paddle深度学习高层API第一天
大家好,这里是三岁,别的不会,擅长白话,今天就是我们的白话系列,内容是paddle2.0新出的高程API,在这里的七日打卡营0基础学习,emmm我这个负基础的也来凑凑热闹,那么就开始吧~~~~
注:以下白话内容为个人理解,如有不同看法和观点及不对的地方欢迎大家批评指正!
传说中的第四次“工业革命”

【白话时间】人工智能缩写AI,大家已经见过很多的人工智能产品,而且越来越多的产品在不断的涌现,质量效果也越来越好
前几年有一个对人工智能的爱称“人工智障”训练的好是人工智能训练不好是“人工智障”,但是近年来,水平的不断提高,在非常多方面已经超过了之前的水平,甚至有非常有意义的使用价值(部分方面超过人 )
那么人工智能下面有哪些分支和我们要学的深度学习又有说没关系嗯?

人工智能>机器学习>深度学习
人工智能大家都知道那么什么是机器学习???
回顾人类的历史长河,我们是怎么样一步一步的创新,发展的?
在生物中这个叫做变异,当然有正确的有错误的,所以就有了现在大家说知晓的适者生存,不适者淘汰的理论
那么机器可不可以通过不断的尝试试错得到一个比较好的理论呢???

看到这个图就知道了,其实 是一样的,规律就是大家不断探索以后得到的一个结果,也就是一个试错的过程。通过我们构建的一个规则然后机器通过算力不断的探索,最后得到一个比较好的结果,这个结果就是传说中的“规律”。
机器学习就是通过一个“函数”(模型)来判断输出你想要的比较合适的一个结果
深度学习就是通过一些神经网络等方法,提取我们的一些特征进行处理。
计算机识别的都是二进制内容不好理解
我们举一个栗子大家就明白了,如果说水果是臭的带刺的你们会想到什么水果,那基本上就是榴莲,通过几个特殊的特征进行提取。

神经网络

神经元:和我们的神经元类似,但是他更类似于数学函数里面的斜率之类的一些重要参数。(有加权和、激活函数等构成)
多层神经网络:相对应人类的神经传导,输入相对应接受电信号并传输到大脑皮层的一个过程,前向计算:相对应大脑给出一个指令然后进行运行;返回传播:相对应输入信息不断更新后大脑发出指令完成系列任务,输出相对应完成一件事情。
栗子:手碰到针,大脑皮层会产生痛觉然后大脑(应该是脑干)会发出收手的信号然后会一直检测直到痛感消失。



在不断的发展过程,越来越多的内容标准化,逐步的形成了一些框架和架构。
深度学习万能开发公示

深度学习训练就像是我们平时的考试,数据是知识,模型是我们的大脑,调优就是我们学习的方法,最后的预测相对应我们的考试,评价我们对知识的掌握情况

里面的
loss是用于评判模型训练过程好坏的一个值,相对应我们平时对学习方法的一种认可与否。
score这是判断学习成果的,相对应单元测试卷(以上是个人认知,不对可以批评指正,相互学习)

闻说双飞桨,翩然下广津



手写数字识别实战

这个内容三岁之前也做过,看了一下发现没有那么的详细但是还是恬不知耻把项目链接什么的贴出来,有兴趣的小伙伴可以去看看
『深度学习7日打卡营』第1课案例:手写数字识别(课程代码地址)
PaddlePaddle2.0 ——手写数字识别(三岁白话paddle项目)
[三岁白话系列]PaddlePaddle2.0——手写数字识别(三岁白话paddle系列博客)





上面的4步就是我们完成一个书写数字识别的流程,接下来就是雨哥详细代码解析,有一说一,真的细节!
『深度学习7日打卡营』第1课案例:手写数字识别(课程代码地址)
代码解析
数据处理

import paddle.vision.transforms as T
# 数据的加载和预处理
transform = T.Normalize(mean=[127.5], std=[127.5])
# 训练数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 评估数据集
eval_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('训练集样本量: {},验证集样本量: {}'.format(len(train_dataset), len(eval_dataset)))
这个里面涉及了两个高层的API
让我们一起看一下

这个是paddle.vision.Normalize(mean=0.0, std=1.0, data_format='CHW', to_rgb=False, keys=None)
作用是图像归一化处理
这个是paddle.vision.MNIST作用就是对书写数字识别进行下载并做基本处理。
就相当于把养殖场的活物给你处理好,直接可以下锅。
经过归一化处理和数据集的整理得到了以下结果:
训练集样本量: 60000,验证集样本量: 10000
数据查看

print('图片:')
print(type(train_dataset[0][0])) # 图片的类型
print(train_dataset[0][0]) # 输出图片(数组形式)
print('标签:')
print(type(train_dataset[0][1])) # 标签的类型
print(train_dataset[0][1]) # 标签的值
# 可视化展示
plt.figure()
plt.imshow(train_dataset[0][0].reshape([28,28]), cmap=plt.cm.binary)
plt.show()
仔细观察就会发现这里面都非常容易理解,但是这个train_dataset[0][0]我们怎么自己得到?
print(train_dataset)
# 结果是生成器
# <paddle.vision.datasets.mnist.MNIST object at 0x7f95f4666ad0>
print(train_dataset[0])
# 得到的是数组
train_dataset就是由60000个数组组成的生成器
网络模型构造
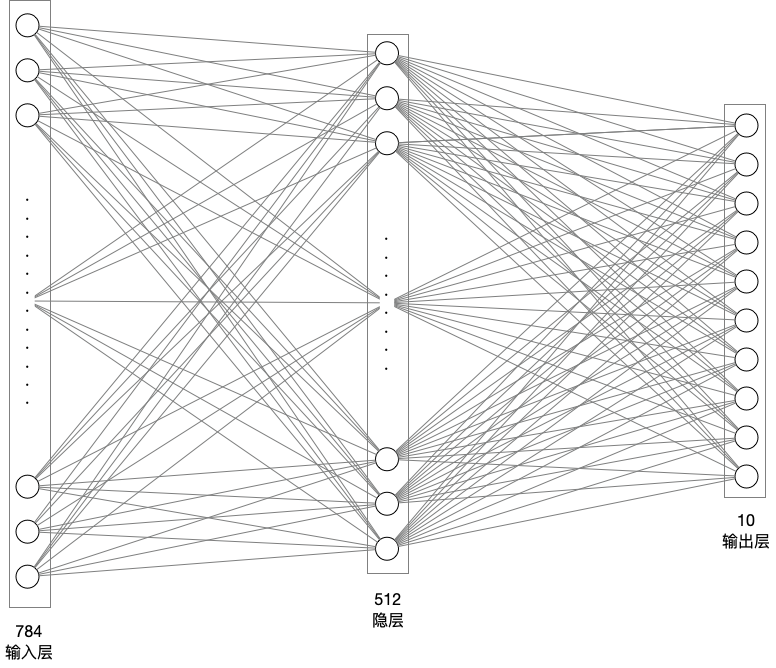
接下去就到神经网络了
输入层是784那么这个值是怎么来的???

原始数据是28*28的大小,拉平成一维以后就是784
# 模型网络结构搭建
network = paddle.nn.Sequential(
paddle.nn.Flatten(), # 拉平,将 (28, 28) => (784)
paddle.nn.Linear(784, 512), # 隐层:线性变换层
paddle.nn.ReLU(), # 激活函数
paddle.nn.Linear(512, 10) # 输出层
)
paddle.nn.Sequential(*layers):顺序容器。子Layer将按构造函数参数的顺序添加到此容器中。传递给构造函数的参数可以Layers或可迭代的name Layer元组。
paddle.nn.Flatten(start_axis=1, stop_axis=- 1):它实现将一个连续维度的Tensor展平成一维Tensor
paddle.nn.Linear(in_features, out_features, weight_attr=None, bias_attr=None, name=None):线性变换层(建议自己去API文档理解)
paddle.nn.ReLU(name=None):ReLU激活层
paddle.nn.Linear(in_features, out_features, weight_attr=None, bias_attr=None, name=None):线性变换层-输出 (建议自己去API文档理解)
在这里面:输入是784已经固定,以为输入的一维数组是784,输出层的10已经固定,0-9为10个数值,需要进行判定
中间的只要输入的线性变换层的第二个值和输出的线性变换层第一个值一样就行
模型网络结构可视化
# 模型封装
model = paddle.Model(network)
# 模型可视化
model.summary((1, 28, 28))
通过对模型的封装然后展示可以获得每一次网络的啥情况进行一个查看和检测
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Flatten-1 [[1, 28, 28]] [1, 784] 0
Linear-1 [[1, 784]] [1, 512] 401,920
ReLU-1 [[1, 512]] [1, 512] 0
Linear-2 [[1, 512]] [1, 10] 5,130
===========================================================================
Total params: 407,050
Trainable params: 407,050
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.01
Params size (MB): 1.55
Estimated Total Size (MB): 1.57
---------------------------------------------------------------------------
{
'total_params': 407050, 'trainable_params': 407050}

