K-means聚类算法
简介
聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程,聚类就是一种发现这种内在结构的技术,聚类技术经常被称为无监督学习。
K均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。给定一个数据点集合和需要的聚类数目k,k由用户指定,k均值算法根据某个距离函数反复把数据分入k个聚类中。
算法
先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是以下任何一个:
-
没有(或最小数目)对象被重新分配给不同的聚类。
-
没有(或最小数目)聚类中心再发生变化。
-
误差平方和局部最小。
MATLAB函数使用方法
idx = kmeans(X,k)
idx = kmeans(X,k,Name,Value)
[idx,C] = kmeans(___)
[idx,C,sumd] = kmeans(___)
[idx,C,sumd,D] = kmeans(___)
参数说明:
X:数据集,一般为N*p的矩阵,N为数据个数,p为数据维度。
k:分类数
C: K*p的矩阵,存储的是K个聚类质心位置
idx :N*1的向量,存储的是每个点的聚类标号
sumd:1*K的和向量,存储的是类间所有点与该类质心点距离之和
D:N*K的矩阵,存储的是每个点与所在聚类质心的距离
实例
clc;
clear;
%随机获取150个点
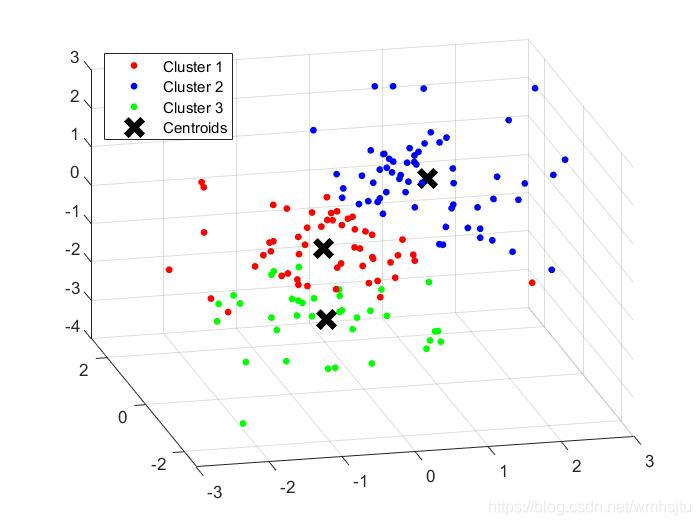
X = [randn(50,3)+ones(50,3);randn(50,3)-ones(50,3);randn(50,3)];
%调用Kmeans函数
%X N*P的数据矩阵
%Idx N*1的向量,存储的是每个点的聚类标号
%Ctrs K*P的矩阵,存储的是K个聚类质心位置
%SumD 1*K的和向量,存储的是类间所有点与该类质心点距离之和
%D N*K的矩阵,存储的是每个点与所有质心的距离;
[Idx,Ctrs,SumD,D] = kmeans(X,3);
%画出聚类为1的点。X(Idx==1,1),为第一类的样本的第一个坐标;X(Idx==1,2)为第二类的样本的第二个坐标
plot3(X(Idx==1,1),X(Idx==1,2),X(Idx==1,3),'r.','MarkerSize',14)
hold on
plot3(X(Idx==2,1),X(Idx==2,2),X(Idx==2,3),'b.','MarkerSize',14)
hold on
plot3(X(Idx==3,1),X(Idx==3,2),X(Idx==3,3),'g.','MarkerSize',14)
%绘出聚类中心点
plot3(Ctrs(:,1),Ctrs(:,2),Ctrs(:,3),'kx','MarkerSize',14,'LineWidth',4)
plot3(Ctrs(:,1),Ctrs(:,2),Ctrs(:,3),'kx','MarkerSize',14,'LineWidth',4)
plot3(Ctrs(:,1),Ctrs(:,2),Ctrs(:,3),'kx','MarkerSize',14,'LineWidth',4)
grid on;
legend('Cluster 1','Cluster 2','Cluster 3','Centroids','Location','NW')