- 卷积输出计算以及卷积核参数计算
计算量 = ,,即输入通道数、输出通道数、卷积核长、宽、输出特征图的长、宽的乘积;
参数数量 =
- 1 x 1 卷积的作用 参考:1 x 1 卷积的作用
当1*1卷积出现时,在大多数情况下它作用是升/降特征的维度,这里的维度指的是通道数(厚度),而不改变图片的宽和高。
e.g. W*H*6的特征,现在需要用1*1的卷积核将其降维成W*H*5,即6个通道变成5个通道,通过一次卷积操作,W*H*6将变为W*H*1,这样的话,使用5个1*1的卷积核,显然可以卷积出5个W*H*1,再做通道的串接操作,就实现了W*H*5。
在这里先计算一下参数数量,一遍后面说明,5个卷积核,每个卷积核的尺寸是1*1*6,也就是一种有30个参数。
- BN 的原理、存在的问题及解决、流程、计算、好处、inference过程描述
- 原理:
- Internal Covariate Shift:在训练过程中,隐层的输入分布总是在变化;
- 图像白化:对输入数据分布变换到0均值,单位方差的正态分布,网络收敛变快;
- BN的基本原理就是对于每个隐层神经元,把逐渐向激活函数极限饱和区靠近的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得输入值落入激活函数梯度较大较为敏感的区域,以此避免梯度消失问题;
- 问题及解决:
- Q: 如果都通过BN,就跟把非线性函数替换成线性函数效果相同,网络的表达能力会下降;
- A: 为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),这两个参数是通过训练学习到的 —— 既可以应用非线性的较强表达能力,又避免太靠非线性区两头使得网络收敛速度太慢;
- 流程:
- 原理:

-
- 好处:
- 避免了梯度消失问题,收敛快,训练所需的时间变短;
- 可以选择比较大的初始学习率,进一步提升训练速度;
- 可以减少dropout、L2正则项的使用(BN具有提高网络泛化能力的特性);
- 不需要使用局部响应归一化(Alexnet中使用到)
- inference过程:
- 计算公式 :
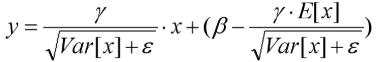 ,两个参数均为定值,无需重复计算;
,两个参数均为定值,无需重复计算; - 保存每个mini-batch的均值和方差,依此可以求出全局的均值和方差;
- inference的输入只有一个实例,所以用全局的均值和方差代替训练时mini-batch中的均值和方差;
- 计算公式 :
- 好处:
-
- 输入一个mini-Batch;
- 计算mini-batch的均值;
- 计算mini-batch的方差;
- 对每一个输入进行标准化(减去均值除以标准差,
用于防止除数为0);
- 小幅度缩放和移动(scale / shift);
- 梯度消失和梯度爆炸的解释、成因、判断、解决办法
- 原理:BP过程中,
,根据链式求导法则,梯度可以表示为激活函数导数和权重连乘(
)的表达式,随着网络层数加深,梯度的连乘表达式的项数增加,如果这些项都小于1,就会出现梯度消失;反之如果这些项(权重
较大时)都大于1就会出现指数爆炸从而导致梯度爆炸;
- 原因:
- 梯度消失一般出现在深层网络或采用了不合适的损失函数(
太小),比如sigmoid;
- 梯度爆炸一般出现在深层网络和权值初始化值太大(
- 梯度消失一般出现在深层网络或采用了不合适的损失函数(
- 判断:
-
模型无法从训练数据中获得更新(如低损失);
-
模型不稳定,导致更新过程中的损失出现显著变化;
-
训练过程中,模型损失变成 NaN;
-
-
解决方法:
- 梯度消失:
-
用ReLU、Leaky-ReLU(ReLU将负值设为0,造成节点死亡) 等激活函数替代 sigmoid;
-
Batch Normalization(将每一个隐含层的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,落在激活函数梯度比较合适的部分);
-
LSTM 结构改善 RNN中梯度消失;
-
残差结构:短路机制可以无损传播梯度,另一部分不是直接传过来的(通过多层weights和ReLU)
-
-
梯度爆炸:
-
用ReLU、Leaky-ReLU(ReLU将负值设为0,造成节点死亡) 等激活函数替代其他激活函数;
-
梯度截断(Gradient Clipping):设置一个梯度剪切阈值,更新梯度时,如果梯度超过这个阈值,就将其强制限制在这个范围之内;
-
权重正则化(weithts regularization):
正则(权重绝对值)和
正则(权重平方),检查网络权重的大小,通过正则化项惩罚过大的权值;
-
- 梯度消失:
- 原理:BP过程中,
- ResNet 如何解决梯度消失,写出公式

ResNet中有很多跨层连接结构 ,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失,所以残差学习会相对容易。
- RCNN、Fast-RCNN、Faster-RCNN、Mask-RCNN系列的区别
- ROI Pooling 和 ROI Align 的区别
- 参见:Mask-RCNN总结
- ROI Pooling:从输入图上的RoI映射到特征图上的RoI 特征图,直接通过四舍五入取整得到的结果;将RoI feature 转化为固定大小的bin时,又采用了取整操作(maxpooling);
- 存在的问题:两次取整量化造成的feature map 和 RoI 区域不匹配(mis-alignment)问题;
- ROI Align:ROI映射到feature map后,将候选区域分割为k*k个单元,每个单元固定四个坐标的位置(grid points),用双线性插值的方法计算这四个点的位置,然后做max pooling操作;
- 主要改进:
- 不再做取整操作,使用双线性插值(在两个方向分别进行一次线性插值)来更精确找到每个块对应的特征;
- 主要改进: