最近在学习吴恩达的机器学习,遇到K-means算法,并做了笔记。
K-means算法原理:
K-means聚类算法是一种将相似的数据样本自动聚集到一起的方法。更具体的,如果给出训练集,其中每个样本x都属于n维的实数向量,然后我们希望将这些数据分组到少数的簇中去。K-means背后的原理是一个迭代的过程,首先随机给出K个初始的聚类中心,将m个样本数据分别分配给离该数据最近的聚类中心。然后根据移动后的数据再次求得聚类中心的位置。
K-means算法过程:
首先随机的初始化K个聚类中心都属于n维的实数向量。
迭代重复以下步骤:
有两个内循环:
1、簇的分配 :将所有的样本数据分配给K个簇中心,将每个点划分给属于自己簇的过程。
c^(i)是一个在1到K之间的数,表示当前样本下x(i)所属的那个簇的索引号或者序号。
2、移动簇中心:计算每个簇里面所有样本的平均值,并赋值给新的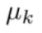
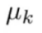 表示第k个聚类中心的位置,此时移动第k个聚类中心就结束了。
表示第k个聚类中心的位置,此时移动第k个聚类中心就结束了。
这两个一直是迭代的过程。
关于K-means算法的优化目标函数(最小化的代价函数):
用于帮助K-means算法找到更好的簇以及选择簇中心的个数,避免陷入局部最优解。
代价函数为:

关于该算法的细节,根据这个函数回看K-means算法过程,由数学公式可以证明,第一步实际就是在关于变量c(i)最小化J,不改变聚类中心的位置;第二步就是根据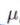 最小化J,移动聚类中心。
最小化J,移动聚类中心。
如何初始化K-means聚类算法,如何使算法避免局部最优:

随机的选择K个聚类中心,但K要小于m(样本数量)。
为了避免陷入局部最优,可以尝试多次随机初始化,做法如下:


选出使代价函数最小的那组聚类中心。
关于如何选取聚类数量:
没有特别好的方法,最常用的方法是通过观察可视化的图或者观察聚类算法的输出来决定。
有个方法可以用来辅助判断个数:肘部规则

同样是根据代价函数J来判断K的值。