1、实现将本地文件合并,并上传至HDFS
本地文件在D:/hadooptest下
merge1.txt
----------------------
hadooptest
merge2.txt
-----------------------
hadoop
map
reduceHadoop集群namenode:hdfs://192.168.31.225:9000
public class PutMerge {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.31.225:9000");
FileSystem hdfs = FileSystem.get(conf);
FileSystem local = FileSystem.getLocal(conf);
Path inputDir = new Path("D:/hadooptest");
Path hdfsFile = new Path("hdfs://192.168.31.225:9000/user/root/example.txt");
try{
FileStatus[] inputFiles = local.listStatus(inputDir);
FSDataOutputStream out = hdfs.create(hdfsFile);
for(int i= 0 ; i < inputFiles.length; i++){
System.out.println(inputFiles[i].getPath().getName());
FSDataInputStream in = local.open(inputFiles[i].getPath());
byte buffer[] = new byte[256];
int bytesRead = 0;
while((bytesRead = in.read(buffer))>0){
out.write(buffer,0,bytesRead);
}
in.close();
}
out.close();
}catch(Exception ex){
ex.printStackTrace();
}
System.out.println("end---------->");
}
}
2、统计学生的科目成绩及总分
chinese.txt
---------------------
nese|lily|80
chinese|zhangsan|90
chinese|lisi|70
chinese|lucy|85
math.txt
----------------------
math|lily|89
math|zhangsan|97
math|lisi|99
math|lucy|85实现代码:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class StatisticDemo extends Configured implements Tool{
public static class MapClass extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text>{
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
//chinese|zhangsan|10 这样的数据 使用value.toString().split("|")是得不到
//正确的结果的,可以使用value.toString.split("\\|")或者下面这种方式来拆分
String fields[] = value.toString().split("[|]");
if(fields.length>=3){
String studentName = fields[1];
output.collect(new Text(studentName), value);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, Text, Text, Text>{
@Override
public void reduce(Text key, Iterator<Text> values, OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
String staticStr = "";
long sum = 0;
while(values.hasNext()){
Text v = values.next();
String fields[] = v.toString().split("[|]");
String subject = fields[0];
String score = fields[2];
staticStr += subject+":"+score;
sum+=Long.parseLong(score);
}
output.collect(key, new Text(staticStr+" 总分:"+sum));
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf,StatisticDemo.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("StatisticDemo");
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
System.exit(ToolRunner.run(new StatisticDemo(), args));
}
}结果:

3、使用Combiner处理
要处理的数据
data.txt
----------------------
ch,12
jp,13
us,123
en,456
as,12
ds,45
cv,123
ch,13
jp,21
代码:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class CombineDemo extends Configured implements Tool{
public static class MapClass extends MapReduceBase implements Mapper<LongWritable,Text,Text,Text>{
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, Text> output, Reporter reporter) throws IOException {
String fields[] = value.toString().split(",");
if(fields.length>=2){
String country = fields[0];
String numClaims = fields[1];
if(numClaims.length()>0 && !numClaims.startsWith("\"")){
output.collect(new Text(country), new Text(numClaims+",1"));
}
}
}
}
public static class Combine extends MapReduceBase implements Reducer<Text, Text, Text, Text>{
@Override
public void reduce(Text key, Iterator<Text> values, OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
double sum = 0;
int count = 0;
while(values.hasNext()){
String fields[] = values.next().toString().split(",");
sum += Double.parseDouble(fields[0]);
count += Integer.parseInt(fields[1]);
}
output.collect(key, new Text(sum+","+count));
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, Text, Text, DoubleWritable>{
@Override
public void reduce(Text key, Iterator<Text> values, OutputCollector<Text, DoubleWritable> output, Reporter reporter)
throws IOException {
double sum = 0;
int count = 0;
while(values.hasNext()){
String fields[] = values.next().toString().split(",");
sum += Double.parseDouble(fields[0]);
count+=Integer.parseInt(fields[1]);
}
output.collect(key, new DoubleWritable(sum/count));
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf,CombineDemo.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("CombineDemo");
job.setMapperClass(MapClass.class);
job.setCombinerClass(Combine.class); //设置Combiner
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) {
try{
int res = ToolRunner.run(new Configuration(),new CombineDemo(),args);
System.exit(res);
}catch(Exception ex){
ex.printStackTrace();
}
}
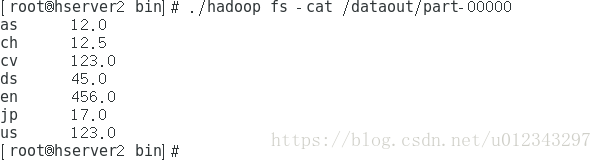
}处理结果: