paddle深度学习高层API第二天
大家好,这里是三岁,别的不会,擅长白话,今天就是我们的白话系列,内容是paddle2.0新出的高程API,在这里的七日打卡营0基础学习,emmm我这个负基础的也来凑凑热闹,那么就开始吧~~~~
注:以下白话内容为个人理解,如有不同看法和观点及不对的地方欢迎大家批评指正!
这里是第二篇,由于前面一篇篇幅过长,所以分上下,请各位见谅。
第一篇传送门
那我们接下去继续吧!
几种卷积神经网络
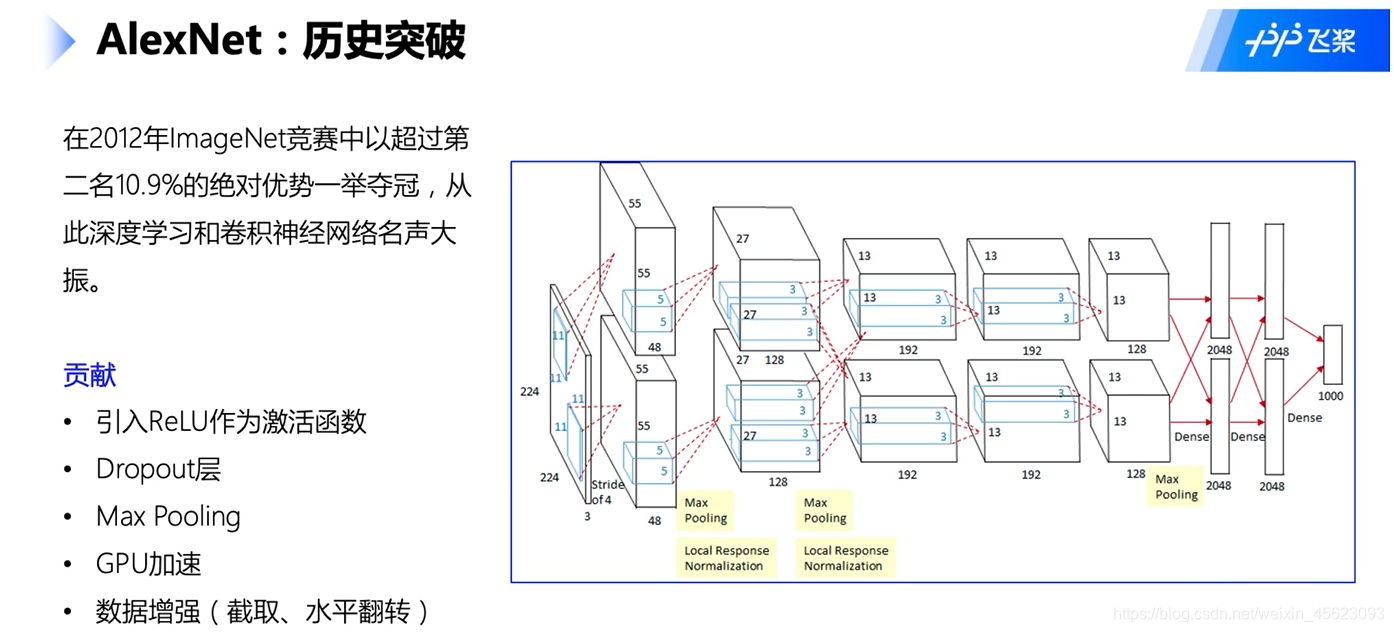
AlexNet
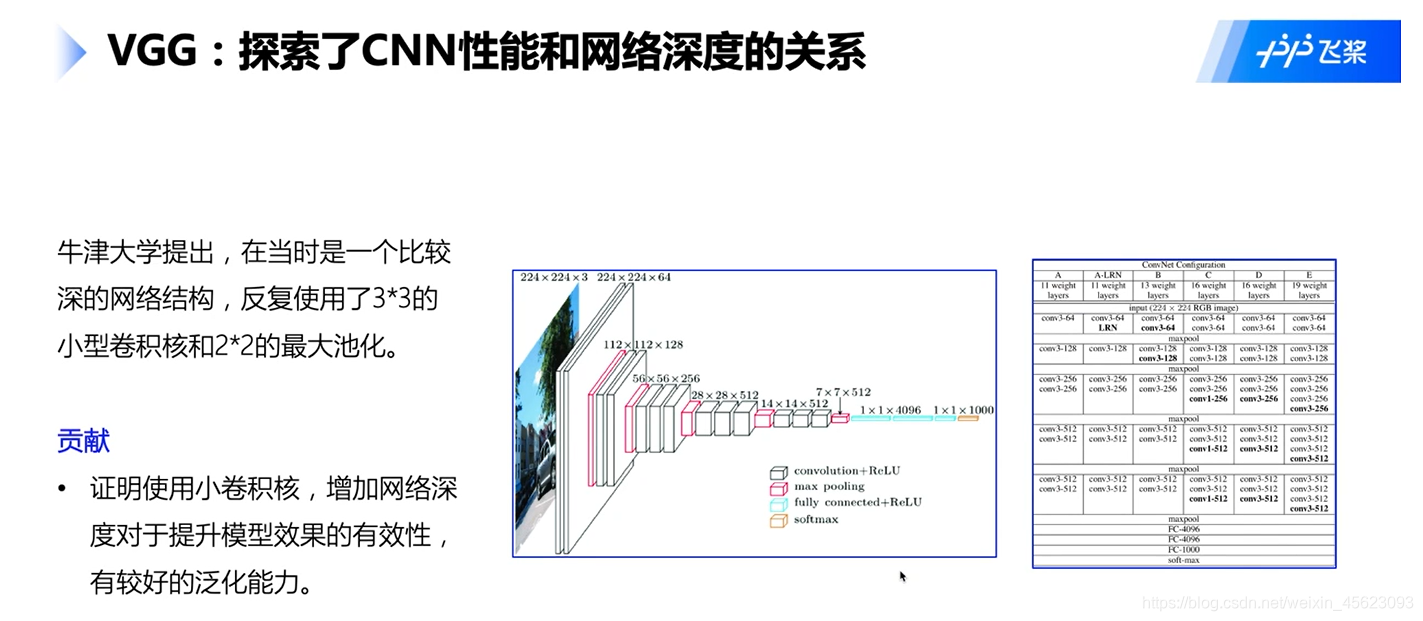
VGG
