器进行Fegin接口的访问
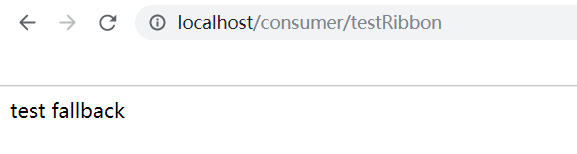
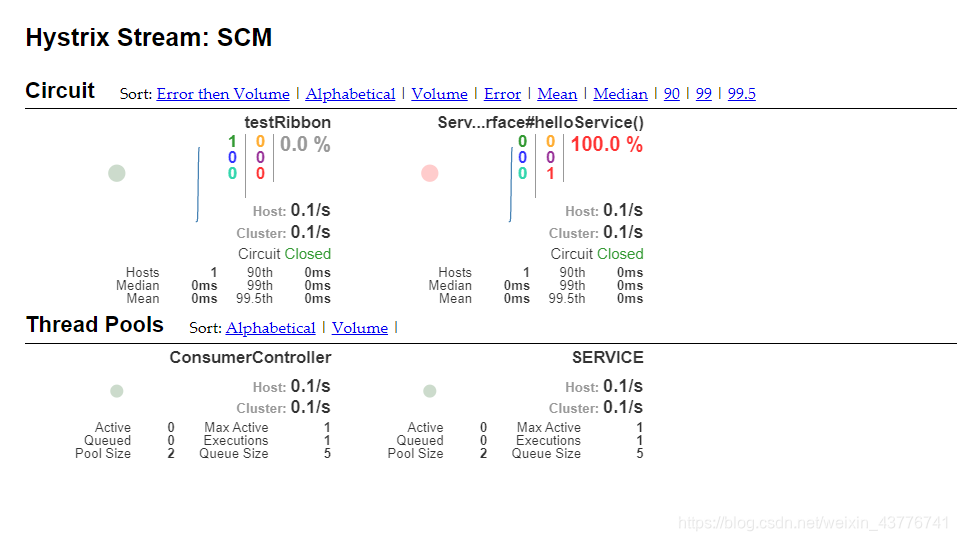
可以发现有东西出现了。首先testRibbon是绿色,说明这个接口访问成功,然后这个接口调用Feign接口去访问其他的微服务,但是,我并没有启动其他的微服务,所以这里走了本地的Fallback方法,可以看到上图中浏览器的输出。结合Hystrix Dashboard可视化来看,serviceFeignInterface.helloService()是红色的,说明红色是失败的意思。
最后总结一下Hystrix Dashborad的可视化图例该怎么看。
颜色:代表不同的健康度
线:代表此刻的访问量
实心圈:通过颜色代表健康度,大小会根据实例的请求流量发生变化,流量越大圈越大,所以通过该实心圈的展示,就可以在大量的实例中快速的发现故障实例和高压力的实例。
总结
结合Spring官网上的SpringCloud组件介绍图来说一些我自己对SpringCloud的理解。
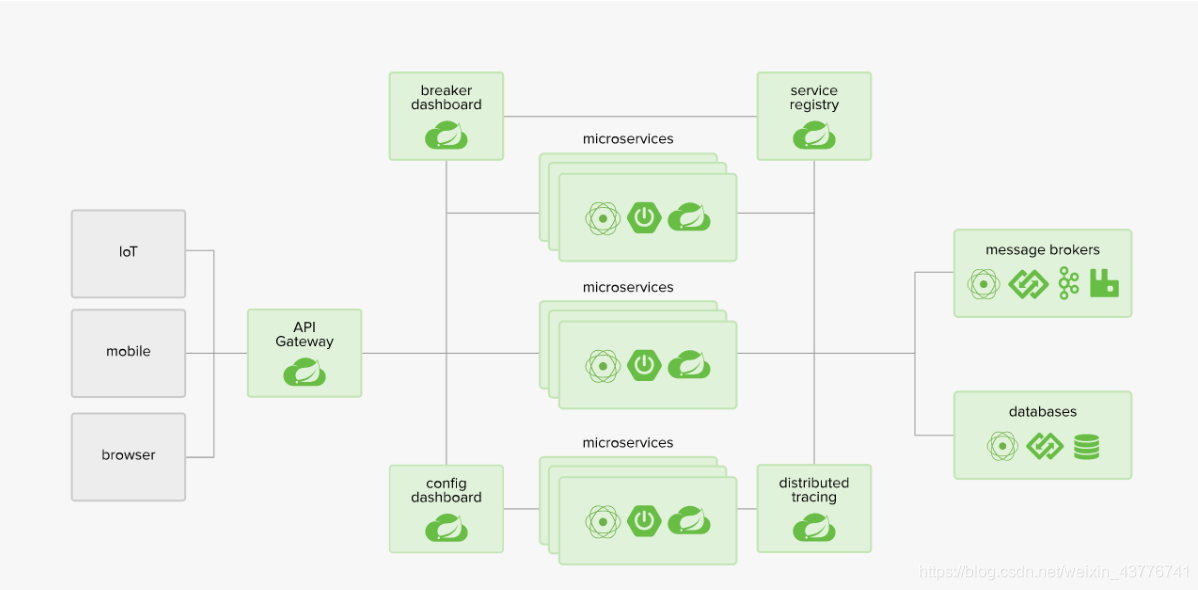
各式各样的客户端就像是游客,游客在访问大楼的时候如果没有物业的存在,游客将按照约定的楼层去访问不同的住户,如果有一天住户搬走了,游客再来访问的时候就访问不到了,也就是404错误。这时候就需要物业来对这些住户的地址以及地址的有效性进行管理。注册中心就和物业一样,住户也就是微服务,入住的时候需要来注册中心进行注册,离开的时候也需要告知注册中心我下线了。有了物业之后,游客再来访问的时候,需要先过保安,也就是网关。保安会先去核实游客的访问是否合规,访问的住户信息是否有效,如果正确有效即放行,否则就不让进入大楼。网关的作用也是如此,当请求访问时先进行拦截,通过校验后再去注册中心上核对该访问路径是否正确,最后将请求分配到对应的微服务上。保安放行后,游客进入大楼后发现要访问住户门关着,不知道是否有人,如果一直等下去将耗费时间,再被告知住户不在后,游客马上离开,去做自己的事了。断路器的功能正是如此,当服务A访问服务B得不到响应后,将调用本地的fallback方法来进行兜底,立即释放资源,而不是继续等待直到耗尽所有的资源。一栋楼里有三家肯德基,游客在路标的指引下会选择就近的肯德基进行用餐。这就是路由的作用,三家肯德基可以理解成集群部署的一个微服务,当请求访问该微服务时,网关会根据负载均衡策略来对请求进行分发。如果一个肯德基关门,那么游客就会去另外一家。网关的路由也是如此,一台服务器宕机了,就把请求路由到其他台平稳运行的服务器上。有一天大楼丢了东西,需要调用监控查看是谁偷的。服务监控仪表盘就是大楼的监控,当某个数据丢失的时候,就可以在可视化界面上进行查找,看下是否在该时间段内有请求失败了,就可以很容易排查出数据丢失的原因了。
最后,技术服务于需求,不是每个项目都需要这么多的微服务组件,一个项目的平稳运行不是依靠堆积各式各样的技术,而是找到最符合业务要求的解决方案。
完整源码地址https://github.com/llx330441824/microservice.git
也可以留下邮箱,方便代码分享