这样子可以查看每一层的情况,包括学习的程度什么的
模型配置及训练
# 配置优化器、损失函数、评估指标
model.prepare(
paddle.optimizer.Adam(learning_rate=0.001,
parameters=network.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=5, # 训练的总轮次
batch_size=64, # 训练使用的批大小
verbose=1) # 日志展示形式
paddle.Modle.prepare(optimizer=None, loss_function=None, metrics=None):用于配置模型所需的部件,比如优化器、损失函数和评价指标。
paddle.optimizer.Adam:Adam优化器,能够利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
paddle.nn.CrossEntropyLoss:该OP计算输入input和标签label间的交叉熵损失 ,它结合了 LogSoftmax 和 NLLLoss 的OP计算,可用于训练一个 n 类分类器。分类器
paddle.metric.Accuracy:计算准确率(accuracy)
paddle.Modle.fit:训练模型
模型评估
# 模型评估,根据prepare接口配置的loss和metric进行返回
result = model.evaluate(eval_dataset, verbose=1)
print(result)
paddle.Model.evaluate:在输入数据上,评估模型的损失函数值和评估指标。
模型预测
- 批量预测
使用model.predict接口来完成对大量数据集的批量预测。
# 进行预测操作
result = model.predict(eval_dataset)
# 定义画图方法
def show_img(img, predict):
plt.figure()
plt.title('predict: {}'.format(predict))
plt.imshow(img.reshape([28, 28]), cmap=plt.cm.binary)
plt.show()
# 抽样展示
indexs = [2, 15, 38, 211]
for idx in indexs:
show_img(eval_dataset[idx][0], np.argmax(result[0][idx]))
paddle.Modle.predict:在输入数据上,预测模型的输出。
通过函数把模型预测结束后,抽取个别数据集进行处理并预测
- 单张预测
# 读取单张图片
image = eval_dataset[501][0]
# 单张图片预测
result = model.predict_batch([image])
# 可视化结果
show_img(image, np.argmax(result))
paddle.Model.predict_batch:在一个批次的数据上进行测试
保存模型
# 保存用于后续继续调优训练的模型
model.save('finetuning/mnist')
paddle.Model.save:将模型的参数和训练过程中优化器的信息保存到指定的路径,以及推理所需的参数与文件
继续调优训练
from paddle.static import InputSpec
# 模型封装,为了后面保存预测模型,这里传入了inputs参数
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1, 28, 28], dtype='float32', name='image')])
# 加载之前保存的阶段训练模型
model_2.load('finetuning/mnist')
# 模型配置
model_2.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=network.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型全流程训练
model_2.fit(train_dataset,
eval_dataset,
epochs=2,
batch_size=64,
verbose=1)
这里就相当于把之前的几个大的流程再走一遍:封装模型,然后读取之前的模型,模型配置,训练配置然后就可以运行了
保存预测模型
# 保存用于后续推理部署的模型
model_2.save('infer/mnist', training=False)
再次保存。
training=False不再保存其他的训练参数,只保留模型
整理
第一天的课程终于整理结束了,我们也来回顾一下,首先就是对人工智能、机器学习、深度学习进行的一定的解释和梳理,使得有一定的理解,知道什么是AI。
然后对深度学习的流程进行了梳理得到了—深度学习万能开发公式
引出了我们的boos——paddlepaddle
对书写数字识别进行了详细的解析,真·详细
把整个项目掰开,一点一点的进行了分析和梳理
总结
虽然今天是课程的第一天,难度绝对不低,但是收获真的多,花了整整5小时的时间进行了梳理,对整个深度学习的流程有了更加丰富的理解,有一种马上就要恍然大悟但是又有点迷茫的那种状态。
接下的课程更精彩,期待
这里是三岁,飞桨社区最菜的小白
我在AI Studio上获得黄金等级,点亮7个徽章,来互关呀~
CSDN首页
如果喜欢记得关注呦!!!