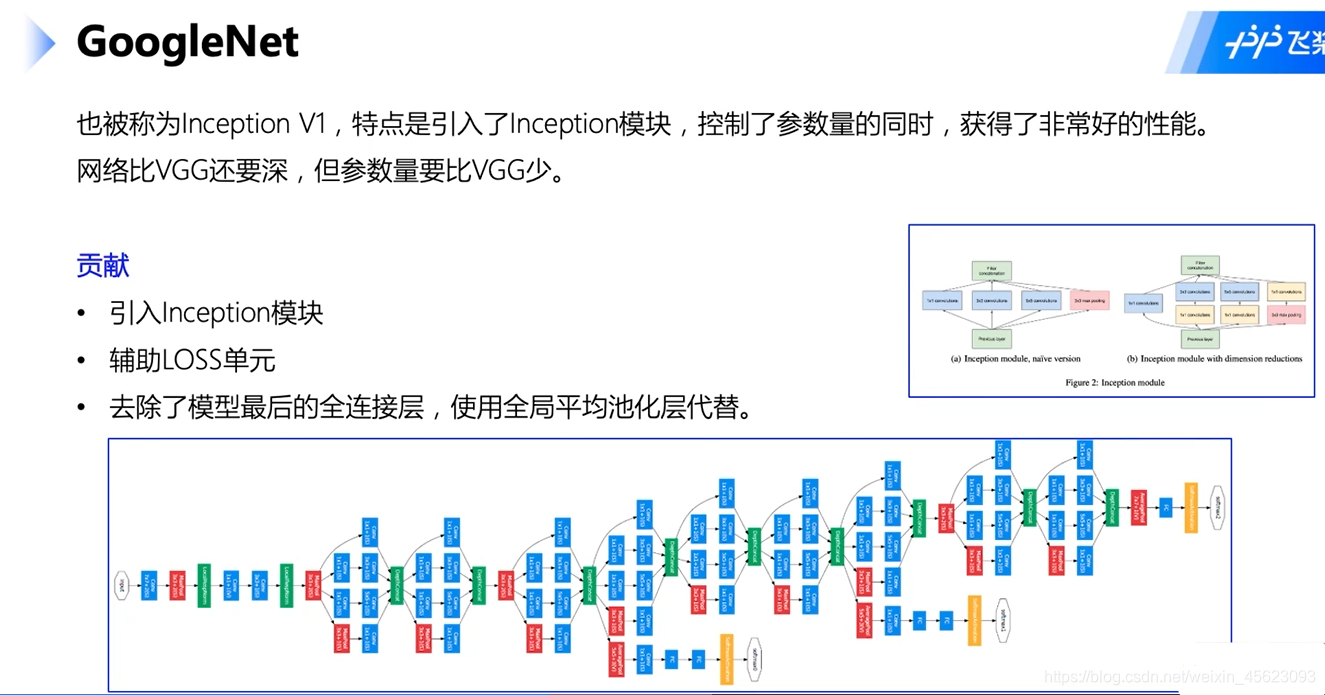
GoogleNet
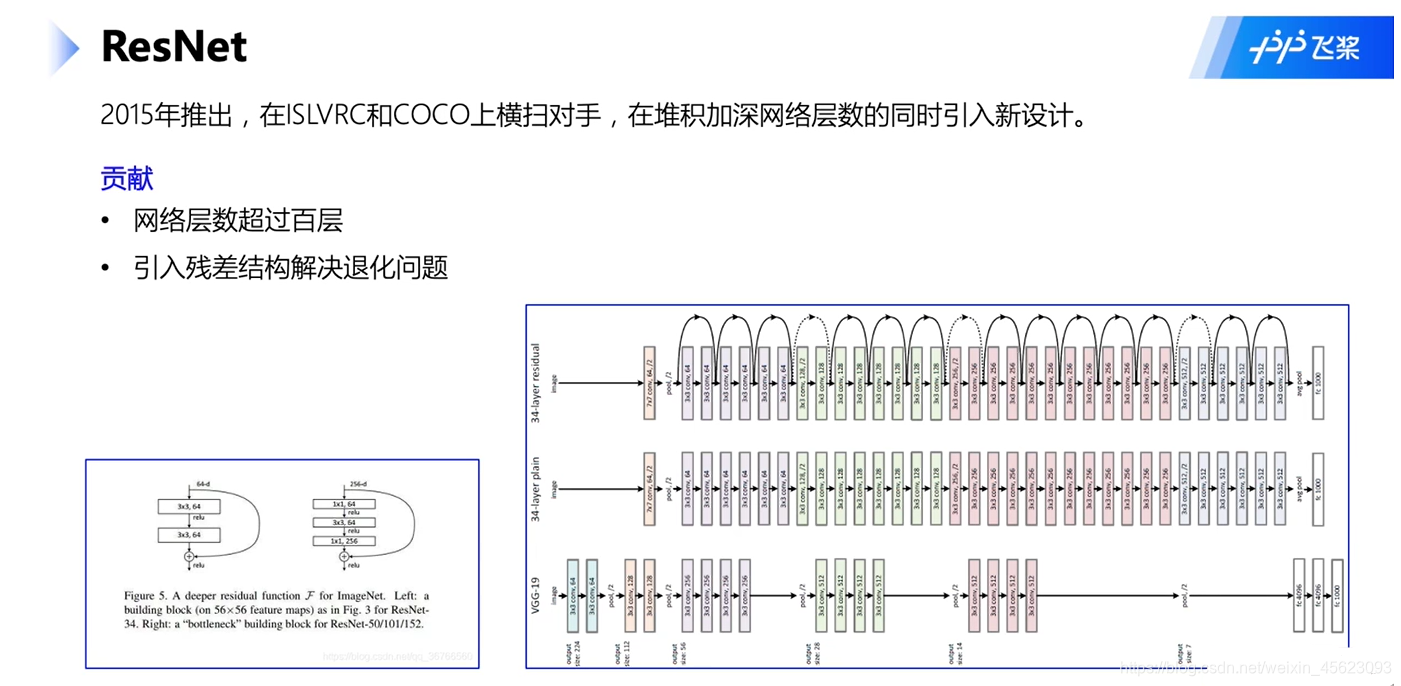
ResNet
十二生肖分类
数据 处理
解压数据集
!unzip -q -o data/data68755/signs.zip
此处以项目中的地址为准
目录结构
.
