最近两天再看mask rcnn的文章,这个文章其实就利用之前Faster-RCNN和FPN的工作,再加了一个mask分支就可以完成实例分割的任务,当然这个文章中我觉得主要有两个创新点:1、提出了RoI Align;2、提出了mask分支,区别于FCN网络。看文章的时候其实没怎么看明白RoI Align的工作机制到底是啥,看了很多博客终于搞清楚了,故做已记录。同时这也是Mask的一个contribution 。
这两个方法都是讲RPN网络筛选后的proposals映射到feature map上,RoI Pooling经过两次量化映射会feature map会用误差,因此RoI Align再此基础上进行了改进,没有了两次量化的误差,映射到像像素的值就更加的准确了。
1、RoI pooling
- 输入一张图像Image
- 经过卷积神经网络(VGG16/Res net)得到一个feature map
- 然后通过RPN再原图上生成很多proposals经过一系列的筛选得到最终的regions of interest
- 将regions of interest,也就是在原图产生的目标检测框映射到feature map上
- 将regions of interest先按照比例缩放,比如VGG16经过卷积之后得到的feature map是原图的1/16,因此就缩放至1/16
- 然后在映射会feature map上,并且划分成n*n的大小(faster rcnn中划分成7*7)
- 然后对每一个section进行max pooling
- 最终会得到所有regions of interset在feature上的映射,并且得到的大小都是一样的
- 到此RoI pooling就结束了
通过整个RoI pooling我们可以发现,只要是经过ROI pooling最终得到的feature大小都是相同的,都是n*n;同时在这个过程中也会存在一些问题,这个里面有两次量化操作:①将region of interest映射回feature map除以stride会有小数出现,那就进行取整操作;②将取证后的feature划分成n*n的时候,可能也会有小数存在,还是进行取整操作,那么这两个操作最终都会让真正的位置和feature map上的位置会产生偏差,如果对于大的目标那没啥影响,但是如果对于小的目标检测就会非常不准确。因此在Mask RCNN中提出了RoI Align的操作,不用经过两次量化也就不会产生有多误差。接下来用图示具体展示每一步:
①经过卷积神经网络得到一个8*8的feature map

②将region of interest投影到feature map上得到左上角的坐标(0,3)和右下角的坐标(7,8)

③将该区域划分成2*2大小7/2=3.5,向上取整3;5/2,向上取整2;

④最终对每个section进行max pooling,得到一个2*2的feature

2、RoI Align
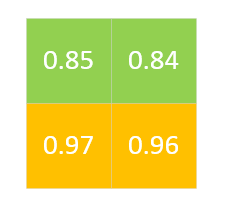
由于RoI pooling经过两次量化产生的误差对小目标影响是非常大的,因此在实例分割的时候尤为需要注意的一个点,因此这篇paper就提出了RoI Align这个方法,我们可以看看论文中的数据对比,通过观察我们发现提示还是比较大的,因此对于实例分割的最终结果显然也是提升非常大的。RoI Align前期的步骤和RoI pooling基本上是一模一样的,就从映射会开始不一样了。

①经过卷积神经网路得到8*8的feature map
②将region of proposal映射会原图不进行向上取整操作

③将映射得到的feature map划分成2*2的section

④然后在每一个section选取4个采样点,然后再通过双线性插值法对其中每个section中的每个点进行双线性插值,4个点就会得到4个值,然后在进行max pooling,得到每个section的值


⑤最终得到2*2的feature map

通过非线性插值法得到的2*2中的每个值都是计算出来的。
3、双线性插值法
- 先横插,再纵插
- 先纵插,再横插
- 不管先横还是先竖,最终插值的结果都是不变的


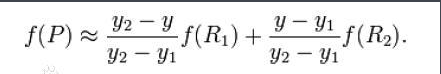
总结:RoI Align是Mask RCNN的一个创新点,也是一个关键点。提升了最终目标检测和实例分割的准确率,解决了RoI Pooling两次量化所带来的误差。