极度随机树ExtraTreesClassifier
1 声明
本文的数据来自网络,部分代码也有所参照,这里做了注释和延伸,旨在技术交流,如有冒犯之处请联系博主及时处理。
2 极度随机树ExtraTreesClassifier简介
Extremely Randomized Trees Classifier(极度随机树) 是一种集成学习技术,它将森林中收集的多个去相关决策树的结果聚集起来输出分类结果。极度随机树的每棵决策树都是由原始训练样本构建的。在每个测试节点上,每棵树都有一个随机样本,样本中有k个特征,每个决策树都必须从这些特征集中选择最佳特征,然后根据一些数学指标(一般是基尼指数)来拆分数据。这种随机的特征样本导致多个不相关的决策树的产生。
在构建森林的过程中,对于每个特征,计算用于分割特征决策的数学指标(如使用基尼指数)的归一化总缩减量,这个值称为基尼要素的重要性。基尼重要性按降序排列后,可根据需要选择前k个特征。
3 极度随机树ExtraTreesClassifier代码示例
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import ExtraTreesClassifier
import matplotlib
# 自定义字体,以兼容中文显示
myfont = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\STKAITI.TTF')
df_pre = pd.read_csv('../input/PlayTennis.txt',sep="\t")
# 拆分X(自变量)和y(因变量)
#X = df.drop('Play Tennis', axis=1)
df=df_pre.drop('Day', axis = 1)
#分类类型转数值型,通过字典映射转换
weather_mapper = {'Sunny': 1, 'Overcast': 2,'Rain':3}
df['Outlook'].replace(weather_mapper, inplace=True)
temperature_mapper = {'Hot': 1, 'Mild': 2,'Cool':3}
df['Temperature'].replace(temperature_mapper, inplace=True)
humidity_mapper = {'High': 1, 'Normal': 2}
df['Humidity'].replace(humidity_mapper, inplace=True)
wind_mapper = {'Weak': 1, 'Strong': 0}
df['Wind'].replace(wind_mapper, inplace=True)
playTennis_mapper={"Yes":1,"No":0}
df['PlayTennis'].replace(playTennis_mapper, inplace=True)
print(df.head())
y = df['PlayTennis']
X = df.loc[ :,'Outlook':'Wind']
#X = df.drop('PlayTennis', axis = 1)
#print(X.head())
# 5棵树、2个特征、评判指标是熵
extra_tree_forest = ExtraTreesClassifier(n_estimators=5,
criterion='entropy', max_features=2)
extra_tree_forest.fit(X, y)
# 计算每个特征的重要性水平
feature_importance = extra_tree_forest.feature_importances_
# 标准化特征的重要性水平
feature_importance_normalized = np.std([tree.feature_importances_ for tree in
extra_tree_forest.estimators_],
axis=0)
#画图
# Plotting a Bar Graph to compare the models
plt.bar(X.columns, feature_importance_normalized)
plt.xlabel('特征',fontproperties = myfont)
plt.ylabel('特征重要性',fontproperties = myfont)
plt.title('特征重要性比较',fontproperties = myfont)
plt.show()

4 计算示意:
熵公示:
其中c为唯一类标签的个数,p i为所属分类的行占比。
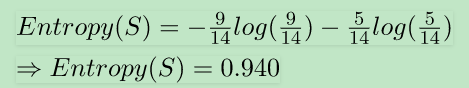

-- 构造数据
CREATE TABLE PlayTennis(
DayNo varchar(10),
Outlook varchar(10),
Temperature varchar(10),
Humidity varchar(10),
Wind varchar(10),
PlayTennis varchar(10)
);
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D1','Sunny','Hot','High','Weak','No');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D2','Sunny','Hot','High','Strong','No');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D3','Overcast','Hot','High','Weak','Yes');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D4','Rain','Mild','High','Weak','Yes');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D5','Rain','Cool','Normal','Weak','Yes');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D6','Rain','Cool','Normal','Strong','No');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D7','Overcast','Cool','Normal','Strong','Yes');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D8','Sunny','Mild','High','Weak','No');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D9','Sunny','Cool','Normal','Weak','Yes');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D10','Rain','Mild','Normal','Weak','Yes');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D1','Sunny','Mild','Normal','Strong','Yes');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D12','Overcast','Mild','High','Strong','Yes');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D13','Overcast','Hot','Normal','Weak','Yes');
insert into `PlayTennis`(`DayNo`,`Outlook`,`Temperature`,`Humidity`,`Wind`,`PlayTennis`) values ('D14','Rain','Mild','High','Strong','No');
-- 计算熵
WITH CTE1 AS
(
SELECT DISTINCT COUNT(PlayTennis)OVER(PARTITION BY PlayTennis) gp,tatal
FROM PlayTennis,(SELECT COUNT(*) tatal FROM PlayTennis) A
)
SELECT SUM(-(gp/tatal)*LOG(2,gp/tatal)) entropy_s FROM
(
SELECT gp,tatal
FROM CTE1
)A
-- 0.940285959354754
假设第一棵决策树选择了特征Outlook 和Temperature,则
![]()
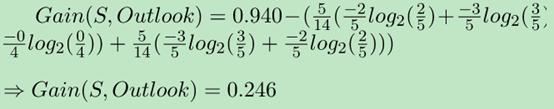
-- 计算OutLook特征的信息增益
WITH CTE2 AS
(
SELECT DISTINCT COUNT(PlayTennis)OVER(PARTITION BY Outlook,PlayTennis
ORDER BY PlayTennis) gp,
COUNT(1)OVER(PARTITION BY Outlook ) num,
Outlook,PlayTennis,
(SELECT COUNT(*) tatal FROM PlayTennis) tatal
FROM PlayTennis
)
SELECT 0.940285959354754-SUM(-(num/tatal)*(gp/num)*LOG(2,gp/num)) Gain_S_OutLook
FROM CTE2
-- 0.246749820735977同理
![]()
第二棵决策树选择了特征Temperature 和Wind,则Gain计算如下:

第三棵决策树选择了特征Outlook和Humidity,则Gain计算如下:

第四棵决策树选择了特征Temperature和Humidity,则Gain计算如下:
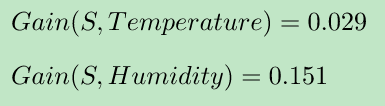
第五棵决策树选择了特征Wind 和 Humidity,则Gain计算如下:
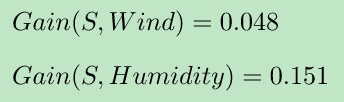
则各个特征的gain(信息增益)汇总如下:
Outlook:0.246+0.246= 0.492
Temperature:0.029+0.029+0.029 = 0.087
Humidity:=0.151+0.151+0.151 = 0.453
Wind:0.048+0.048 = 0.096
所以极度随机树来确定的最重要变量是特征 Outlook。
注:因特征选择的随机性,这里计算的特征重要水平可能有差异。
5 总结
Refer :
https://www.geeksforgeeks.org/ml-extra-tree-classifier-for-feature-selection/
https://machinelearningmastery.com/extra-trees-ensemble-with-python/