Hadoop定义
- 以Hadoop分布式文件系统和MapReduce为核心的hadoop为用户提供了系统底层细节透明的分布式基础结构
- 历史:源头Apahce Nutch
Hadoop的功能与作用
- 他采用分布式存储方式来提高读写速度和扩大存储容量,利用MapReduce整合分布式文件系统上的数据,保证高速分析处理数据,同时采用存储荣誉数据来保证数据的安全性
Hadoop的优势
- 高可靠性:按位存储,处理数据的能力
- 高扩展性:计算机集簇间分配数据完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性:在节点之间动态移动数据,保证各个节点的动态平衡,处理速度很快
- 高容错性:自动保存数据的多分副本,并且能够自动讲失败的任务重新分配
Hadoop的项目还有结构
- 虽然其核心内容是MapReduce和 Hadoop分布式文件系统,但与Hadoop相关的Common、Avro、Chukwa、Hive、HBase等项目也是不可或缺的。
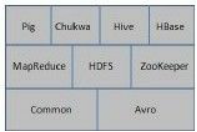
Common
1)Common是为Hadoop其他子项目提供支持的常用工具,它主要包括FileSy stem、RPC和串行化库。它们为在廉价硬件上搭建云计算环境提供基本的服务,并且会为运行在该平台上的软件开发提供所需的API。
Avro
- 用于数据序列化的系统,具有丰富的数据结构类型,快速可压缩的二进制数据格式,存储持久化的数据文件及,2)远程调用RPC的功能和简单的动态语言集成功能。其中代码生成器既不需要读写文件数据,也不需要使用或实现RPC协议,它只是一个可选的对静态类型语言的实现。
- Avro系统依赖于模式(Schema),数据的读和写是在模式之下完成的。这样可以减少写入数据的开销,提高序列化的速度并缩减其大小;同时,也可以方便动态脚本语言的使用,
因为数据连同其模式都是自描述的。
在RPC中,Avro系统的客户端和服务端通过握手协议进行模式的交换,因此当客户端和服务端拥有彼此全部的模式时,不同模式下相同命名字段、丢失字段和附加字段等信息的一致性问题就得到了很好的解决。
MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。MapReduce在执行时先指定一个Map(映射)函数,把输入键值对映射成一组新的键值对,经过一定处理后交给Reduce, Reduce对相同key 下的所有value 进行处理后再输出键值对作为最终的结果。
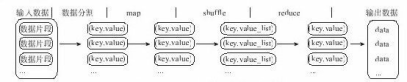
- MapReduce程序将输入划分到不同的Map上、再将Map的结果合并到Reduce、然后进行处理的输出过程。
HDFS
分布式文件系统,,适合那些有着超大数据集的应用程序.HDFS放宽了对可移植操作系统接口(POSIX, Portable Operating Sy stem Interface)的要求,这样可以实现以流的形式访问文件系统中的数据。HDFS原本是开源的Apache项目**Nutch的基础结构,**最后
它却成为了Hadoop基础架构之一。
设计目标
- 检测和快速恢复硬件故障
核心目标 - 流式的数据访问->流式处理而不是交互式处理
HDFS被设计成适合进行批量处理,而不是用户交互式处理。所以它重视数据吞吐量,而不是数据访问的反应速度。 - 简化一致性模型。
一次写入,多次读取,。一个文件一旦经过创建、写入、关闭就不需要修改了 - 通信协议。
一个客户端和明确配置了端口的名字节点(NameNode)建立连接之后,它和名字节点的协议便是客户端协议(Client Protocal)。数据节点(DataNode)和名字节点之间则用数据节点协议(DataNode Protocal)。
Chukwa
- Chukwa是开源的数据收集系统,用于监控和分析大型分布式系统的数据。通过HDFS来存储数据,并依赖MapReduce任务处理数据,显示、监视和分析数据结
HIVE
- Facebook设计的,是一个建立在Hadoop基础之上的数据仓库,
- 数据整理、特殊查询和分析存储
- 结构化数据的机制,Hive QL
HBASE
- 个分布式的、面向列的开源数据库,提供了类似于Bigtable的能力
- 不同于一般的关系数据库,
- 1.HBase是一个适合于非结构化数据存储的数据库
- HBase是基于列而不是基于行的模式
- HBase和Bigtable 使用相同的数据模型。用户将数据存储在一个表里,一个数据行拥有一个可选择的键和任意数量的列。由于HBase表是疏松的,用户可以为行定义各种不同的列。HBase主要用于需要随机访问、实时读写的大数据(Big Data)
Pig
大型数据集进行分析、评估的平台,Pig最突出的优势是它的结构能够经受住高度并行化的检验,Pig的语言层由一种叫做Pig Latin的正文型语言组成
ZooKeeper:
- 分布式应用所设计的开源协调服务,用户提供同步、配置管理、分组和命名
Hadoop体系结构

-
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器, 管理文件系统的命名空间和客户端对文件的访问操作;
-
集群中的DataNode管理存储的数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。
-
NameNode执行**文件系统的命名空间操作,**比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。
-
DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。
-
NameNode是所有HDFS元数据的管理者,用户需要保存的数据不会经过NameNode,而是直接流向存储数据的DataNode。
MapReduce框架
- MapReduce框架是由一个单独运行在主节点的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。**主节点负责调度构成一个作业的所有任务,**这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前失败的任务;**从节点仅负责由主节点指派的任务。**当一个Job被提交时,JobTracker接收到提交作业和其配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
- HDFS在集群上实现了分布式文件系统,对文件操作和存储,MapReduce在集群上实现了分布式计算和任务处理任务的分发、跟踪、执行等。
Hadoop与分布式开发
- MapReduce编程模型的原理是:利用一个输入的key /value对集合来产生一个输出的key /value对集合。MapReduce库的用户用两个函数来表达这个计算:Map和Reduce。‘
- 用户自定义的Map函数接收一个输入的key /value对,然后产生一个中间key /value对的集合。MapReduce把所有具有相同key 值的value集合在一起,然后传递给Reduce函数。用户自定义的Reduce函数接收key 和相关的value集合。Reduce函数合并这些value值,形成一个较小的value集合。一般来说,每次调用Reduce函数只产生0或1个输出的value值。通常我们通过 一个迭代器把中间value值提供给Reduce函数,这样就可以处理无法全部放入内存中的大量的value值集合了。

大数据集分解为成百上千个小数据集,每个(或若干个)数据集分别由集群中的一个节点(一般就是一台普通的计算机)进行处理并生成中间结果,然后这些中间结果又由大量的节点合并,形成最终结果,一个map任务和每一个reduce任务都是可以同时运行在一个单独的计算节点上,所以计算效率很高
并行计算的原理
数据分布存储
- 文件在HDFS底层被切割成了Block,这些Block分散地存储在不同的DataNode上,每个Block还可以复制数份数据存储在不同的DataNode上,达到容错容灾的目的。NameNode则是整个HDFS的核心,它通过维护一些数据结构来记录每一个文件被切割成了多少个Block、这些Block可以从哪些DataNode中获得,以及各个DataNode的状态等重要信息。
分布式并行计算
- 主控的JobTracker,用于调度和管理其他的TaskTracker。JobTracker可以运行于集群中的任意一台计算机上;TaskTracker则负责执行任务,它必须运行于DataNode上,DataNode既是数据存储节点,也是计算节点
- JobTracker将Map 任务和Reduce任务分发给空闲的TaskTracker,TaskTracker出了故障,JobTracker会将其负责的任务转交给另一个空闲的TaskTracker重新运行。
本地计算
- 数据存储在哪一台计算机上,就由哪台计算机进行这部分数据的计算,计算节点可以很方便地扩充,因此它所能够提供的计算能力近乎无限。但是数据需要在不同的计算机之间流动,网络带宽变成了瓶颈
1.任务粒度
数据分割
数据合并combine
Cimbine是map任务地一部分,执行完map函数后紧接着执行的,Combine能够减少中间结果中<key, value>对的数目,从而降低网络流量。
Map任务的中间结果在执行完Combine和Partition之后,以文件形式存储于本地磁盘上。中间结果文件的位置会通知主控JobTracker, JobTracker再通知Reduce任务到哪一个
任务管道
R个reduce任务,就会有r个最终结果,很多情况下这r个结果并不需要合并成一个最终结果,可以作为另一个计算任务地输入,开始另一个并行计算任务
MapReduce
一个map/reduce作业会把输入地数据集切分成为若干个独立地数据块,由mao任务task以完全并行地方式处理他们,框架会先对map地输出进行排序,然后把记过输入到reduce任务当中,通常作业地输入和输出都会被存储在文件系统当中,整个框架负责任务地调度和监控,以及重新执行已经失败地任务
,Map/Reduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点在一起。这种配置允许框架在那些已经存好地数据地节点上高效地调度任务,
Map/Reduce框架由一个单独地Master Jbo Tracker和集群节点行地slave TaskTracker共同组成的,Master负责调度构成一个作业地所有地任务,这些任务分布在不同地slavemaster监控他们地执行地情况,并重新执行他们已经失败地任务,salce仅仅执行由master指派地任务
JobTracker会负责分发这些软件和配置信息给slave及调度任务,并监控它们的执行,同时提供状态和诊断信息给JobClient。
HDFS地数据管理
对于整个集群有单一的命名空间
具有数据地一致性,都适合一次写入多次读取地模型,客户端在文件没有被成功创建之前是无法看到文件存在的,
文件会被分割成很多个文件快,每个文件块被分配到数据节点上,而且会根据配置由赋值文件块来保证数据安全性
NameNode可以看作是分布式文件系统地管理者,主要负责管理文件系统地命名空间,集群配置信息和存储块地赋值
NameNode会将文件系统地metadate存储在内存当中,这些信息主要包括文件信息,每一个文件对应地文件块信息和每一个文件快在datanode中的信息,Datanode是文件存储地基本单元,他将文件块block存储在本地文件系统,保存了所有地blokc地metadata同时周期性将所有地存在地block信息发送给namenodeclient就是需要获取分布式文件系统地应用程序