paddle深度学习高层API第二天
大家好,这里是三岁,别的不会,擅长白话,今天就是我们的白话系列,内容是paddle2.0新出的高程API,在这里的七日打卡营0基础学习,emmm我这个负基础的也来凑凑热闹,那么就开始吧~~~~
注:以下白话内容为个人理解,如有不同看法和观点及不对的地方欢迎大家批评指正!
书写数字识别(神经网络)项目传送门
卷积神经网络基础项目传送门
什么是十二生肖分类
基于实践对网络进行拓展
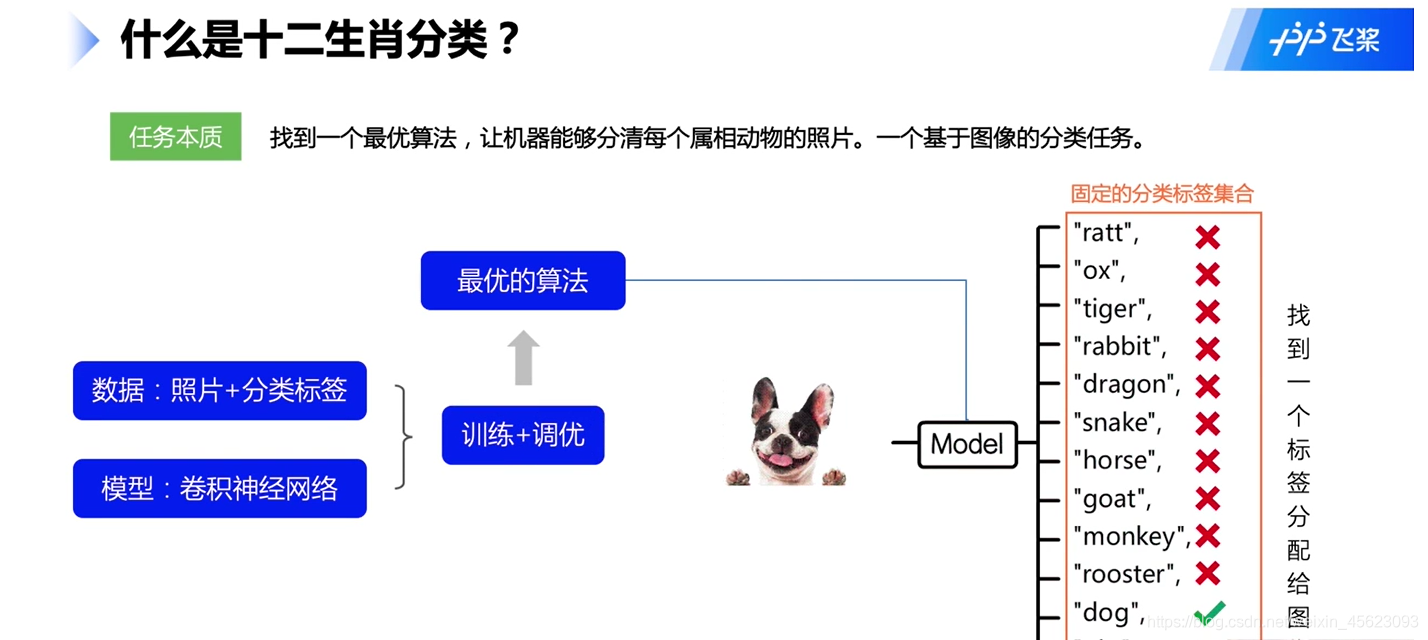
通过数据集在网络中不断的进行训练然后经过调参,得到一个比较理想的模型
白话:你上课老师教你认十二生肖,最后你基本上认识了,你所学习到的知识就相当于是模型。
- 拓展:一个图片认知不是很简单?so easy 妈妈再也不担心我不会深度学习!
等等,你看到的是一张图,而计算机看到的是像素点是0-255的一个值(或者是处理以后的值),这个时候会出现一种神奇的东西叫做语义鸿沟!

注:上图源于AI小鸭学院—小白逆袭大神课程
这样子我们就可以想象机器学习分类比我们更难!
典型的分类问题有哪些
-
按照分类场景分

paddle.vision.datasets中paddle自带了一些经典数据集就包括了Cifar10、Cifar100、MNIST(手写分类识别)
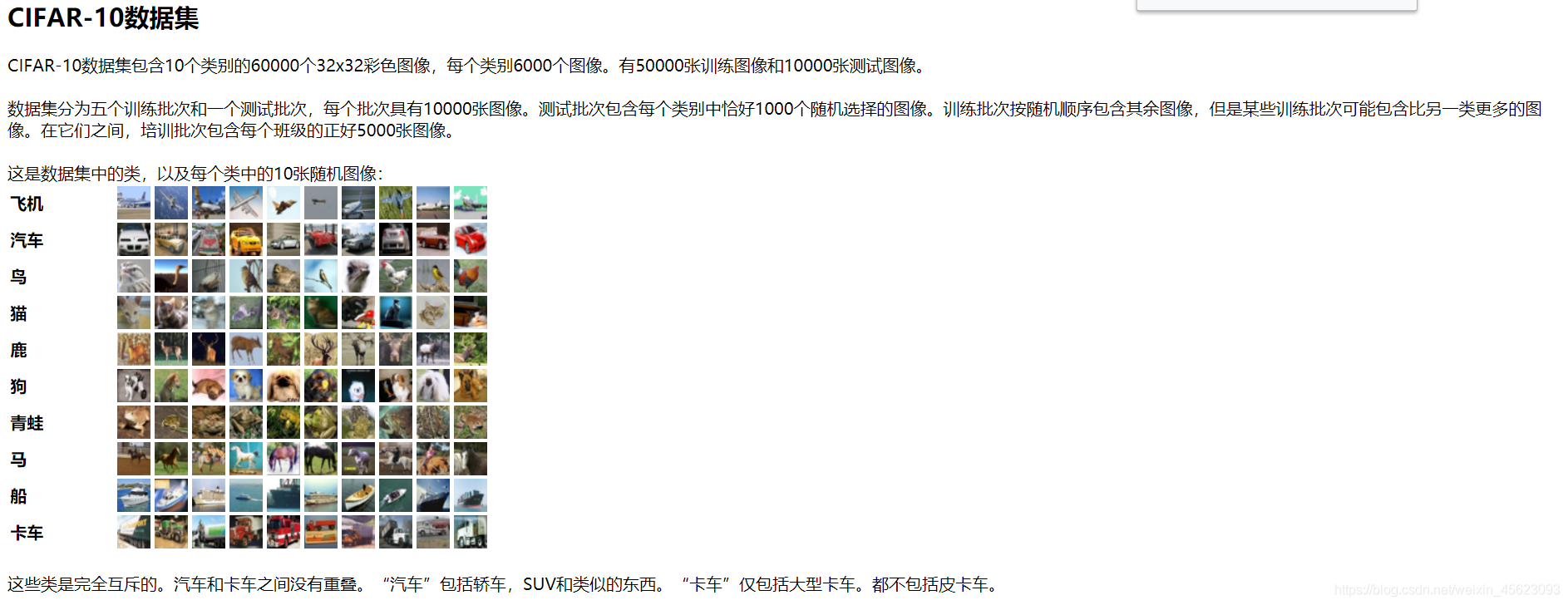

这些都是深度学习领域古老但是经典的分类数据集了(手写的请参考第一天的课程) -
按照分类类别分
二分类,多分类,多标签分类……

图像分类原理
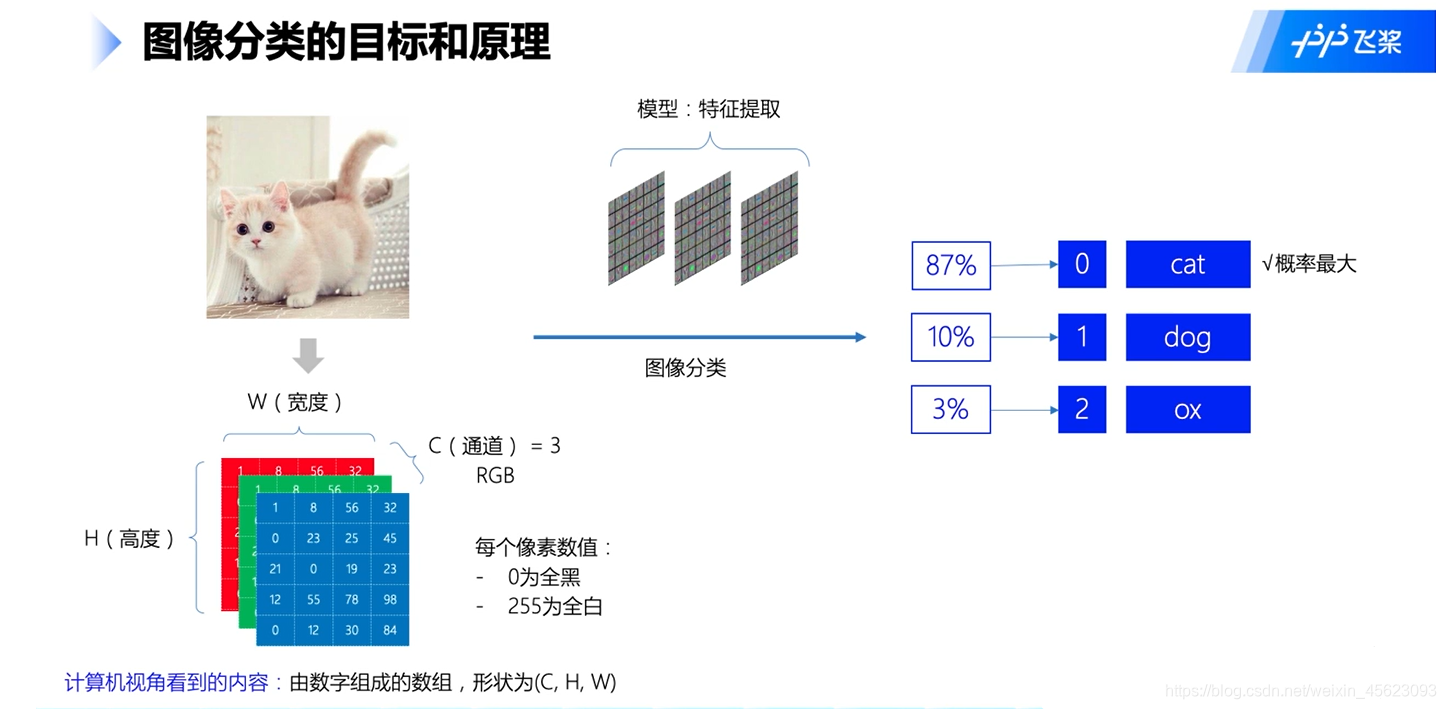
计算机的视角:
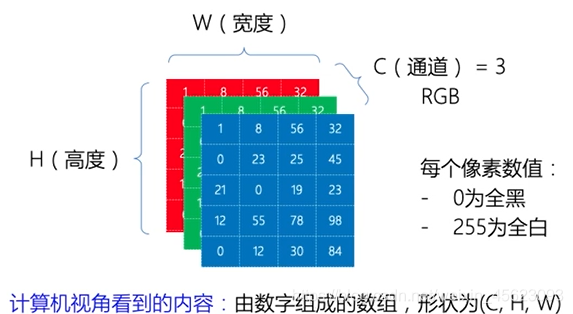
一张彩色的图片涉及到了一个通道的问题,彩色的是三通道,代表着这个图里面的c(相对应第三维度的值)
这里面的w,h相对应图片的宽度和高度,就是传说中的像素比如(2828)(800800)
白话:
这个东西这么理解呢,说实话很抽象,
大家看一个平面像不像是长方形,w和h对应的是长方形的长和宽,c相对应长方体的高,
假设该图的像素是2828的那么我们就可以理解为是长,宽,高分别是2828*3的立方体(只是举例)
那么用paddleTensor表示就是(3, 28, 28)(依次是高维度到底维度)(相对应高,宽,长)
计算机的工作:
计算机对上面的数据进行分析,查看里面的一些特征,然后通过特征分析各种东西的比例。
可以理解为你在玩猜猜猜的游戏,通过一些特征猜到一个结果。
计算机的绊脚石

这些丢是对计算机的一种考验,也是对深度学习的一种考验和挑战
卷积神经网络
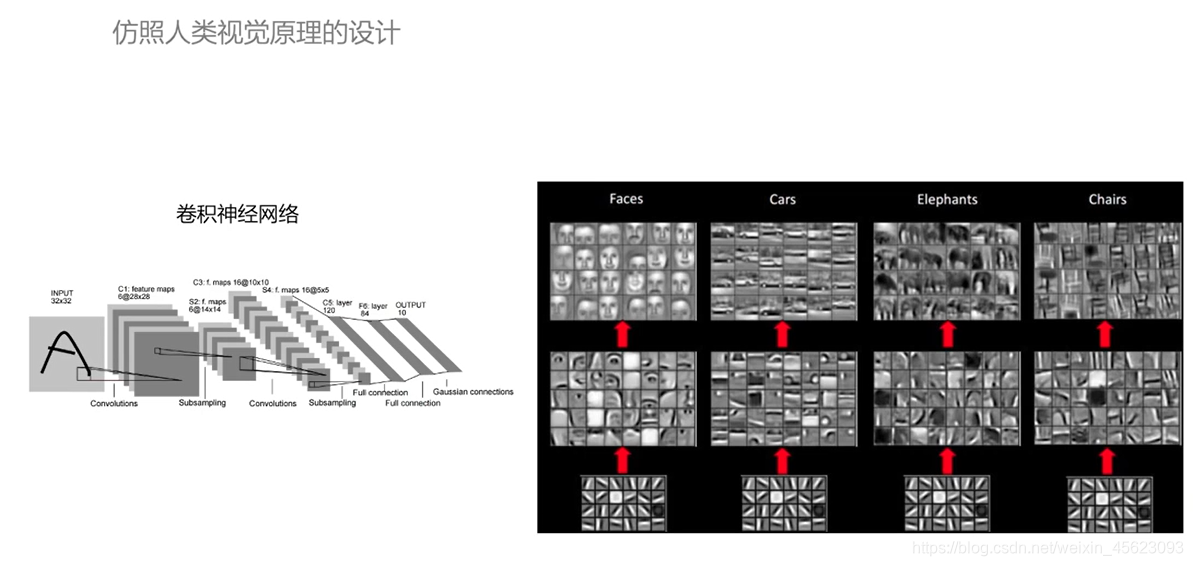
从原始信号—>发现边缘和方向—>不断抽象—>不断抽象
发展史
开山鼻祖:CNN
网络详解
卷积操作
单通道卷积
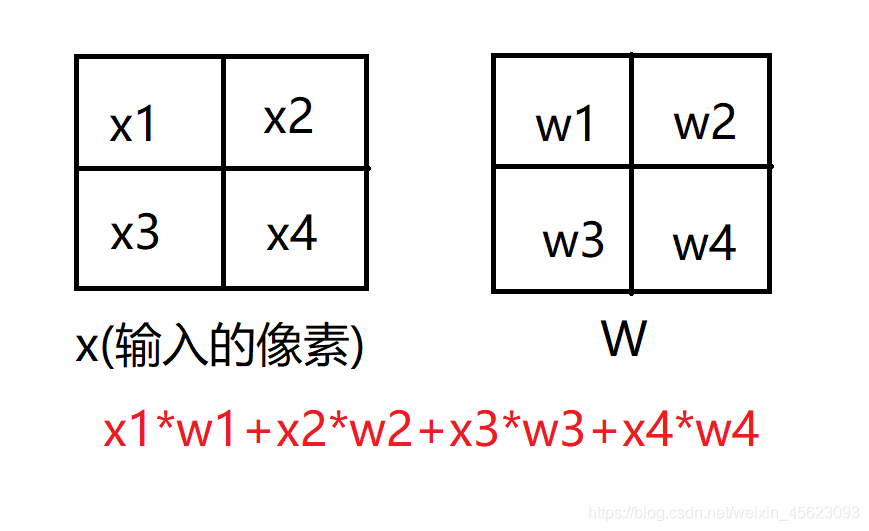
y = w * x + b (x是输入,y是输出,w是卷积核,b是贝叶斯)
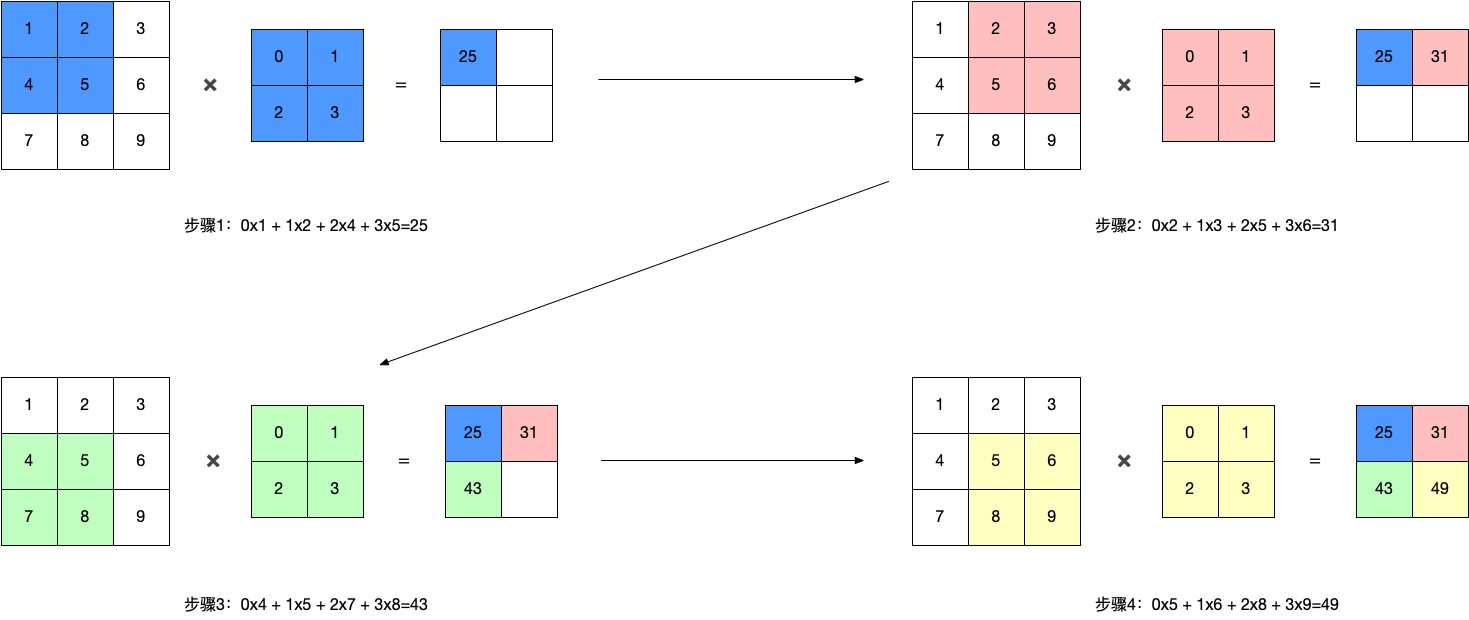
在这里面涉及连个概念,计算和步长
计算:
大家找找规律就ok
步长:
以上图为例:步长就是1,他的间隔就是一个像素(单位),以此类推
经过计算以后就得到了一个特征提取以后得到的特征核
得到的结果大小

以上面例子为例:
w=3(xw)+0(20)-2(f-w)/1+1=2
h=3(xh)+0(20)-2(f-h)/1+1=2
所以得到的结果是2*2的结果
多通道卷积

这里多通道对应的卷积核也是相应维度的,分别计算出对应维度的结果如何把对应位置的加起来就是最后输出的降维结果
1101 = 805 + 271 + 25
这里三通道的数据经过一个卷积核得到了一个单通道的表示
多通道输出
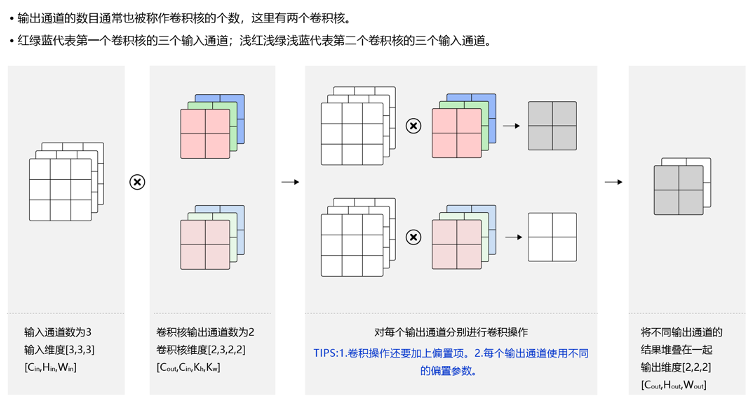
通过多个卷积核得到多个特征然后再堆叠得到一个多通道的输出
Batch
卷积核信息不变,卷积操作会多一定的倍数(和样本数有关)。
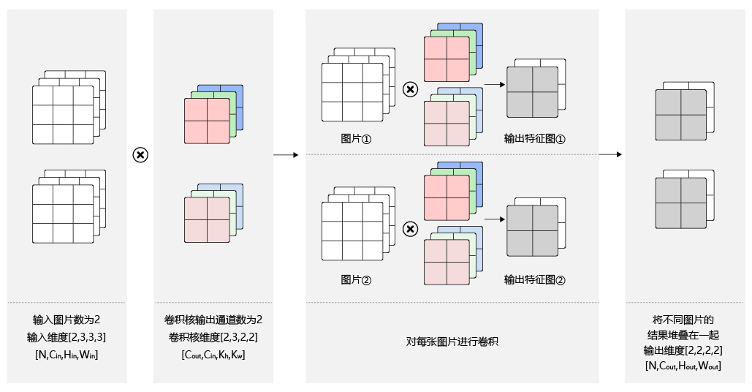
这个和上面的一样多个输入和多个卷积核通过卷积生成图
填充操作( Padding的由来):
角落边缘的像素,只被一个过滤器输出所使用,因为它位于这个3×3的区域的一角。但如果是在中间的像素点,就会有许多3×3的区域与之重叠。
所以那些在角落或者边缘区域的像素点在输出中采用较少,意味着你丢掉了图像边缘位置的许多信息。
那么出现的一个解决办法就是填充操作,在原图像外围以0进行填充,在不影响特征提取的同时,增加了对边缘信息的特征提取。
另外一个好处是,我们在做卷积操作时,每经过一次卷积我们的输入图像大小就会变小,最后经过多次卷积可能我们的图像会变得特别小,我们不希望图像变小的话就可以通过填充操作。
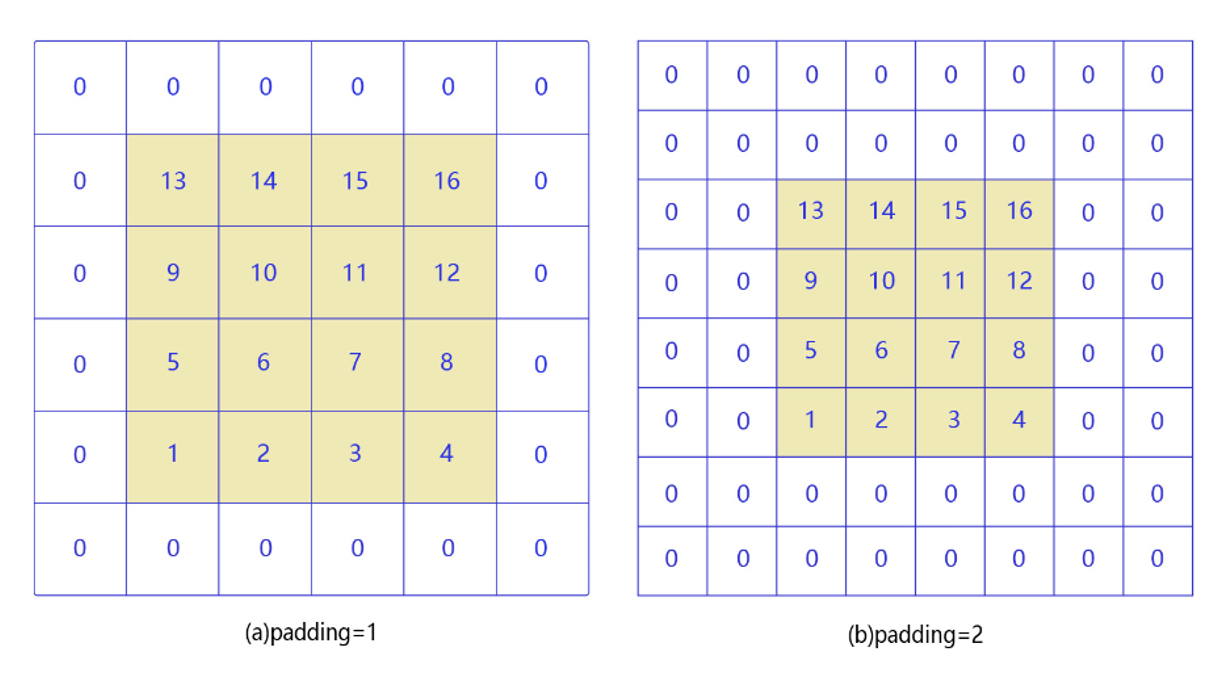
白话:就是边缘的一些内容有可能就只被收集了一次特征,但是中心的确有多次,那么边上的信息数据就会丢失或者木有那么的清晰,这个是如果填充空白的数据那么就可以比较好的解决问题,同时可以解决图像变小带来的某些时候不必要的麻烦
池化层
池化是使用某一位置的相邻输出的总体统计特征代替网络在该位置的输出,其好处是当输入数据做出少量平移时,经过池化函数后的大多数输出还能保持不变。比如:当识别一张图像是否是人脸时,我们需要知道人脸左边有一只眼睛,右边也有一只眼睛,而不需要知道眼睛的精确位置,这时候通过池化某一片区域的像素点来得到总体统计特征会显得很有用。由于池化之后特征图会变得更小,如果后面连接的是全连接层,能有效的减小神经元的个数,节省存储空间并提高计算效率。
池化的作用
池化层是特征选择和信息过滤的过程,过程中会损失一部分信息,但是会同时会减少参数和计算量,在模型效果和计算性能之间寻找平衡,随着运算速度的不断提高,慢慢可能会有一些设计上的变化,现在有些网络已经开始少用或者不用池化层。
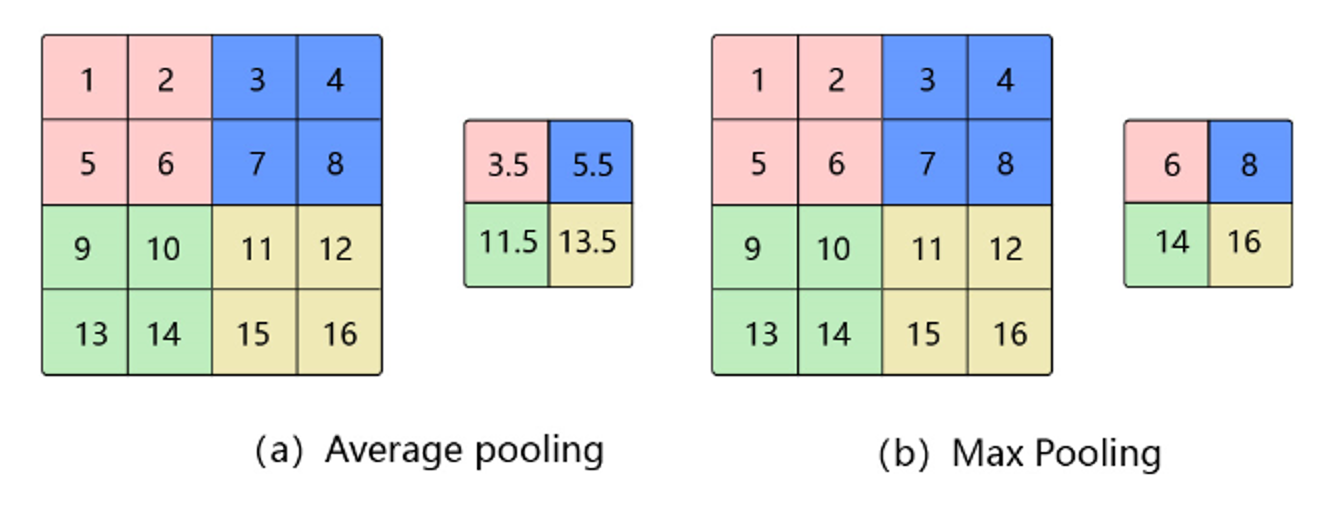
池化的步长和卷积核的大小有关,默认长度为2
平均池化(Avg Pooling)
对邻域内特征点求平均
- 优缺点:能很好的保留背景,但容易使得图片变模糊
- 正向传播:邻域内取平均
- 反向传播:特征值根据领域大小被平均,然后传给每个索引位置
最大池化(Max Pooling)
对邻域内特征点取最大
- 优缺点:能很好的保留一些关键的纹理特征,现在更多的再使用Max Pooling而很少用Avg Pooling
- 正向传播:取邻域内最大,并记住最大值的索引位置,以方便反向传播
- 反向传播:将特征值填充到正向传播中,值最大的索引位置,其他位置补0
计算结果的大小公示
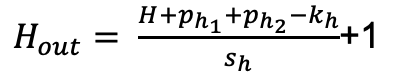
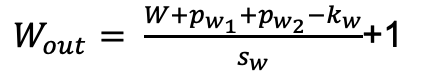
激活函数
Sigmoid
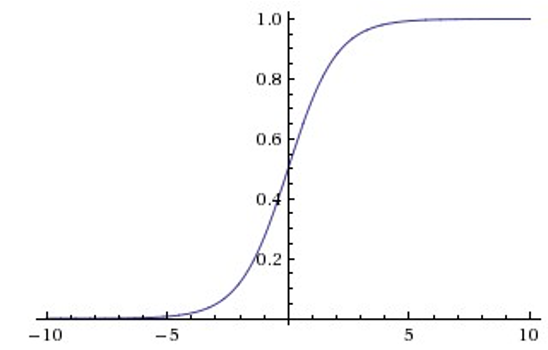
Tanh
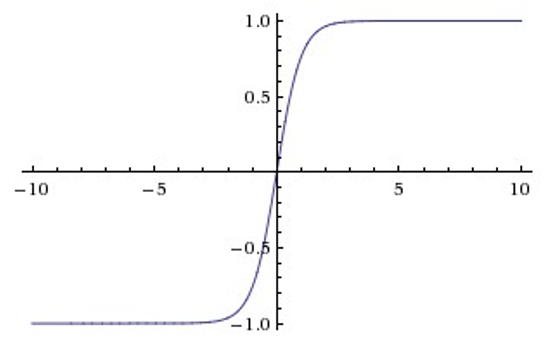
Sigmoid和Tanh激活函数有共同的缺点:即在z很大或很小时,梯度几乎为零,因此使用梯度下降优化算法更新网络很慢。
ReLU
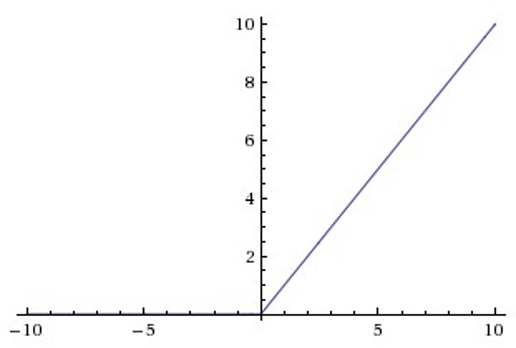
Relu目前是选用比较多的激活函数,但是也存在一些缺点,在z小于0时,斜率即导数为0。
为了解决这个问题,后来也提出来了Leaky Relu激活函数,不过目前使用的不是特别多。
手写数字识别
问题定义
图像分类,使用LeNet-5网络完成手写数字识别图片的分类。
# 导入第三方库
import paddle
import numpy as np
import matplotlib.pyplot as plt
paddle.__version__ # 判断版本
‘2.0.0’
数据准备
- 数据加载与预处理

# 数据预处理
import paddle.vision.transforms as T
# 数据预处理,TODO:找一下提出的原论文看一下(归一化处理)
transform = T.Normalize(mean=[127.5], std=[127.5])
# 训练数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 验证数据集
eval_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('训练样本量:{},测试样本量:{}'.format(len(train_dataset), len(eval_dataset)))
训练样本量:60000,测试样本量:10000
这里的处理方式和昨天的是一样,先定义transform(一个归一化处理,把数据归一到(-1,1)的区间)
- 数据查看
print('图片:')
print(type(train_dataset[0][0]))
print(train_dataset[0][0])
print('标签:')
print(type(train_dataset[0][1]))
print(train_dataset[0][1])
# 可视化展示
plt.figure()
plt.imshow(train_dataset[0][0].reshape([28,28]), cmap=plt.cm.binary)
plt.show()
这里和第一天的数据也是一样的,就是解释了train_dataset和昨天理解的其实是一样的,一个[0]取的是整个生成器的第一个值,第二个[0]取的是image
train_dataset[0]里面的内容是(image,lable)
模型选择和开发
- 网络结构定义
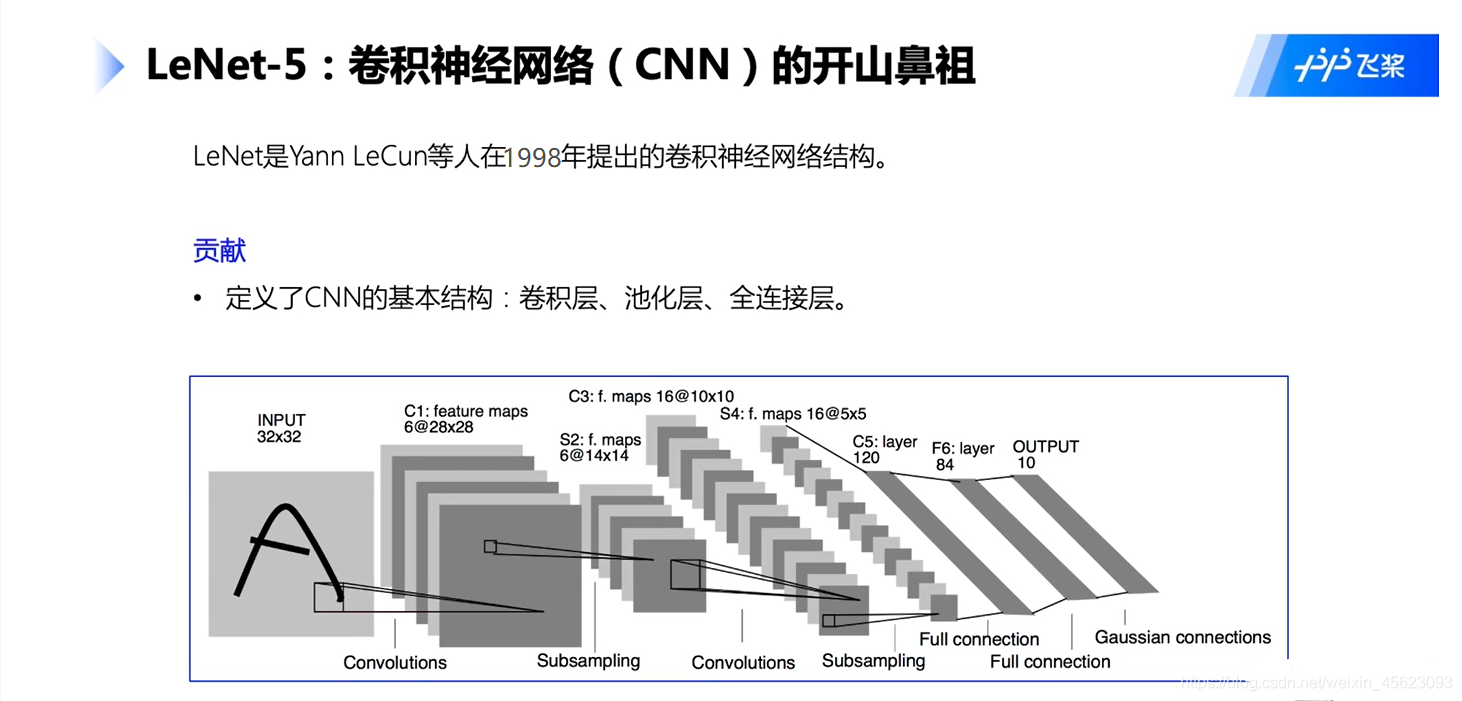
我们选用LeNet-5网络结构。
LeNet-5模型源于论文“LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.”,
论文地址:https://ieeexplore.ieee.org/document/726791


论文模型
- 代码解析
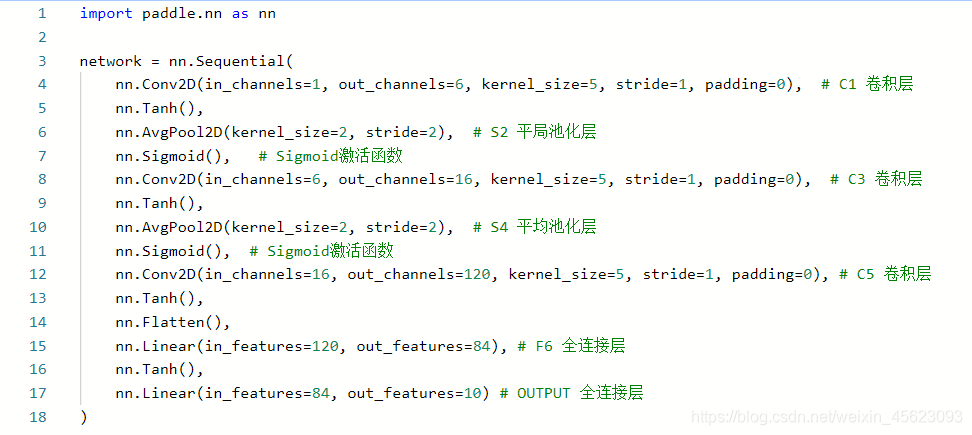
import paddle.nn as nn
network = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0), # C1 卷积层
nn.Tanh(),
nn.AvgPool2D(kernel_size=2, stride=2), # S2 平局池化层
nn.Sigmoid(), # Sigmoid激活函数
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0), # C3 卷积层
nn.Tanh(),
nn.AvgPool2D(kernel_size=2, stride=2), # S4 平均池化层
nn.Sigmoid(), # Sigmoid激活函数
nn.Conv2D(in_channels=16, out_channels=120, kernel_size=5, stride=1, padding=0), # C5 卷积层
nn.Tanh(),
nn.Flatten(),
