数据采集
数据采集(Date Capture),又叫做数据获取,数据采集是将系统需要管理的所有对象的原始数据(外部数据)进行一系列的操作并输入到系统内部的一个接口。像摄像头、麦克风等等,都是数据采集工具,而在计算机世界,相应的数据采集工具就更多了,简单的采集工具有Hawk、八爪鱼等。在计算机广泛应用的今天,数据采集在多个领域具有非常重要的意义。它是计算机与外部物理世界连接的桥梁。
前几个月做了一个互联网加项目,是基于机器学习的一个简历招聘推荐系统
今天就分享一下当时爬取Boss直聘时的爬虫代码
用到的库
- Python3
- selenium
- BeautifulSoup
- os
- io
- re
简述思路
第一步 查看网站url与网站标签
可以看到所有的子网页与招聘职位便签都是有规律的,所以咱们可以从这里下手
代码
import io
import os
import re
import time
from bs4 import BeautifulSoup
from selenium.webdriver import Chrome
#寻找网站
def find_boss():
main_html = BeautifulSoup(browser.page_source, "lxml")
htmls_two = main_html.find_all("a", href=re.compile('\w.*?-\w.*?')) #寻找职位href
for html_two in htmls_two: #遍历
for i in range(1,100): #寻找下一页
browser.get(base_url+html_two['href']+'?page='+str(i)+'&ka=page-'+str(i))
print("第{}页".format(str(i))) #输出下一页
soup_one = BeautifulSoup(browser.page_source, 'lxml')
link_lists_nexts = soup_one.find_all('a', href=re.compile('job_detail/.*?~.html')) #寻找需要爬取的职位网站
for link_lists_next in link_lists_nexts: #遍历
html_end=base_url+link_lists_next['href']
browser.get(html_end)
reptilian() #执行爬虫函数
time.sleep(1)
#主函数
if __name__=='__main__':
#获取目标网站url 与 创建招聘信息文件
url='https://www.zhipin.com/?ka=header-home-logo'
base_url='https://www.zhipin.com'
#打开浏览器
browser=Chrome()
browser.get(url)
#主函数
find_boss()
#关闭浏览器
browser.close()
构造函数的时候使用了正则表达式匹配了第一页所有的招聘岗位网站
构造成功后可以爬虫就可以定位到想要爬取的具体招聘岗位网页了
第二步 爬取岗位具体信息
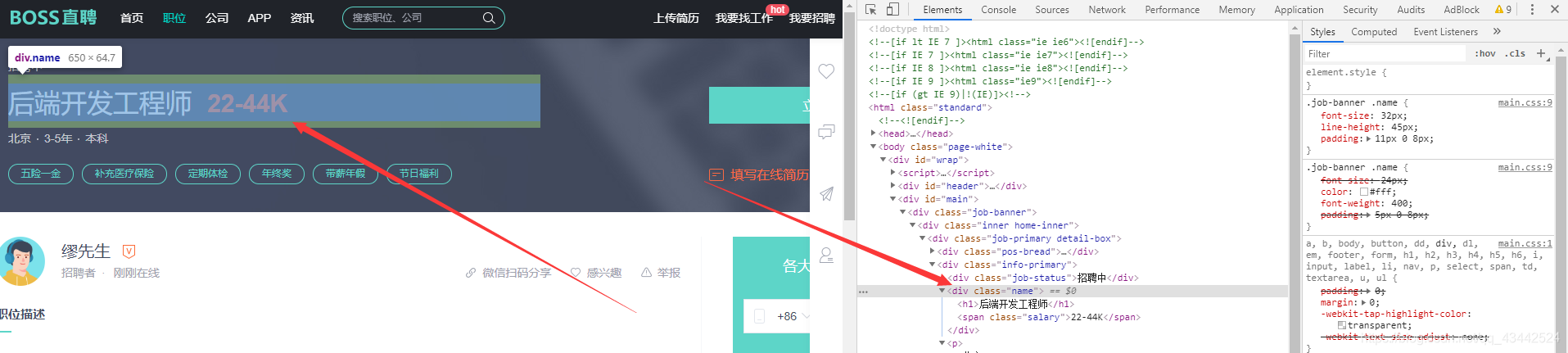
现在我们要根据要爬取的具体信息来分析标签了
#构造爬虫函数
def reptilian():
page_source=browser.page_source
soup=BeautifulSoup(page_source, 'html.parser')
#工作名称 学历 福利 工资
company_info=soup.find('div', class_='info-primary')
job_name = company_info.find('div', class_='name')
study_infor=company_info.find('p',)
job_tags=company_info.find('div',class_='job-tags')
describe=soup.find('div',class_='text')
#工作地址 公司名称
detail_content=soup.find('div', class_='detail-content')
company_name=detail_content.find('div', class_='name')
company_addr=detail_content.find('div',class_='location-address')
#去标签
job_name = ' '.join('%s' % id for id in job_name)
