Hdfs:
一、HDFS运行机制
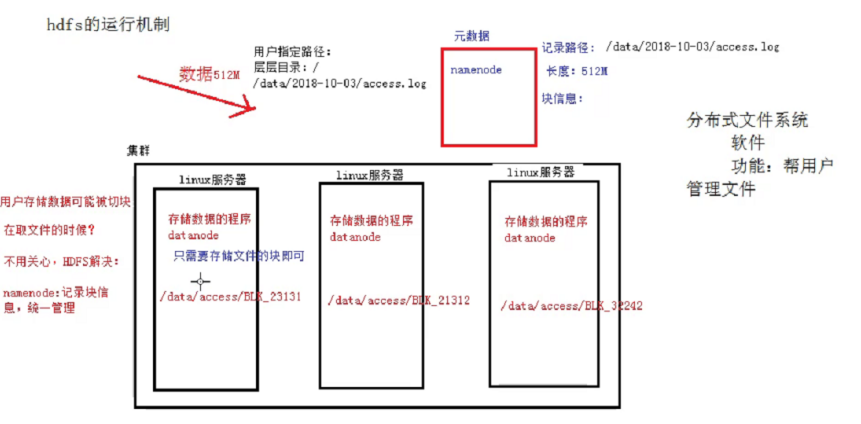
概述:用户的文件会被切块后存储在多台datanode节点中,并且每个文件在整个集群中存放多个副本,副本的数量可以通过修改配置自己设定。
HDFS:Hadoop Distributed file system,分布式文件系统。
HDFS的机制:
HDFS集群中,有两种节点,分别为Namenode,Datanode;
Namenode它的作用时记录元数据信息,记录块信息和对节点进行统一管理。比如用户要存储一个很大的文件,HDFS系统会对这个文件进行切分,然后存储在多台Namenode节点当中,那么每个切的大小,存储的路径信息,文件的副本数等元数据信息会存储在元数据当中,由Namenode进行管理和记录。
Datanode节点的作用是存储数据,Namenode将数据切块后的分配给多个Datanode节点,Datanode对数据块进行存储,Datanode它默认的块大小在hadoop1.x的版本中是64M,而hadoop2.x之后的版本默认块大小为128M。
HDFS还有一个副本机制,它会默认给存在Datanode当中的每块文件进行备份,默认的副本数量(republication)为3,这样保证了数据的安全性。
大致如图:
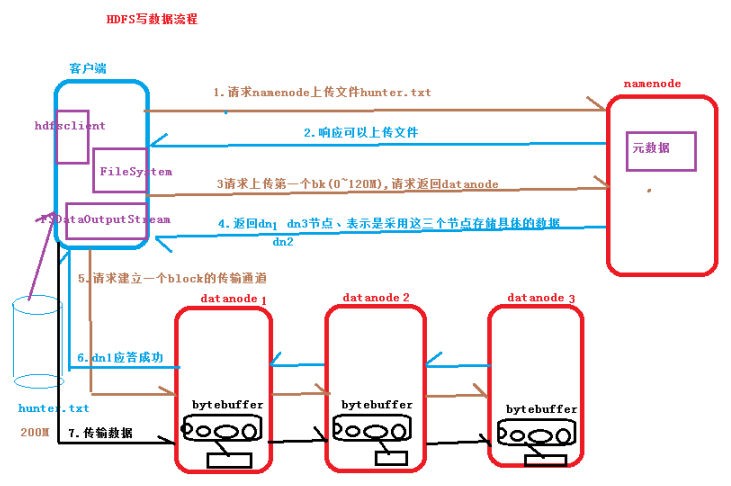
二、HDFS写数据流程
1.客户端向Namenode请求上传文件数据Hunter.txt(大小:200M);
2.Namenode响应可以上传文件;
3.客户端向Namenode请求上传第一个block(0~128M),请求返回Datanode节点;
4.Namenode返回三个Datanode节点(副本数默认为3),采用这三个节点存储数据;
5.客户端向Datanode请求建立一个block的传输通道;
6.Datanode应答通道建立成功;
7.客户端向Datanode传输数据,数据写入到HDFS文件系统当中。
三、hdfs读数据流程
1.客户端向Namenode请求下载文件hunter.txt(200M);
2.Namenode返回目标文件的元数据信息(block所在的datanode);
3.客户端向Datanode请求读取数据文件;
4.Datanode以FSDataInputStream流的形式向客户端传输数据;
5.客户端生成hunter.txt文件。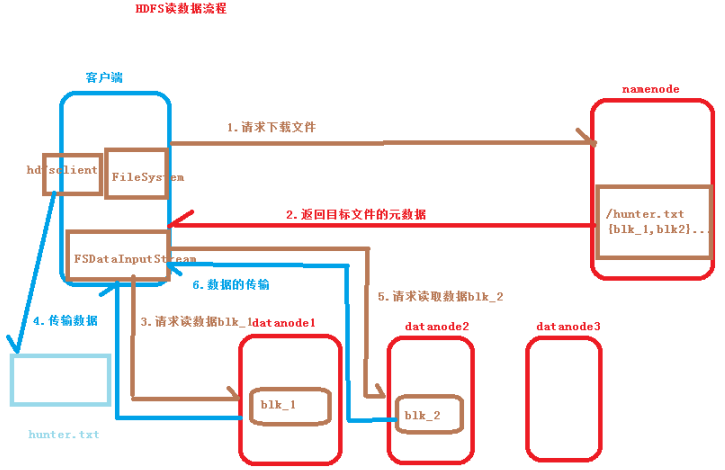
四、Namenode运行机制
首先去到主节点namenode的元数据信息dfs目录中,可以看到很多种文件,如下:
edits:存放HDFS系统所有的更新操作的日志文件
fsimage:HDFS元数据的永久性的检查点,其中包含了hdfs系统所有的目录和文件
seen_txid:最有一个edits文件的数字,即edits文件个数
VERSION:记录了很多的id,如下:
namespaceID:每个节点的id,每个节点都不同
ClusterID:一个集群统一的id,是唯一的,一个集群中所有节点的ClusterID都相同
CTime:Namenode存储系统的使用时间的时间戳
storageType:节点类型
blockpoolID:跨集群的全局唯一
layoutVersion:版本号
Namenode的运行机制:
1.首先启动集群,会启动Namenode和SecondaryNamenode,两个节点的内存会加载日志文件和镜像文件(edits、fsimage文件);
2.当客户端对HDFS集群进行增删改查等操作时,日志文件会更新滚动;
3.当eidts文件数量达到默认阈值,或checkpoint时间到达默认触发时间时;
(dfs.namenode.checkpoint.period :多久checkpoint一次、
dfs.namenode.checkpoint.check.period:多久检查一次操作的次数、
dfs.namenode.checkpoint.txns:多少次操作后chechpoint一次)
4.Namenode将edits文件拷贝到SecondarNamenode;
5.SecondarNamenode的内存会加载拷贝的edits文件并合并;
6.SecondarNamenode会生成新的镜像文件fsimage.checkpoint;
7.SecondarNamenode将新生产的镜像文件拷贝到Namenode;
8.Namenode将收到的镜像文件重命名为fsimage;
9.Namenode将新的fsimage镜像文件发送到SecondarNamenode
这样两个节点的元数据信息就相同了!!!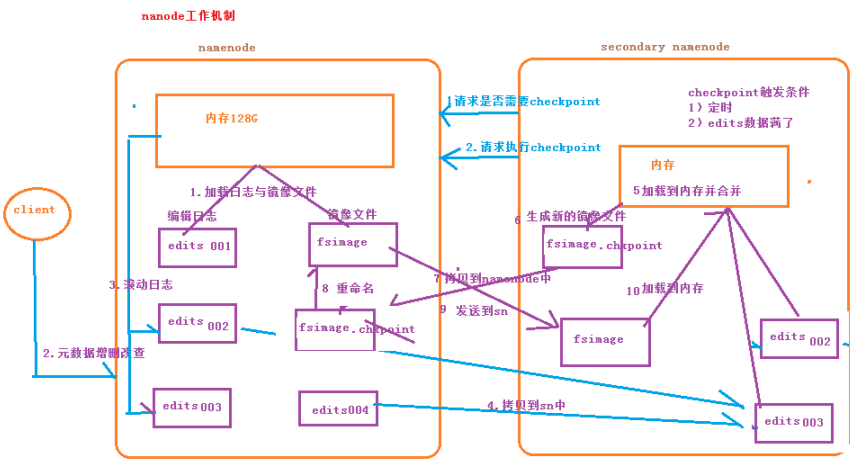
五、Datanode运行机制
1.HDFS集群启动后,Datanode现象Namenode发送注册信息;
2.Namenode返回注册成功;
3.每隔一段时间Datanode会上传所有的块信息到Namenode;
(块信息:数据、数据长度、校验和、时间戳等)
4.默认如果超过10分钟Namenode没有收到Datanode的信息信息,则认为节点不可用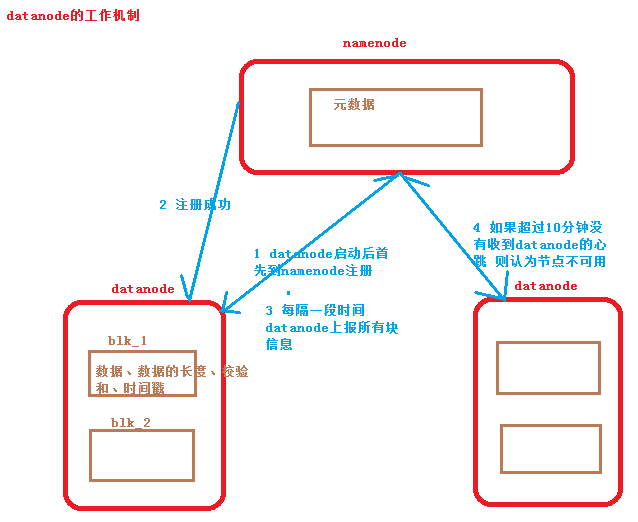
MapReduce:
hadoop序列化概述: https://www.cnblogs.com/comw/p/13381286.html
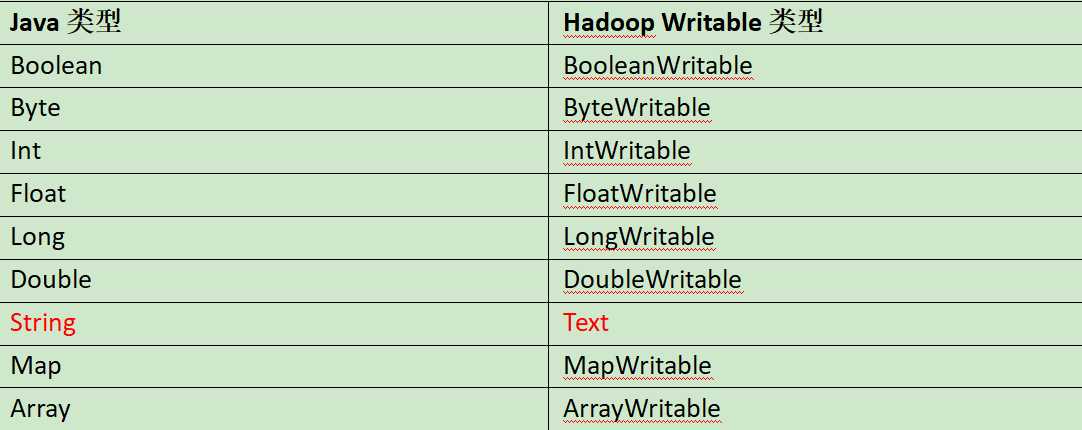
一:hadoop序列化
常用序列化类型:
MapReduce编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver


代码实现:编写MapReduce程序
需求
统计每一个手机号耗费的总上行流量、下行流量、总流量
(1)输入数据

(2)输入数据格式:
| 7 13560436666 120.196.100.99 1116 954 200 id 手机号码 网络ip 上行流量 下行流量 网络状态码 |
(3)期望输出数据格式
| 13560436666 1116 954 2070 手机号码 上行流量 下行流量 总流量 |
(1)编写流量统计的Bean对象
| package com.jh.mapreduce.flowsum; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable;
// 1 实现writable接口 public class FlowBean implements Writable{
private long upFlow; private long downFlow; private long sumFlow;
//2 反序列化时,需要反射调用空参构造函数,所以必须有 public FlowBean() { super(); }
public FlowBean(long upFlow, long downFlow) { super(); this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; }
//3 写序列化方法 @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); }
//4 反序列化方法 //5 反序列化方法读顺序必须和写序列化方法的写顺序必须一致 @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); }
// 6 编写toString方法,方便后续打印到文本 @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; }
public long getUpFlow() { return upFlow; }
public void setUpFlow(long upFlow) { this.upFlow = upFlow; }
public long getDownFlow() { return downFlow; }
public void setDownFlow(long downFlow) { this.downFlow = downFlow; }
public long getSumFlow() { return sumFlow; }
public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } } |
(2)编写Mapper类
| package com.jh.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;
public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
FlowBean v = new FlowBean(); Text k = new Text();
@Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行 String line = value.toString();
// 2 切割字段 String[] fields = line.split("\t");
// 3 封装对象 // 取出手机号码 String phoneNum = fields[1];
// 取出上行流量和下行流量 long upFlow = Long.parseLong(fields[fields.length - 3]); long downFlow = Long.parseLong(fields[fields.length - 2]);
k.set(phoneNum); v.set(downFlow, upFlow);
// 4 写出 context.write(k, v); } } |
(3)编写Reducer类
| package com.jh.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;
public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
@Override protected void reduce(Text key, Iterable<FlowBean> values, Context context)throws IOException, InterruptedException {
long sum_upFlow = 0; long sum_downFlow = 0;
// 1 遍历所用bean,将其中的上行流量,下行流量分别累加 for (FlowBean flowBean : values) { sum_upFlow += flowBean.getUpFlow(); sum_downFlow += flowBean.getDownFlow(); }
// 2 封装对象 FlowBean resultBean = new FlowBean(sum_upFlow, sum_downFlow);
// 3 写出 context.write(key, resultBean); } } |
(4)编写Driver驱动类
| package com.jh.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowsumDriver {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置 args = new String[] { "e:/input/inputflow", "e:/output1" };
// 1 获取配置信息,或者job对象实例 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration);
// 6 指定本程序的jar包所在的本地路径 job.setJarByClass(FlowsumDriver.class);
// 2 指定本业务job要使用的mapper/Reducer业务类 job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class);
// 3 指定mapper输出数据的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class);
// 4 指定最终输出的数据的kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class);
// 5 指定job的输入原始文件所在目录 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } |
MapReduce工作机制:
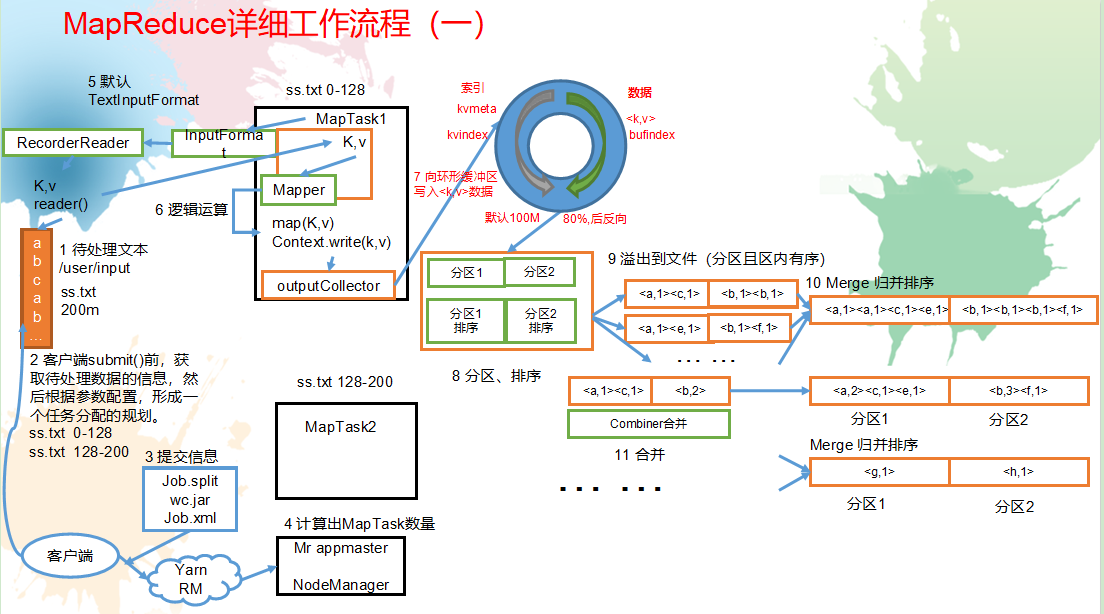
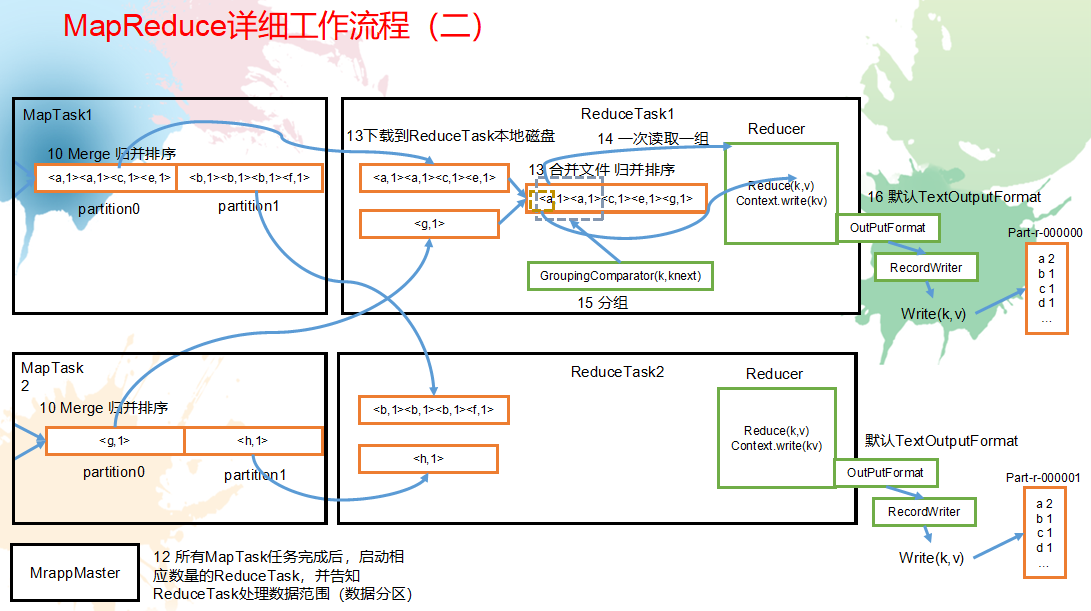
流程详解
上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:
1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中
2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3)多个溢出文件会被合并成大的溢出文件
4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
6)ReduceTask会取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
3.注意
Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
缓冲区的大小可以通过参数调整,参数:io.sort.mb默认100M。
Shuffle机制:
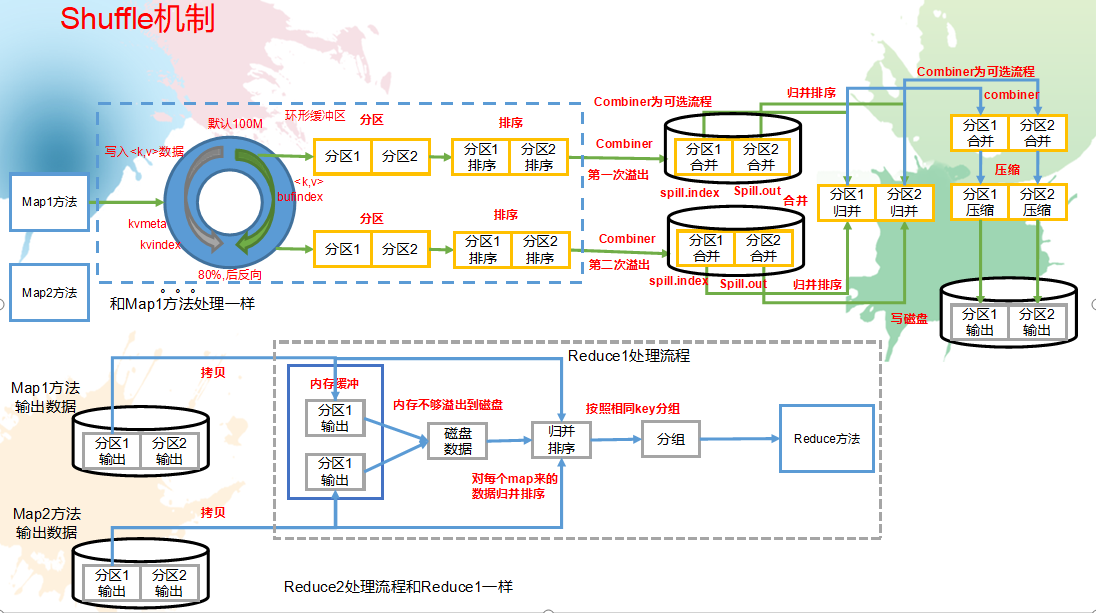
shuffle流程概述
key,value从map()方法输出后,被outputcollector收集通过HashPartitioner类的getpartitioner()方法获取分区号,进入环形缓冲区。默认情况下,环形缓冲区为100MB。
当环形环形缓冲区存储达到80%,开始执行溢写过程,溢写过程中如果有其他数据进入,那么由剩余的20%反向写入。溢写过程会根据key,value
先根据分区进行排序,再根据key值进行排序,后生成一个溢写文件(再对应的分区下根据key值有序),maptask将溢写文件归并排序后落入本地磁盘,reduceTask阶段将多个mapTask下相同分区的数据copy到指定的reduceTask中进行归并排序、分组后一次读取一组数据给reduce()函数
MapTash工作机制:
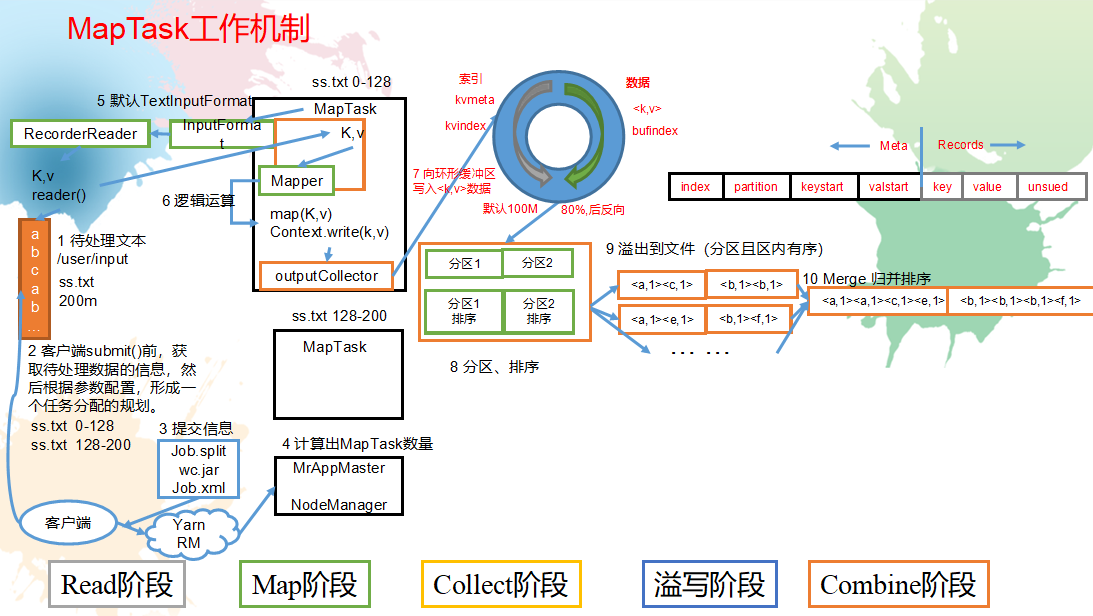
(1)Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
ReduceTask工作机制:
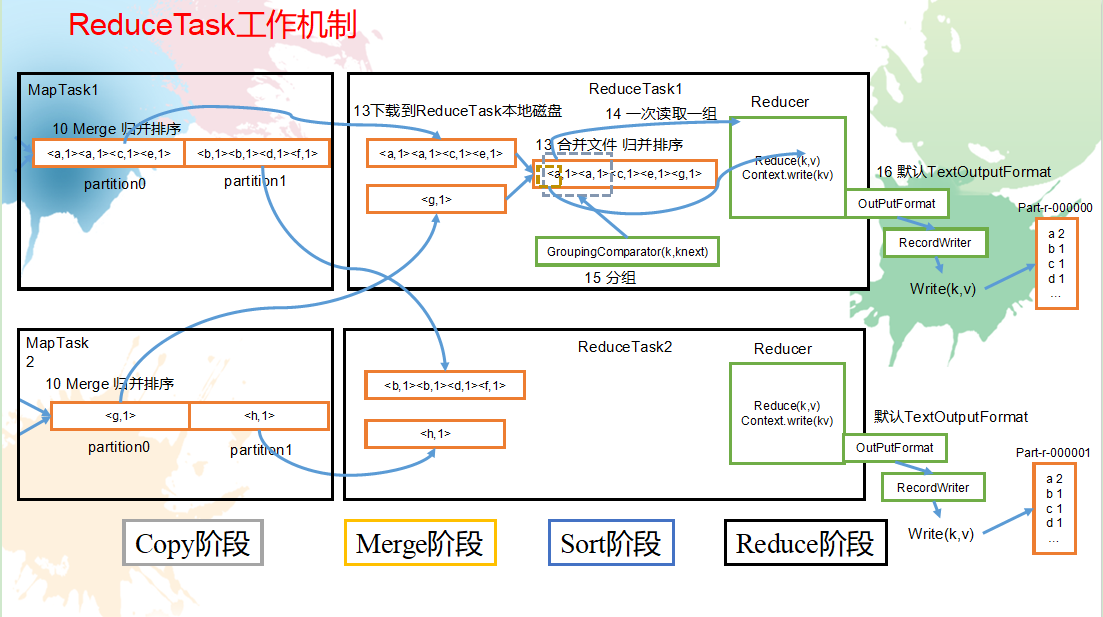
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
Yarn:
yarn基本架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件

YARN工作机制:

工作机制详解
(1)MR程序提交到客户端所在的节点。
(2)YarnRunner向ResourceManager申请一个Application。
(3)RM将该应用程序的资源路径返回给YarnRunner。
(4)该程序将运行所需资源提交到HDFS上。
(5)程序资源提交完毕后,申请运行mrAppMaster。
(6)RM将用户的请求初始化成一个Task。
(7)其中一个NodeManager领取到Task任务。
(8)该NodeManager创建容器Container,并产生MRAppmaster。
(9)Container从HDFS上拷贝资源到本地。
(10)MRAppmaster向RM 申请运行MapTask资源。
(11)RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(12)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(13)MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
(14)ReduceTask向MapTask获取相应分区的数据。
(15)程序运行完毕后,MR会向RM申请注销自己。
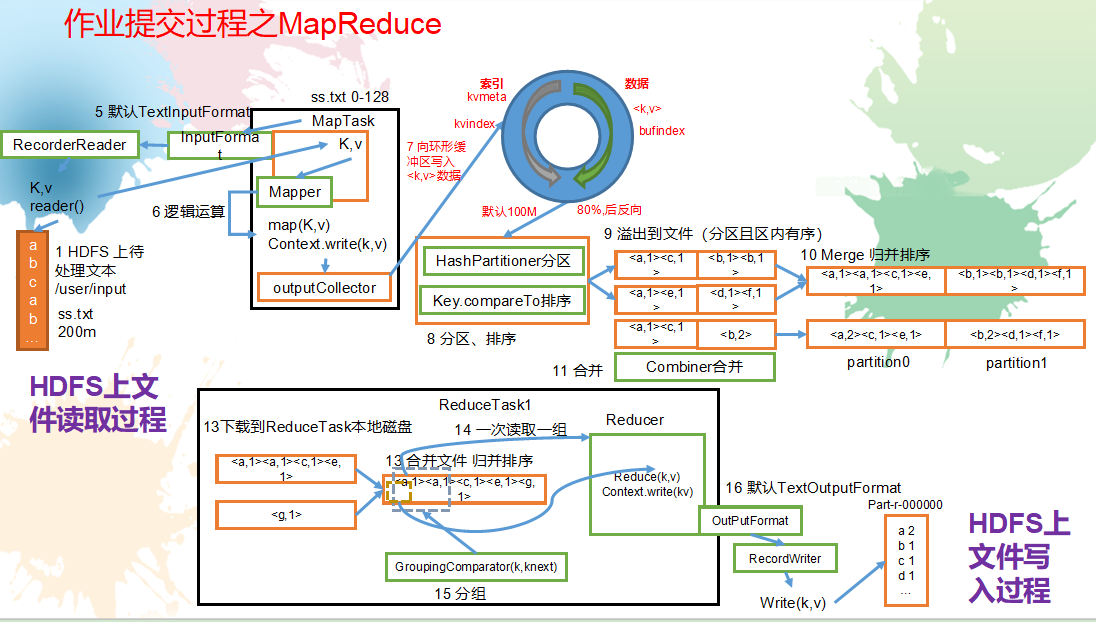
作业提交全过程
1.作业提交过程之YARN

作业提交全过程详解
(1)作业提交
第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
第2步:Client向RM申请一个作业id。
第3步:RM给Client返回该job资源的提交路径和作业id。
第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
第5步:Client提交完资源后,向RM申请运行MrAppMaster。
(2)作业初始化
第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
第7步:某一个空闲的NM领取到该Job。
第8步:该NM创建Container,并产生MRAppmaster。
第9步:下载Client提交的资源到本地。
(3)任务分配
第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(4)任务运行
第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
第14步:ReduceTask向MapTask获取相应分区的数据。
第15步:程序运行完毕后,MR会向RM申请注销自己。
(5)进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
(6)作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
作业提交过程之MapReduce
一、HDFS运行机制
概述:用户的文件会被切块后存储在多台datanode节点中,并且每个文件在整个集群中存放多个副本,副本的数量可以通过修改配置自己设定。
HDFS:Hadoop Distributed file system,分布式文件系统。
HDFS的机制:
HDFS集群中,有两种节点,分别为Namenode,Datanode;
Namenode它的作用时记录元数据信息,记录块信息和对节点进行统一管理。比如用户要存储一个很大的文件,HDFS系统会对这个文件进行切分,然后存储在多台Namenode节点当中,那么每个切的大小,存储的路径信息,文件的副本数等元数据信息会存储在元数据当中,由Namenode进行管理和记录。
Datanode节点的作用是存储数据,Namenode将数据切块后的分配给多个Datanode节点,Datanode对数据块进行存储,Datanode它默认的块大小在hadoop1.x的版本中是64M,而hadoop2.x之后的版本默认块大小为128M。
HDFS还有一个副本机制,它会默认给存在Datanode当中的每块文件进行备份,默认的副本数量(republication)为3,这样保证了数据的安全性。
大致如图:
二、HDFS写数据流程
1.客户端向Namenode请求上传文件数据Hunter.txt(大小:200M);
2.Namenode响应可以上传文件;
3.客户端向Namenode请求上传第一个block(0~128M),请求返回Datanode节点;
4.Namenode返回三个Datanode节点(副本数默认为3),采用这三个节点存储数据;
5.客户端向Datanode请求建立一个block的传输通道;
6.Datanode应答通道建立成功;
7.客户端向Datanode传输数据,数据写入到HDFS文件系统当中。
三、hdfs读数据流程
1.客户端向Namenode请求下载文件hunter.txt(200M);
2.Namenode返回目标文件的元数据信息(block所在的datanode);
3.客户端向Datanode请求读取数据文件;
4.Datanode以FSDataInputStream流的形式向客户端传输数据;
5.客户端生成hunter.txt文件。
四、Namenode运行机制
首先去到主节点namenode的元数据信息dfs目录中,可以看到很多种文件,如下:
edits:存放HDFS系统所有的更新操作的日志文件
fsimage:HDFS元数据的永久性的检查点,其中包含了hdfs系统所有的目录和文件
seen_txid:最有一个edits文件的数字,即edits文件个数
VERSION:记录了很多的id,如下:
namespaceID:每个节点的id,每个节点都不同
ClusterID:一个集群统一的id,是唯一的,一个集群中所有节点的ClusterID都相同
CTime:Namenode存储系统的使用时间的时间戳
storageType:节点类型
blockpoolID:跨集群的全局唯一
layoutVersion:版本号
Namenode的运行机制:
1.首先启动集群,会启动Namenode和SecondaryNamenode,两个节点的内存会加载日志文件和镜像文件(edits、fsimage文件);
2.当客户端对HDFS集群进行增删改查等操作时,日志文件会更新滚动;
3.当eidts文件数量达到默认阈值,或checkpoint时间到达默认触发时间时;
(dfs.namenode.checkpoint.period :多久checkpoint一次、
dfs.namenode.checkpoint.check.period:多久检查一次操作的次数、
dfs.namenode.checkpoint.txns:多少次操作后chechpoint一次)
4.Namenode将edits文件拷贝到SecondarNamenode;
5.SecondarNamenode的内存会加载拷贝的edits文件并合并;
6.SecondarNamenode会生成新的镜像文件fsimage.checkpoint;
7.SecondarNamenode将新生产的镜像文件拷贝到Namenode;
8.Namenode将收到的镜像文件重命名为fsimage;
9.Namenode将新的fsimage镜像文件发送到SecondarNamenode
这样两个节点的元数据信息就相同了!!!
五、Datanode运行机制
1.HDFS集群启动后,Datanode现象Namenode发送注册信息;
2.Namenode返回注册成功;
3.每隔一段时间Datanode会上传所有的块信息到Namenode;
(块信息:数据、数据长度、校验和、时间戳等)
4.默认如果超过10分钟Namenode没有收到Datanode的信息信息,则认为节点不可用
MapReduce:
hadoop序列化概述: https://www.cnblogs.com/comw/p/13381286.html
一:hadoop序列化
常用序列化类型:
MapReduce编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver
代码实现:编写MapReduce程序
需求
统计每一个手机号耗费的总上行流量、下行流量、总流量
(1)输入数据
(2)输入数据格式:
| 7 13560436666 120.196.100.99 1116 954 200 id 手机号码 网络ip 上行流量 下行流量 网络状态码 |
(3)期望输出数据格式
| 13560436666 1116 954 2070 手机号码 上行流量 下行流量 总流量 |
(1)编写流量统计的Bean对象
| package com.jh.mapreduce.flowsum; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable;
// 1 实现writable接口 public class FlowBean implements Writable{
private long upFlow; private long downFlow; private long sumFlow;
//2 反序列化时,需要反射调用空参构造函数,所以必须有 public FlowBean() { super(); }
public FlowBean(long upFlow, long downFlow) { super(); this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; }
//3 写序列化方法 @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); }
//4 反序列化方法 //5 反序列化方法读顺序必须和写序列化方法的写顺序必须一致 @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); }
// 6 编写toString方法,方便后续打印到文本 @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; }
public long getUpFlow() { return upFlow; }
public void setUpFlow(long upFlow) { this.upFlow = upFlow; }
public long getDownFlow() { return downFlow; }
public void setDownFlow(long downFlow) { this.downFlow = downFlow; }
public long getSumFlow() { return sumFlow; }
public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } } |
(2)编写Mapper类
| package com.jh.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;
public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
FlowBean v = new FlowBean(); Text k = new Text();
@Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行 String line = value.toString();
// 2 切割字段 String[] fields = line.split("\t");
// 3 封装对象 // 取出手机号码 String phoneNum = fields[1];
// 取出上行流量和下行流量 long upFlow = Long.parseLong(fields[fields.length - 3]); long downFlow = Long.parseLong(fields[fields.length - 2]);
k.set(phoneNum); v.set(downFlow, upFlow);
// 4 写出 context.write(k, v); } } |
(3)编写Reducer类
| package com.jh.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;
public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
@Override protected void reduce(Text key, Iterable<FlowBean> values, Context context)throws IOException, InterruptedException {
long sum_upFlow = 0; long sum_downFlow = 0;
// 1 遍历所用bean,将其中的上行流量,下行流量分别累加 for (FlowBean flowBean : values) { sum_upFlow += flowBean.getUpFlow(); sum_downFlow += flowBean.getDownFlow(); }
// 2 封装对象 FlowBean resultBean = new FlowBean(sum_upFlow, sum_downFlow);
// 3 写出 context.write(key, resultBean); } } |
(4)编写Driver驱动类
| package com.jh.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowsumDriver {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置 args = new String[] { "e:/input/inputflow", "e:/output1" };
// 1 获取配置信息,或者job对象实例 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration);
// 6 指定本程序的jar包所在的本地路径 job.setJarByClass(FlowsumDriver.class);
// 2 指定本业务job要使用的mapper/Reducer业务类 job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class);
// 3 指定mapper输出数据的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class);
// 4 指定最终输出的数据的kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class);
// 5 指定job的输入原始文件所在目录 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } |
MapReduce工作机制:
流程详解
上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:
1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中
2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3)多个溢出文件会被合并成大的溢出文件
4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
6)ReduceTask会取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
3.注意
Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
缓冲区的大小可以通过参数调整,参数:io.sort.mb默认100M。
Shuffle机制:
shuffle流程概述
key,value从map()方法输出后,被outputcollector收集通过HashPartitioner类的getpartitioner()方法获取分区号,进入环形缓冲区。默认情况下,环形缓冲区为100MB。
当环形环形缓冲区存储达到80%,开始执行溢写过程,溢写过程中如果有其他数据进入,那么由剩余的20%反向写入。溢写过程会根据key,value
先根据分区进行排序,再根据key值进行排序,后生成一个溢写文件(再对应的分区下根据key值有序),maptask将溢写文件归并排序后落入本地磁盘,reduceTask阶段将多个mapTask下相同分区的数据copy到指定的reduceTask中进行归并排序、分组后一次读取一组数据给reduce()函数
MapTash工作机制:
(1)Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
ReduceTask工作机制:
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
Yarn:
yarn基本架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件
YARN工作机制:
工作机制详解
(1)MR程序提交到客户端所在的节点。
(2)YarnRunner向ResourceManager申请一个Application。
(3)RM将该应用程序的资源路径返回给YarnRunner。
(4)该程序将运行所需资源提交到HDFS上。
(5)程序资源提交完毕后,申请运行mrAppMaster。
(6)RM将用户的请求初始化成一个Task。
(7)其中一个NodeManager领取到Task任务。
(8)该NodeManager创建容器Container,并产生MRAppmaster。
(9)Container从HDFS上拷贝资源到本地。
(10)MRAppmaster向RM 申请运行MapTask资源。
(11)RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(12)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(13)MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
(14)ReduceTask向MapTask获取相应分区的数据。
(15)程序运行完毕后,MR会向RM申请注销自己。
作业提交全过程
1.作业提交过程之YARN
作业提交全过程详解
(1)作业提交
第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
第2步:Client向RM申请一个作业id。
第3步:RM给Client返回该job资源的提交路径和作业id。
第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
第5步:Client提交完资源后,向RM申请运行MrAppMaster。
(2)作业初始化
第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
第7步:某一个空闲的NM领取到该Job。
第8步:该NM创建Container,并产生MRAppmaster。
第9步:下载Client提交的资源到本地。
(3)任务分配
第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(4)任务运行
第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
第14步:ReduceTask向MapTask获取相应分区的数据。
第15步:程序运行完毕后,MR会向RM申请注销自己。
(5)进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
(6)作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
作业提交过程之MapReduce