nn.Linear(in_features=120, out_features=84), # F6 全连接层
nn.Tanh(),
nn.Linear(in_features=84, out_features=10) # OUTPUT 全连接层
)
nn.Tanh():激活函数
nn.Flatten():数据拉平
- 模型可视化
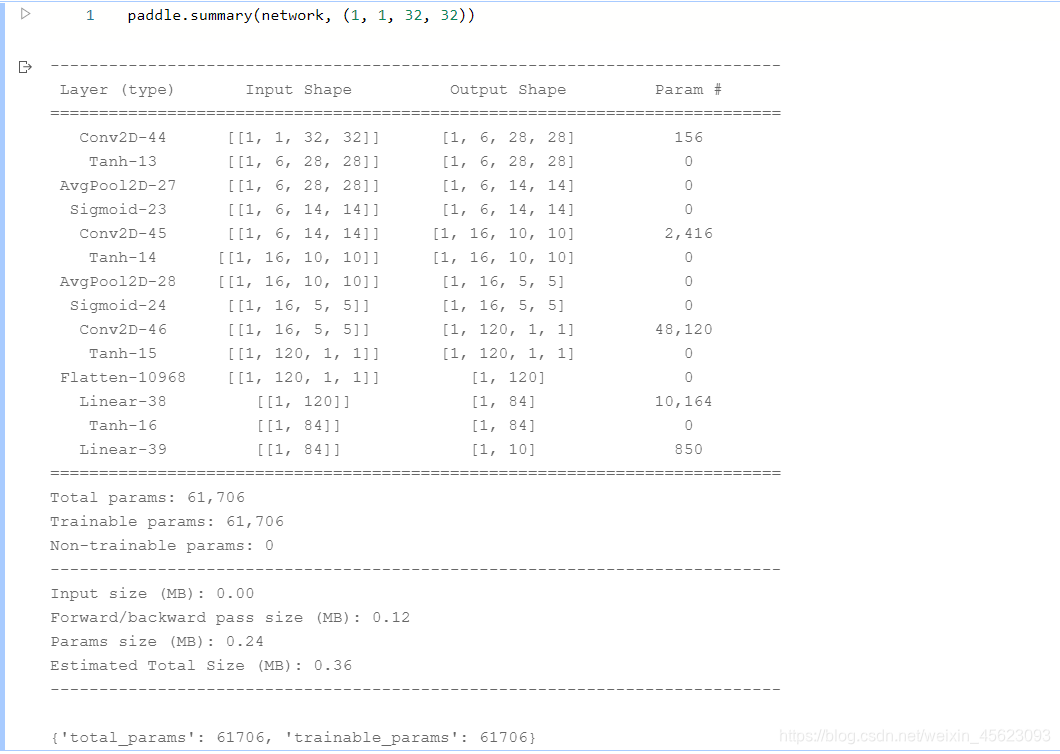
Sequential(新的技术)
- 代码解析
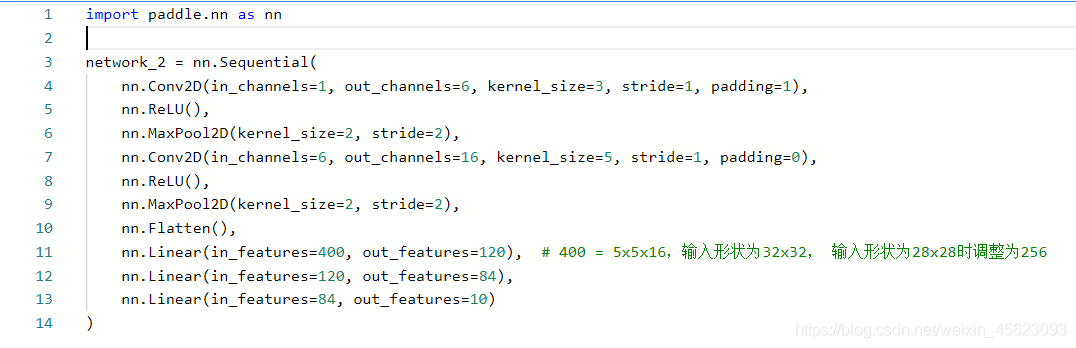
import paddle.nn as nn
network_2 = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=1), # 卷积
nn.ReLU(), # 激活函数
nn.MaxPool2D(kernel_size=2, stride=2), # 最大池化
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2D(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(in_features=400, out_features=120), # 400 = 5x5x16,输入形状为32x32, 输入形状为28x28时调整为256
nn.Linear(in_features=120, out_features=84),
nn.Linear(in_features=84, out_features=10)
)
- 模型可视化
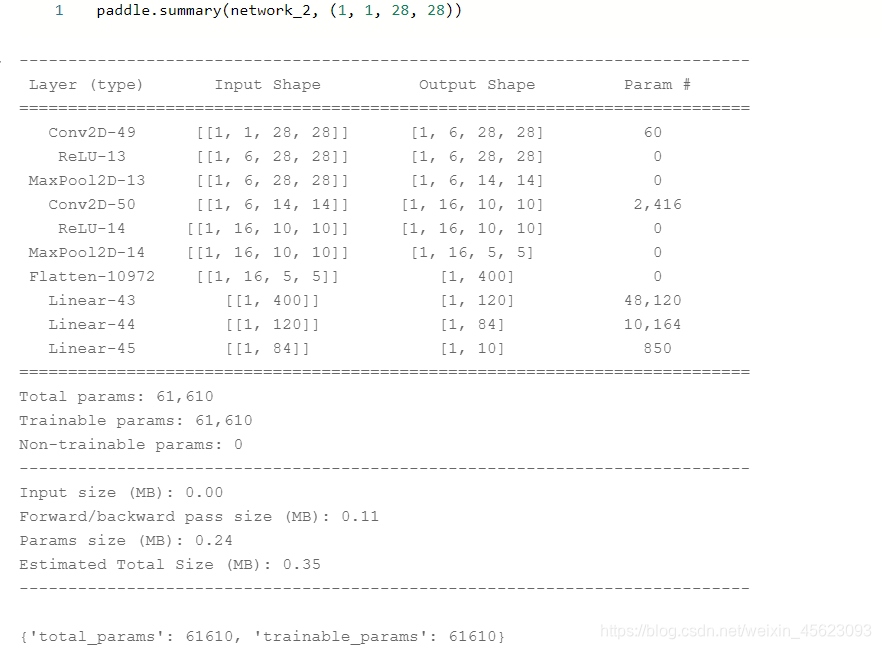
这个地方把数据进行了修改使其贴合我们的实践(手写数字识别)
类继承方式书写
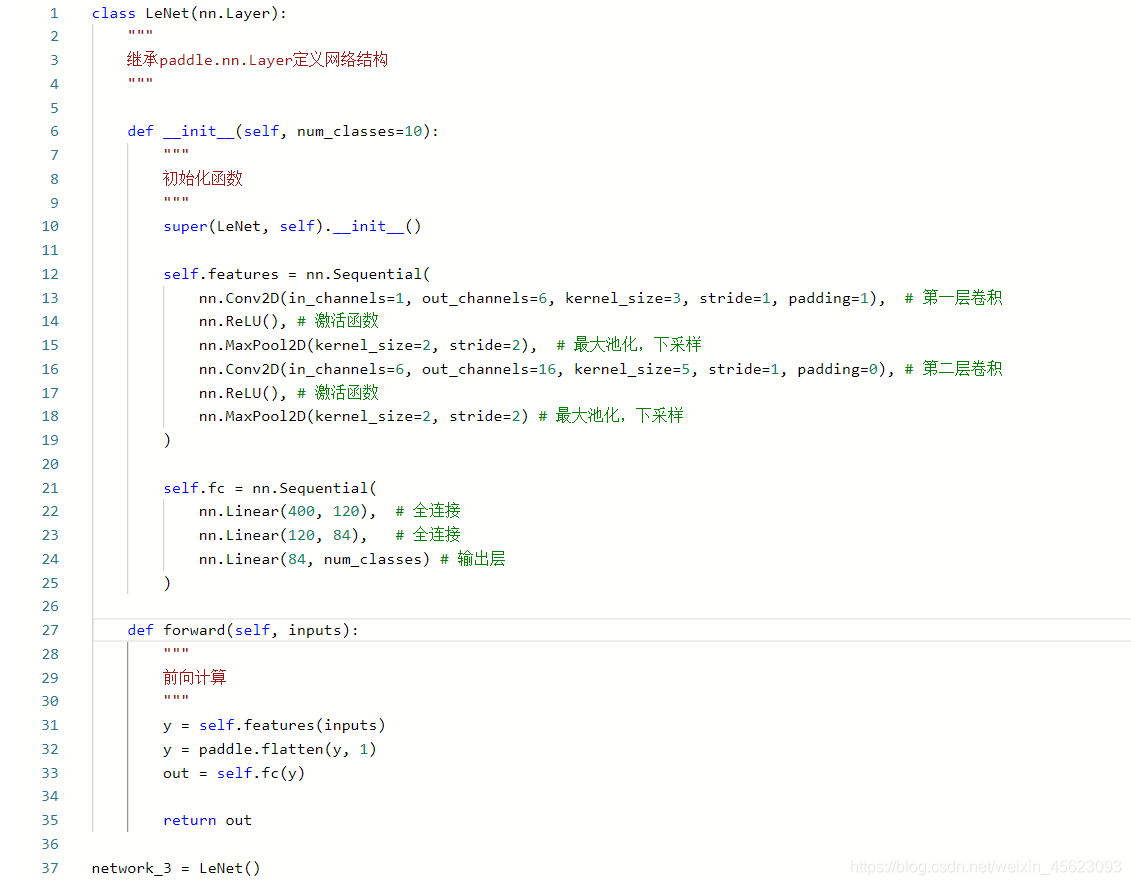
class LeNet(nn.Layer):
"""
继承paddle.nn.Layer定义网络结构
"""
def __init__(self, num_classes=10):
"""
初始化函数
"""
super(LeNet, self).__init__()
# 卷积
self.features = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=1), # 第一层卷积
nn.ReLU(), # 激活函数
nn.MaxPool2D(kernel_size=2, stride=2), # 最大池化,下采样
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0), # 第二层卷积
nn.ReLU(), # 激活函数
nn.MaxPool2D(kernel_size=2, stride=2) # 最大池化,下采样
)
# 全连接
self.fc = nn.Sequential(
nn.Linear(400, 120), # 全连接
nn.Linear(120, 84), # 全连接
nn.Linear(84, num_classes) # 输出层
)
def forward(self, inputs):
"""
前向计算
"""
y = self.features(inputs)
y = paddle.flatten(y, 1) # 拉平成一维
out = self.fc(y)
return out
network_3 = LeNet() # 实例化类
- 模型可视化
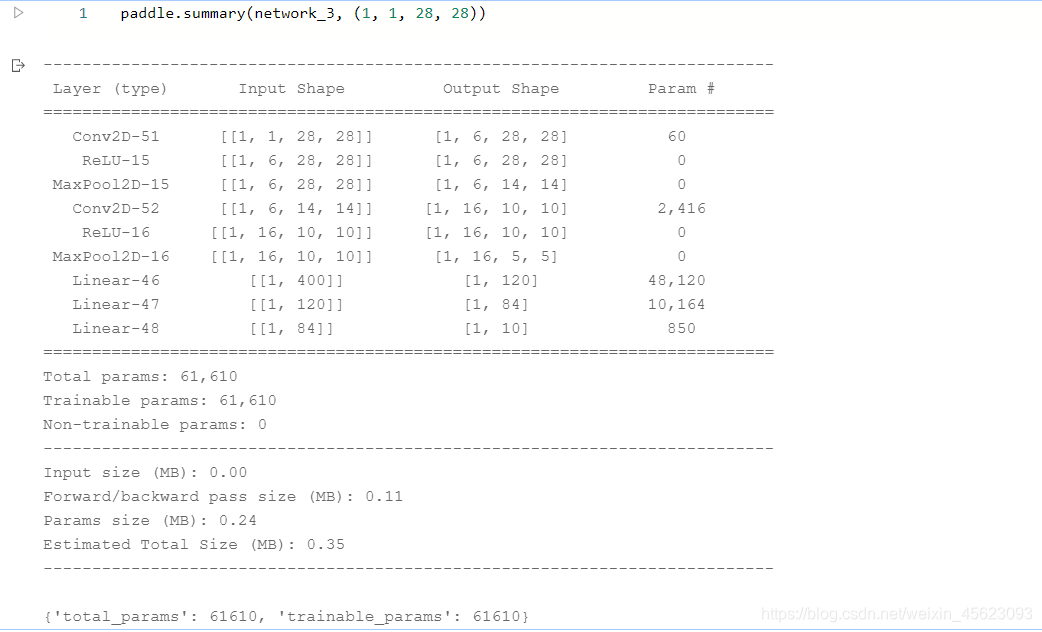
这个地方和上面Sequential的卷积网络一样只是实现的方法不一样
在注释里面已经标注了每一部分的意义
网络结构代码实现
network_4 = paddle.vision.models.LeNet(num_classes=10)
paddle.vision.models.LeNet():LeNet模型
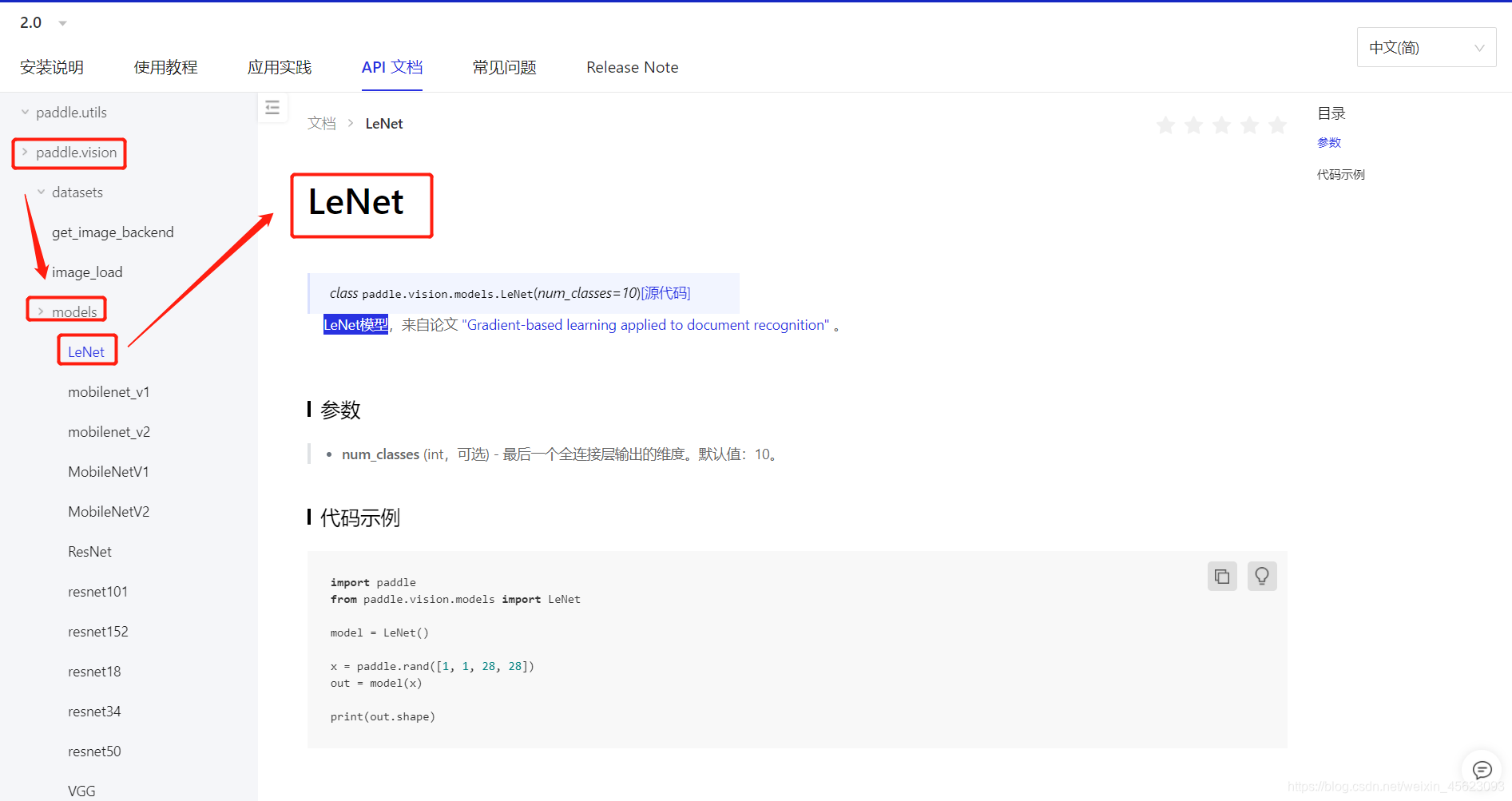
- 模型的可视化
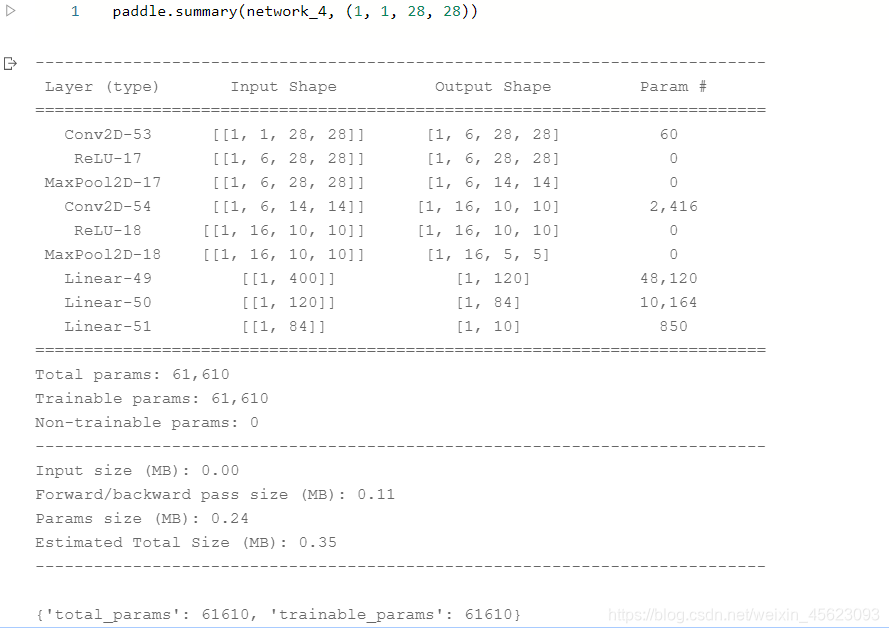
模型训练和优化

# 模型封装
model = paddle.Model(network_4)
# 模型配置
model.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy()) # 评估指标
# 启动全流程训练
model.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=5, # 训练轮次
batch_size=64, # 单次计算数据样本量
verbose=1) # 日志展示形式
评估预测,保存,再训练,保存预测模型
# 评估
result = model.evaluate(eval_dataset, verbose=1)
print(result)
# 进行预测操作
result = model.predict(eval_dataset)
# 保存模型
model.save('finetuning/mnist')
# 继续调优
from paddle.static import InputSpec
network = paddle.vision.models.LeNet(num_classes=10)
# 模型封装,为了后面保存预测模型,这里传入了inputs参数
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1, 1, 28, 28], dtype='float32', name='image')])
# 加载之前保存的阶段训练模型
model_2.load('finetuning/mnist')
# 模型配置
model_2.prepare(paddle.optimizer.Adam(learning_rate=0.0001, parameters=network.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy()) # 评估函数
# 模型全流程训练
model_2.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=2, # 训练轮次
batch_size=64, # 单次计算数据样本量
verbose=1) # 日志展示形式
# 保存用于后续推理部署的模型
model_2.save('infer/mnist', training=False)
这部分和第一天的数据基本一样,可以查看第一天的数据进行学习
由于篇幅过长,下面的内容放在第二篇。
第二篇传送门
这里是三岁,飞桨社区最菜的小白
我在AI Studio上获得黄金等级,点亮7个徽章,来互关呀~
CSDN首页
如果喜欢记得关注呦!!!