文章目录
一、前言
ROI Align和ROI Pooling都是目标检测领域中常用的操作,用于在特征图上提取目标区域的特征。它们的区别在于对于目标区域的精细度不同。
- ROI Pooling是在目标区域上进行固定步长的池化操作,将目标区域划分成子区域,并在每个子区域内进行最大池化,得到固定大小的特征图。这种方法简单易懂,但会丢失一些目标区域的细节信息,影响检测性能。
- 而ROI Align则是在目标区域上进行双线性插值,得到更加精细的特征图。具体地,ROI Align首先将目标区域分成若干个小格子,然后对每个小格子内的像素进行双线性插值,最后将得到的像素值按照权重分配到对应的输出像素上。这种方法相较于ROI Pooling更加精细,可以更好地保留目标区域的细节信息,因此在一些对检测精度要求较高的场景中有更好的表现。但是,由于需要进行双线性插值,ROI Align的计算量相较于ROI Pooling更大,速度也相对较慢。
二、详细理解
2.1 ROI Pooling的局限性
ROI Pooling是针对ROI的Pooling操作,整个过程中涉及的两次量化分别发生在对ROI坐标和对ROI划分为等大子区域上的量化。ROI可以有不同的获得方法,如在Faster R-CNN中是由RPN回归得到,故ROI的坐标一般为浮点数,此处需要量化为整数;ROI均分为等大的子区域时,若不能整除,则需要量化。 665 × 665 665\times 665 665×665的矩形框经主干网络后的缩放步长为32,此框的大小也变为665 / 32 = 20.78,此时ROI Pooling将其量化为20;池化层的输出大小为 7 × 7 7\times 7 7×7,等分后的子区域大小为20 / 7 = 2.86,此时将等分后的子区域大小量化为2。由缩放步长可知,该特征图上1个像素的偏差在原图上就是32个像素的差别,这对小物体的检测效果影响很大。
2.2 ROI Align的思想和实现方法
ROI Align从ROI Pooling局限性的源头上进行了改进,也就是取消了量化操作,对于量化中产生的坐标为浮点数的像素,利用双线性插值计算其像素值。值得注意的是,ROI Align并不需要对两步量化中产生的浮点数坐标的像素值都进行计算,而是设计了一套优雅的流程。

论文中ROI Align的实现方法如上图所示,。其中,虚线框表示feature map,实线框表示一个ROI,Pooling输出大小为 2 × 2 2\times 2 2×2,每个子区域中有四个采样点。ROI Align基于双线性插值的方法,利用feature map上距离采样点最近的四个像素得到其像素值。整个过程中没有对ROI、均分ROI产生的子区域(bins)和采样点进行量化。每个bin中采样点的数目和位置存在一定的规则,即若采样点数为1,则该点位于bin的中心位置;若采样点数为4,则采样点的位置为均分该bin为4个小矩形后各自的中心点。通常这些采样点的坐标为浮点数,所以需要用到插值的方法获得其像素值。
三、详解 Mask-RCNN 中的RoI Align作用
3.1 RoI Align的产生背景
首先设想一个场景,假设从一个图像中锚定了一个人的边界框:

这个时候,要提取边界框中的人的特征,显然应该用 CNN 网络来做这个工作。CNN 处理之后会形成一个特征图。按照一般的处理方式,会使用 RoI Pooling 来缩小特征图的尺寸。但是在 Mask-RCNN 中提出了一个 RoIAlign 的方式,使得得到的小特征图可以更加的精确和信息完整。
3.2 RoI Pooling
举例来说,如果我们现在得到了一个特征图,特征图尺寸是 5 × 7,要求将此区域缩小为 2 × 2。此时,因为 5 / 2 = 2.5,是个非整数,所以此时系统会对其进行取整的分割,即将 “ 5 ”分割成 “ 3 + 2 ”,将 “ 7 ” 分割成 “ 3 + 4 ”,然后取每个区域的最大值作为本区域的值,整个过程如下所示:
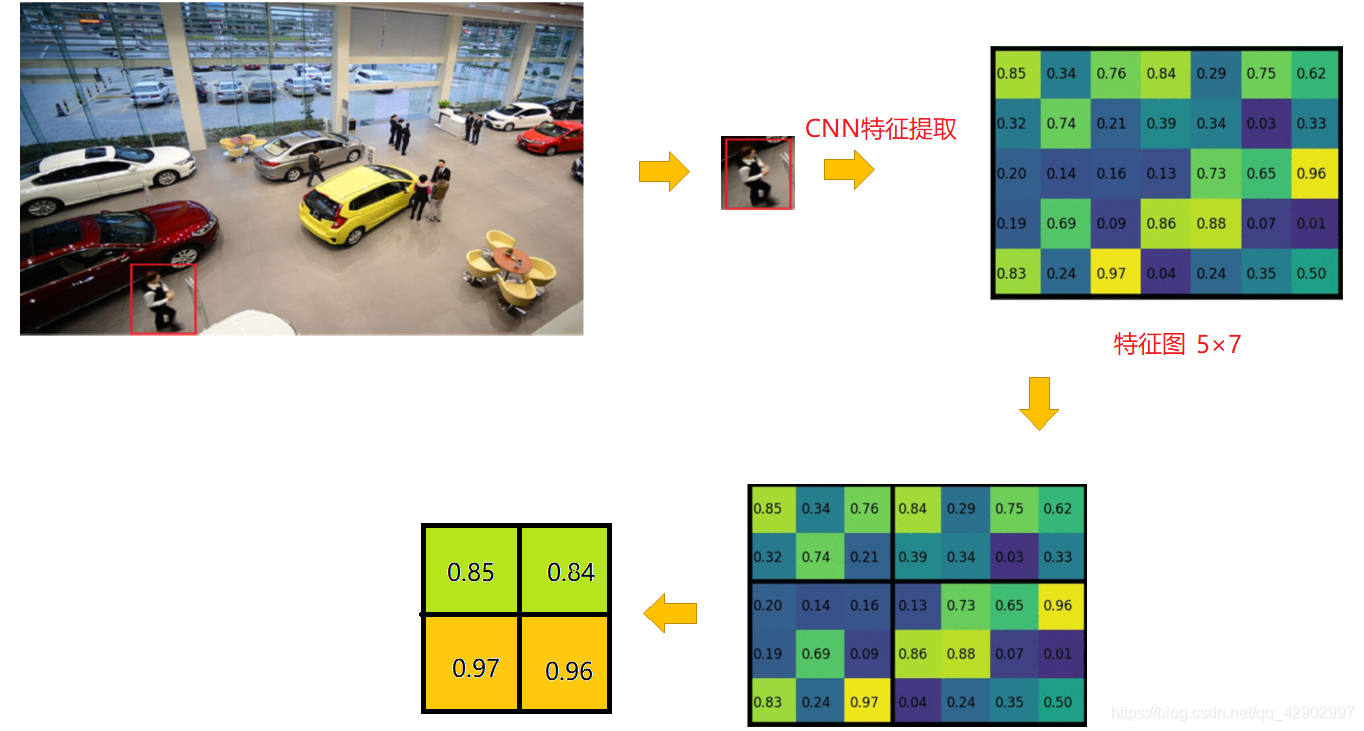
3.3 RoI Align
可以知道,使用 RoI Pooling 存在一个很大的问题:
很粗糙地选用了一个值来代替一个区域的值,而且每个区域的尺寸还有很大的差距。
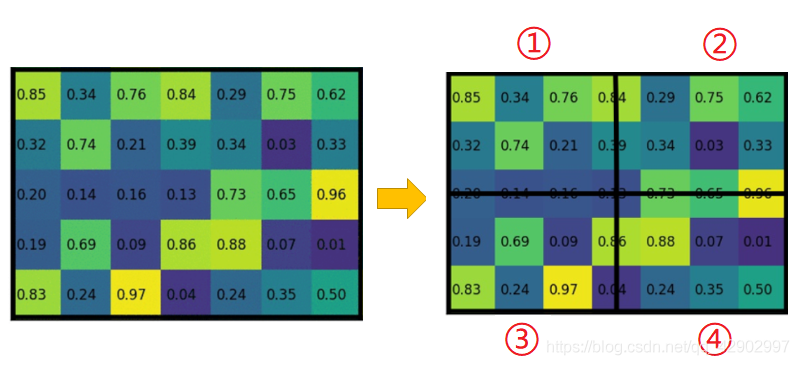
ROI Align的过程如下:
- 因为最终要将这个 5 × 7 5\times 7 5×7的特征图处理成 2 × 2 2\times 2 2×2的特征图,所以先将要进行ROI Align的过程转换成 2 × 2 2\times 2 2×2个相同规模的范围,这个过程中不做任何量化处理。

- 将这 4 个模块(①,②,③,④)内部同样进行这样的处理,再细分成 4 个规模相同的区域(图中虚线表示)。
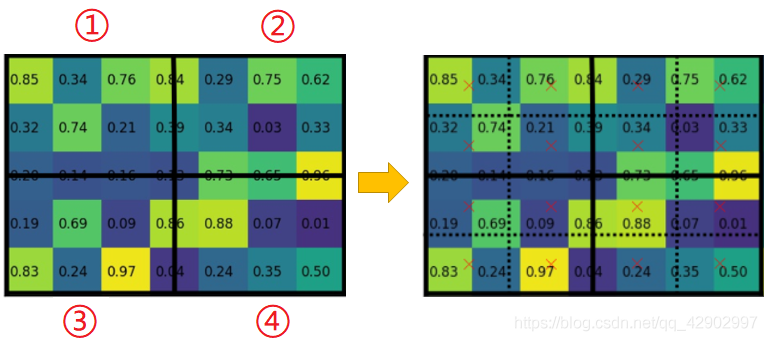
3. 然后对于每一个最小的区域(包含不止一个像素点)确定其中心点(图中的红色 × )然后使用双线性插值法得到这个 × 号所在位置的值作为 最小格子区域 的值。
4. 对于每一个 小区域(①,②,③,④)都会有 4 个这样的值,把这 4 个值取他们的最大值作为每个 小区域(①,②,③,④) 的值。这样最终就可以得到 4 个小区域的 4 个值,作为最终的特征图输出结果。
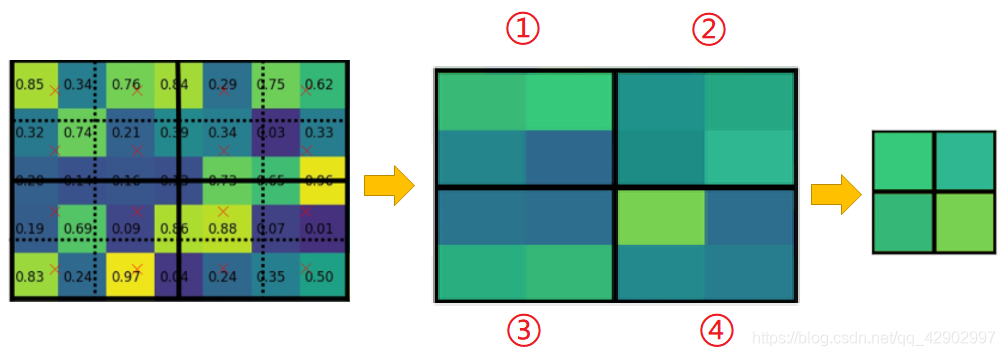
提出的这种方式可以减缓过程中丢失原特征图的信息,中间过程全程不量化来保证最大的信息完整性。