study_infor = ' '.join('%s' % id for id in study_infor)
job_tags = ' '.join('%s' % id for id in job_tags)
describe=' '.join('%s' % id for id in describe)
company_name = ' '.join('%s' % id for id in company_name)
company_addr = ' '.join('%s' % id for id in company_addr)
cut = re.compile(r'<[^>]+>', re.S)
job_name= cut.sub('', job_name)
study_infor= cut.sub('', study_infor)
job_tags= cut.sub('', job_tags)
company_name= cut.sub('', company_name)
company_addr= cut.sub('', company_addr)
describe = cut.sub('', describe)
f="-------------------------------------------------------------------------------------"
infors=str(job_name)+str(study_infor)+str(job_tags)+str(company_name)+str(company_addr)+'\n'+"职位描述 : "+'\n'+str(describe)+'\n'+str(f)+'\n'
write_data(file_path=file_path, file_name=file_name, data=infors)
可以添加个写入txt文件的函数,便于保存
# 创建文件函数(文件路径,文件名)
def establish_file(file_path, file_name):
# 文件路径
path = file_path + file_name
# 判断文件是否存在
if os.path.exists(path):
print(file_name + "文件已经存在,正在删除~~~~~")
# 删除原有的文件
os.remove(path)
print("原有文件已经删除,正在重新创建文件~~~~")
# 创建文件(文件路径, 打开方式‘w’只写, 编码格式)
f = io.open(path, 'w', encoding='utf-8')
# 关闭文件
f.close()
print("文件创建成功!")
# 将获取数据写入文件中(文件路径,文件名,数据)
def write_data(file_path, file_name, data):
# 文件路径
path = file_path + file_name
# 打开创建文件(文件路径,打开方式'a'追加, 编码格式)
f = io.open(path, 'a', encoding='utf-8')
print("正在写入" + file_name + "...")
# 数据写入文件
f.write(data)
print("写入成功")
# 关闭文件
f.close()
这样就成功将该招聘岗位的基本信息就爬取到了

自动化爬取
接下来就考虑将所有页数的与所有在招聘岗位自动化爬取了
import io
import os
import re
import time
from bs4 import BeautifulSoup
from selenium.webdriver import Chrome
# 创建文件函数(文件路径,文件名)
def establish_file(file_path, file_name):
# 文件路径
path = file_path + file_name
# 判断文件是否存在
if os.path.exists(path):
print(file_name + "文件已经存在")
else:
f = io.open(path, 'w', encoding='utf-8')
# 关闭文件
f.close()
print("文件创建成功!")
# 主函数
find_boss()
# 将获取数据写入文件中(文件路径,文件名,数据)
def write_data(file_path, file_name, data):
# 文件路径
path = file_path + file_name
# 打开创建文件(文件路径,打开方式'a'追加, 编码格式)
f = io.open(path, 'a', encoding='utf-8')
print("正在写入" +file_name + "...")
# 数据写入文件
f.write(data)
print("写入成功")
# 关闭文件
f.close()
#构造爬虫函数
# 构造爬虫函数
def reptilian():
page_source = browser.page_source
soup = BeautifulSoup(page_source, 'html.parser')
try:
# 工作名称 学历 福利 工资
company_info = soup.find('div', class_='info-primary')
job_name = company_info.find('div', class_='name')
study_infor = company_info.find('p')
job_tags = company_info.find('div', class_='job-tags')
describe = soup.find('div', class_='text')
# 工作地址 公司名称
detail_content = soup.find('div', class_='detail-content')
company_name = detail_content.find('div', class_='name')
company_addr = detail_content.find('div', class_='location-address')
# 剔除标签
job_name = job_name.get_text("", strip=True)
study_infor = study_infor.get_text("", strip=True)
job_tags = job_tags.get_text("", strip=True)
describe = describe.get_text("", strip=True)
company_name = company_name.get_text("", strip=True)
company_addr = company_addr.get_text("", strip=True)
except AttributeError:
print("该页面不存在,请跳过本次页面")
else:
f = "-------------------------------------------------------------------------------------"
infors = "工作名称 工资:" + job_name + '\n' + "工作地点 工作经验 学历:" + study_infor + '\n' + "公司福利:" + job_tags + '\n' + "职位描述:" + describe + '\n' + "公司名称:" + company_name + '\n' + "工作地址:" + company_addr + '\n' + f + '\n'
write_data(file_path=file_path, file_name=file_name, data=infors)
#寻找网站
def find_boss():
main_html = BeautifulSoup(browser.page_source, "lxml")
job_list=main_html.find('div',class_="menu-sub")
htmls_two = job_list.find_all("a", href=re.compile('\w.*?-\w.*?')) #寻找职位href
for html_two in htmls_two: #遍历
for i in range(1,11): #寻找下一页
browser.get(base_url+html_two['href']+'?page='+str(i)+'&ka=page-'+str(i))
print("第{}页".format(str(i))) #输出下一页
soup_one = BeautifulSoup(browser.page_source, 'lxml')
link_lists_nexts = soup_one.find_all('a', href=re.compile('job_detail/.*?~.html')) #寻找需要爬取的职位网站
for link_lists_next in link_lists_nexts: #遍历
html_end=base_url+link_lists_next['href']
browser.get(html_end)
reptilian() #执行爬虫函数
time.sleep(1)
#主函数
if __name__=='__main__':
#获取目标网站url 与 创建招聘信息文件
url='https://www.zhipin.com/?ka=header-home-logo'
base_url='https://www.zhipin.com'
file_path='E:\\' #路径
file_name=str(input("请输入要创建的文件名称:"))
#打开浏览器
browser=Chrome()
browser.get(url)
#创建文件
establish_file(file_path=file_path, file_name=file_name)
#关闭浏览器
browser.close()
注意
在设计代码的时候一定要考虑到404网站的存在,及时抛出异常,考虑周到
改进
import io
import os
import re
import time
from bs4 import BeautifulSoup
from selenium.webdriver import Chrome
#寻找网站
def find_boss():
main_html = BeautifulSoup(browser.page_source, "lxml")
job_lists = main_html.find('div', class_="menu-sub")
job_list= job_lists.find_all("a", href=re.compile('\w.*?-\w.*?'))
for html_two in job_list[79:]:
browser.get(base_url+html_two['href'])
soup_one = BeautifulSoup(browser.page_source, 'lxml')
link_lists_nexts = soup_one.find_all('a', href=re.compile('job_detail/.*?~.html')) #寻找需要爬取的职位网站
for link_lists_next in link_lists_nexts: #遍历
html_end=base_url+link_lists_next['href']
print(html_end)
browser.get(html_end)
# reptilian() #执行爬虫函数
time.sleep(1)
try: #下一页
next_page =soup_one.find('div', class_="page")
next_page_end = next_page.find("a", class_='next')
browser.get(base_url + next_page_end['href'])
except:
pass #如果没有则退出
#主函数
if __name__=='__main__':
#获取目标网站url 与 创建招聘信息文件
url='https://www.zhipin.com/?ka=header-home-logo'
base_url='https://www.zhipin.com'
#打开浏览器
browser=Chrome()
browser.get(url)
#运行主函数
find_boss()
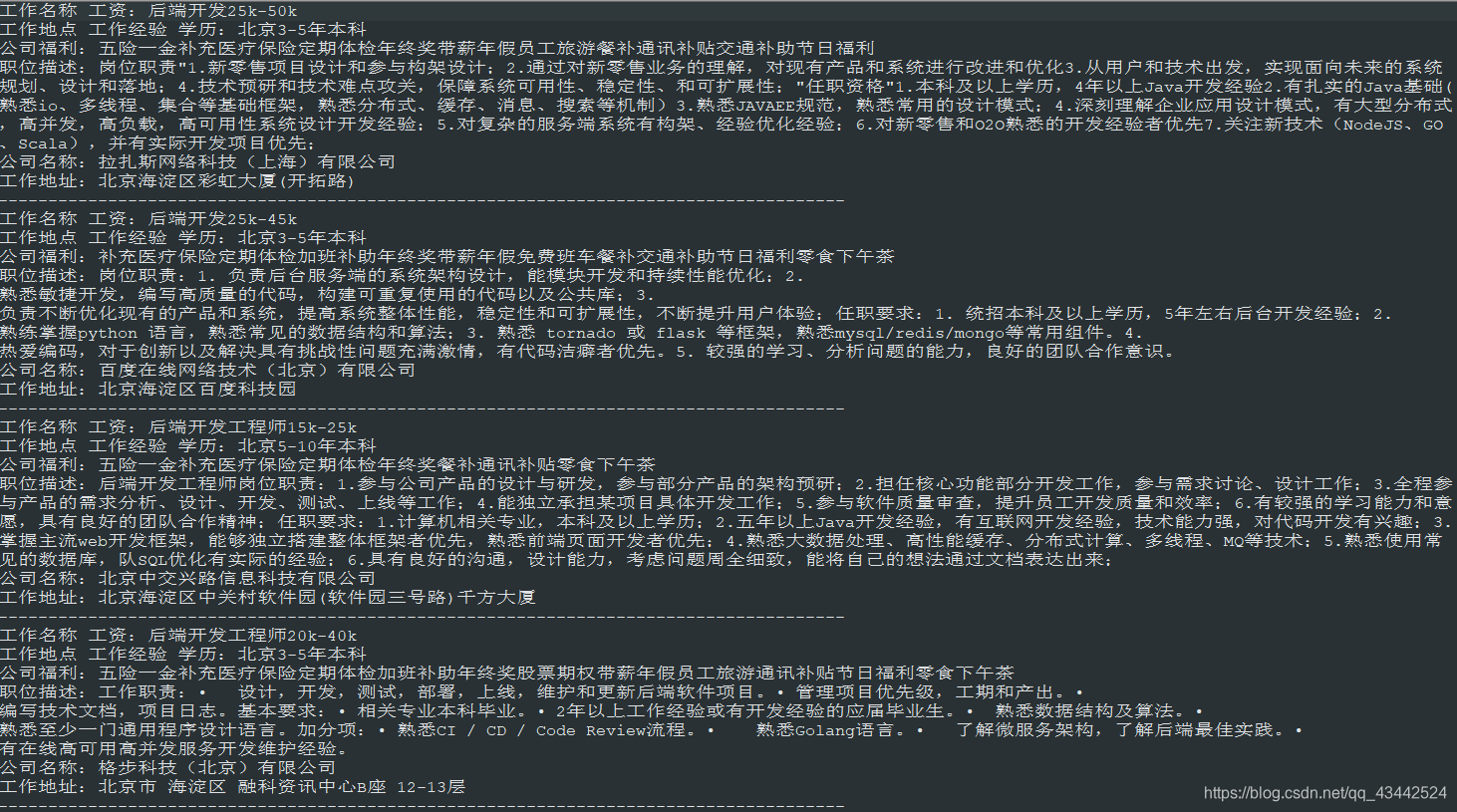
这样,一个简单的python爬虫就实现了