├── test
│ ├── dog
│ ├── dragon
│ ├── goat
│ ├── horse
│ ├── monkey
│ ├── ox
│ ├── pig
│ ├── rabbit
│ ├── ratt
│ ├── rooster
│ ├── snake
│ └── tiger
├── train
│ ├── dog
│ ├── dragon
│ ├── goat
│ ├── horse
│ ├── monkey
│ ├── ox
│ ├── pig
│ ├── rabbit
│ ├── ratt
│ ├── rooster
│ ├── snake
│ └── tiger
└── valid
├── dog
├── dragon
├── goat
├── horse
├── monkey
├── ox
├── pig
├── rabbit
├── ratt
├── rooster
├── snake
└── tiger
数据集分为train、valid、test三个文件夹,每个文件夹内包含12个分类文件夹,每个分类文件夹内是具体的样本图片。
我们对这些样本进行一个标注处理,最终生成train.txt/valid.txt/test.txt三个数据标注文件。
数据标记
# 导入第三方库
import io
import os
from PIL import Image
from config import get
# 数据集根目录
DATA_ROOT = 'signs'
# 标签List
LABEL_MAP = get('LABEL_MAP')
# 标注生成函数
def generate_annotation(mode):
# 建立标注文件
with open('{}/{}.txt'.format(DATA_ROOT, mode), 'w') as f:
# 对应每个用途的数据文件夹,train/valid/test
train_dir = '{}/{}'.format(DATA_ROOT, mode)
# 遍历文件夹,获取里面的分类文件夹
for path in os.listdir(train_dir):
# 标签对应的数字索引,实际标注的时候直接使用数字索引
label_index = LABEL_MAP.index(path)
# 图像样本所在的路径
image_path = '{}/{}'.format(train_dir, path)
# 遍历所有图像
for image in os.listdir(image_path):
# 图像完整路径和名称
image_file = '{}/{}'.format(image_path, image)
try:
# 验证图片格式是否ok
with open(image_file, 'rb') as f_img:
image = Image.open(io.BytesIO(f_img.read()))
image.load()
if image.mode == 'RGB':
f.write('{}\t{}\n'.format(image_file, label_index))
except:
continue
generate_annotation('train') # 生成训练集标注文件
generate_annotation('valid') # 生成验证集标注文件
generate_annotation('test') # 生成测试集标注文件
config.py文件对数据进行了对应通过get()获取相对应的数据
通过generate_annotation()对数据集进行了标注
最后的结果:

文件的绝对路径 对应的标识
数据集定义
这个内容在上面的dataset.py文件里面我们来解析一下
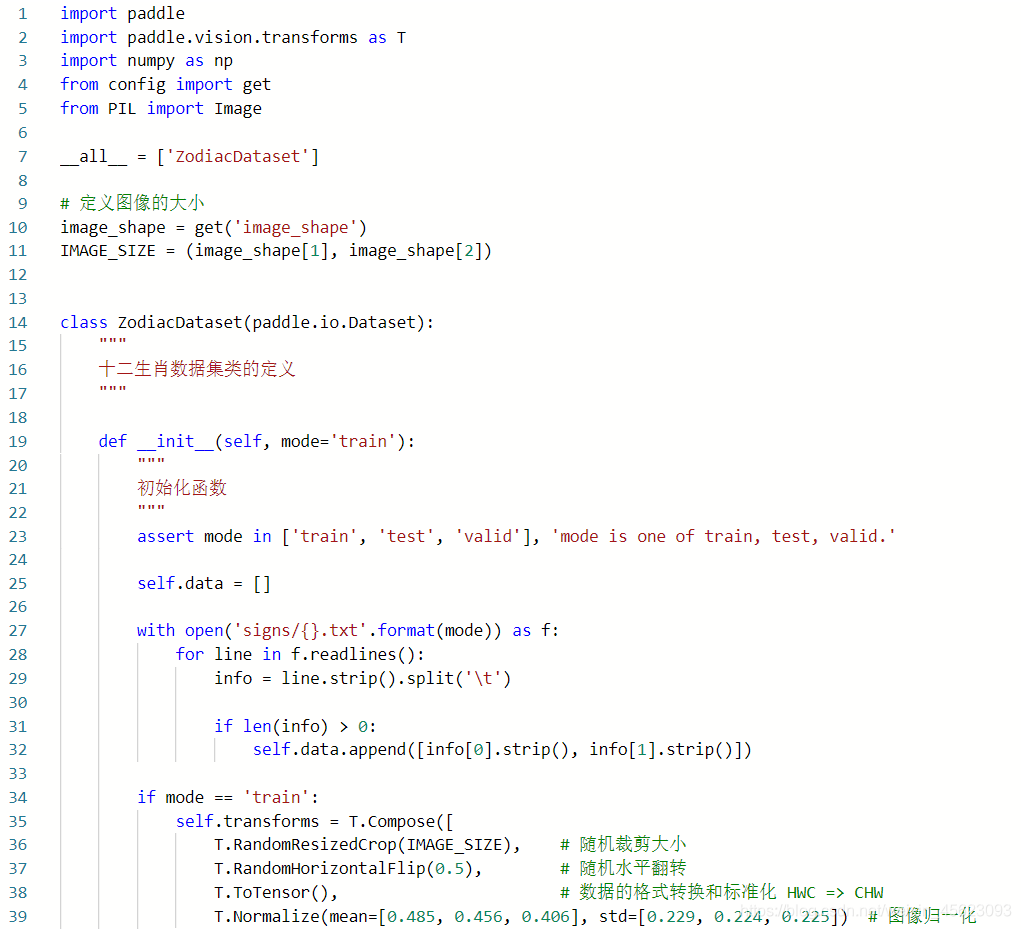

assert mode in ['train', 'test', 'valid'], 'mode is one of train, test, valid.'
self.data = []
with open('signs/{}.txt'.format(mode)) as f:
for line in f.readlines():
info = line.strip().split('\t')
if len(info) > 0:
self.data.append([info[0].strip(), info[1].strip()])
用assert判断mode是不是在’train’, ‘test’, 'valid’里面
然后对图片进行读取
if mode == 'train':
self.transforms = T.Compose([
T.RandomResizedCrop(IMAGE_SIZE), # 随机裁剪大小
T.RandomHorizontalFlip(0.5), # 随机水平翻转
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化
])
else:
self.transforms = T.Compose([
T.Resize(256), # 图像大小修改
T.RandomCrop(IMAGE_SIZE), # 随机裁剪
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化
])
利用paddle.vision.transforms函数对训练集进行数据增强
模型选择和开发
- ResNet50结构

模型实例化
模型可视化
model = paddle.Model(network)
model.summary((-1, ) + tuple(get('image_shape')))
模型训练和优化
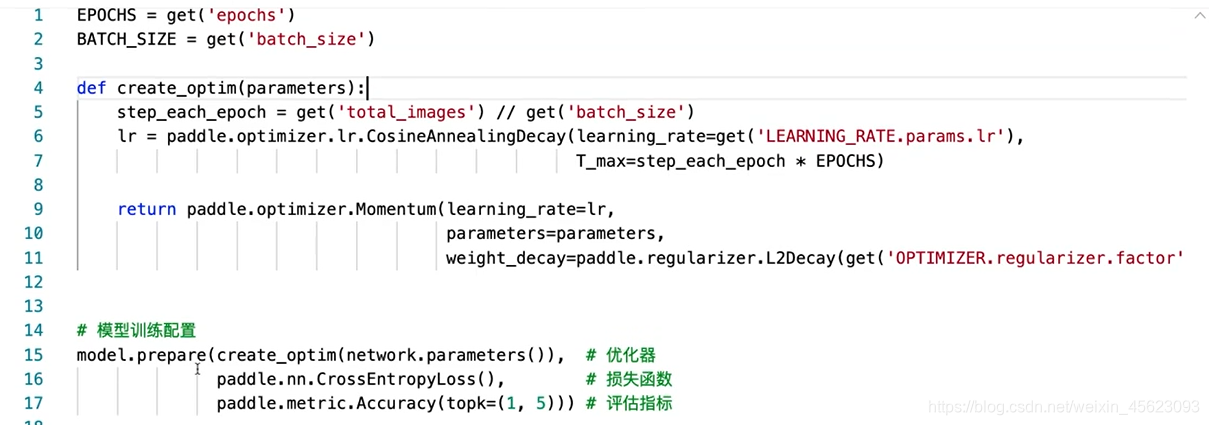

模型存储
model.save(get('model_save_dir'))
测试数据集
predict_dataset = ZodiacDataset(mode='test')
print('测试数据集样本量:{}'.format(len(predict_dataset)))
模型预测
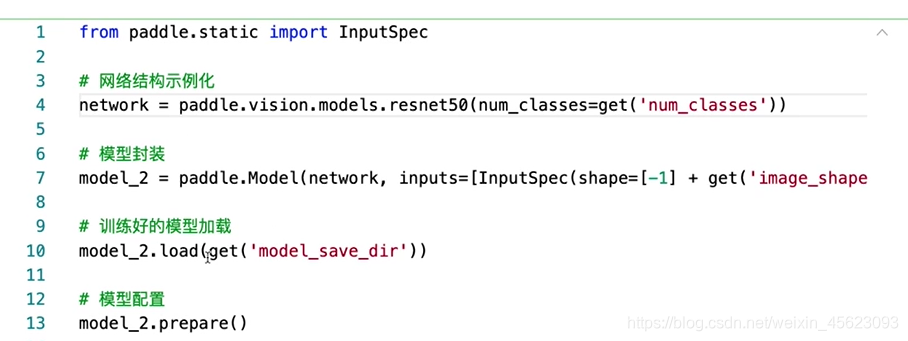

# 样本映射
LABEL_MAP = get('LABEL_MAP')
# 随机取样本展示
indexs = [2, 38, 56, 92, 100, 303]
for idx in indexs:
predict_label = np.argmax(result[0][idx])
real_label = predict_dataset[idx][1]
print('样本ID:{}, 真实标签:{}, 预测值:{}'.format(idx, LABEL_MAP[real_label], LABEL_MAP[predict_label]))
模型部署
model_2.save('infer/zodiac', training=False)
那么今天就到这里了!
整理
第二天的课程,以十二生肖分类为引子,提出了卷积神经网络的学习,利用手写数字识别项目详细解析了卷积网络,说清楚了卷积层,池化层等非常生涩的内容,最后以十二生肖分类项目,带领大家从头到尾的学习。很棒!
总结
今天在昨天的基础上,从原来的神经网络升级到了卷积神经网络,里面涉及到了一些比较不是很好理解的东西然后花了差不多7个小时整理,但还是有所欠缺的,还有继续努力。
这里是三岁,飞桨社区最菜的小白
我在AI Studio上获得黄金等级,点亮7个徽章,来互关呀~
CSDN首页
如果喜欢记得关注呦!!!
三岁出品虽水必精!