在数据压缩和数据分类中有一个很重要的算法叫聚类算法。
一个聚类表示在某一范数下距离最小的点的集合。
可以考虑取出每一类的均值作为这一类的代表。
取二范数来衡量两个向量的距离。

黄色字体:分类指标集;
蓝色字体:每一类的中心向量;
绿色字体:最终结果的衡量标准,要使它尽可能地小;
具体算法展示:

- 初始化分类集,计算初始分类集的中心向量,计算初始状态下的Q值,将迭代次数t值为1;
- 为每一个样本向量ai找和它最近的中心向量,如果找到的是中心向量mp,那么就将这个样本向量ai分入第p类中去;
- 计算新的Q值;
- 判断新Q值和旧Q值的差距是否满足误差限度tol,如果不满足,就重复1~4步骤;否则,就结束运算。
注:k-mans算法可以保证较快的收敛,不可保证结果是全局最优的。
function cla=kmeans(A,k)
%K-means聚类算法
%A为样本(m*n),将其列向量分为k类
%M为中心向量矩阵,k*m型
%初始化中心向量矩阵
M=A(:,1:k);
[m n]=size(A);
%初始化分类集
for i=1:k-1
cla{i}=[i];
M(:,i)=A(:,i);
end
cla{k}=[k:n];
M(:,k)=mean(A(:,k:n),2);
Q0=0;
for i=k:n
Q0=Q0+norm(A(:,i)-M(:,k),2)^2;
end
while true
Q=0;
for i=1:n
[min_value,min_cla]=min(sum((M-A(:,i)).^2));
%记录下ai属于第min_cla类,且距离值为min_value,用于后续计算Q
cla{min_cla}=[cla{min_cla},i] %把当前的样本ai记录入对应类
Q=Q+min_value;
end
if abs(Q-Q0)<0.01
return;
else
Q0=Q;
end
%计算新一轮的中心向量
for i=1:k
M(:,i)=zeros(m,1);
for v=cla{i}
M(:,i)=M(:,i)+A(:,v);
end
M(:,i)=M(:,i)/length(cla{i});
end
%置空k个分类指标集
for j=1:k
cla{j}=[];
end
end
考虑到样本矩阵会很大,所以没有使用定义和调用子函数。感觉那样也许会很慢。
测试用的矩阵建议是如下图这样:
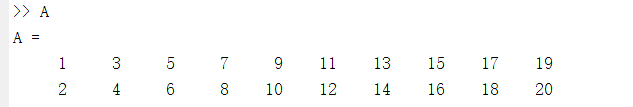
注:每一列表示一个点,这样很明显能够看出:如果是分成3类的话,那么应该是前3列,中间3列,最后4列为最优分法,当然也可能是中间4列+左边+右边=三类,总之应该是连续的分成一类。
看一下调用上述函数的输出结果:

说明:分类还算可以。
再打乱顺序,测试一遍:

这里矩阵AA只是对矩阵A的列调换了一下顺序。
分类结果:

对矩阵A的分类结果是 左边+中间3列+右边
对矩阵AA的分类结果是 左边+中间4列+右边;说明分类还算成功。
上面说的方位是针对下图的点集: