原文
一:概念
决策树是一种非线性有监督分类模型,随机森林是一种非线性有监督分类模型。线性分类模型比如说逻辑回归,可能会存在不可分问题,但是非线性分类就不存在。决策树是机器学习中最接近人类思考问题的过程的一种算法,通过若干个节点,对特征进行提问并分类(可以是二分类也可以使多分类),直至最后生成叶节点(也就是只剩下一种属性)。
决策树是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
信息熵:熵代表信息的不确定性,信息的不确定性越大,熵越大;比如“明天太阳从东方升起”这一句话代表的信息我们可以认为为0;因为太阳从东方升起是个特定的规律,我们可以把这个事件的信息熵约等于0;说白了,信息熵和事件发生的概率成反比:数学上把信息熵定义如下:H(X)=H(P1,P2,…,Pn)=-∑P(xi)logP(xi)
互信息:指的是两个随机变量之间的关联程度,即给定一个随机变量后,另一个随机变量不确定性的削弱程度,因而互信息取值最小为0,意味着给定一个随机变量对确定一另一个随机变量没有关系,最大取值为随机变量的熵,意味着给定一个随机变量,能完全消除另一个随机变量的不确定性。
I(X,Y)=H(Y)−H(Y|X)I(X,Y)=H(Y)−H(Y|X)
决策树中常用的评价指标:
信息增益(Information Gain):表示得知特征A的信息而使得类X的信息的不确定性减少的程度。定义:特征A对训练数据集D的信息增益g(D, A),定义为集合D的经验熵H(D)与经验条件熵H(D|A)的差值。
g(D,A)=H(D)-H(D|A)
而这又是互信息的定义。所以决策树中的信息增益等价于训练集中类与特征的互信息。
信息率(Information Gain Ratio):
用信息增益作为划分特征的依据时,会存在一些问题。例如,如果使用数据的ID作为特征,这样,每个数据点相当于均匀分布,所以得到的信息增益一定是最大的,但是我们都知道ID是不能作为特征的。这样如果单纯的使用信息增益作为划分特征的依据的话,会导致我们生成的树比较矮胖,容易过拟合。定义:特征A对训练数据集D的信息增益率gR(D,A)gR(D,A)定义为其信息增益g(D,A)g(D,A)与训练数据集D关于特征A的值得信息熵HA(D)HA(D)之比:
Gini系数:
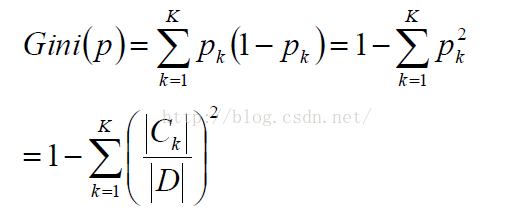
决策树的评价 —— loss function:
假定样本的总类别数为K个;树T的叶节点个数为|T|,t是树T的叶节点,叶节点有NtNt个样本点,其中k类的样本点有NikNik个,Ht(T)
Ht(T)为叶节点t上的经验熵,则决策树的loss function可以定义为:
二、决策树3种算法
1.信息增益:ID3
定义为:对于特征A的信息增益为:g(D,A)=H(D)-H(D|A),信息增益就是给定训练集D时,特征A和训练集D的互信息I(D,A).选取信息增益最大的特征作为分支的节点.(后面有举例)
其中,条件熵H(D|A)的计算公式如下:
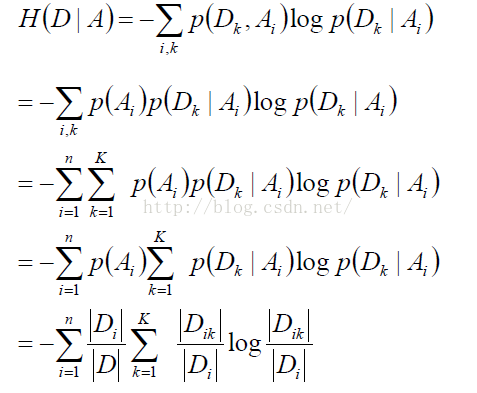
信息增益的缺点:对数目较多的属性有偏好,且生成额决策树层次多,深度浅,为改善这些问题,提出方法二.
2.信息增益率:C4.5
其等于信息增益/属性A的熵
信息增益率的缺点:对数目较少的属性有偏好,后又有方法三.
3.CART基尼指数:
其计算公式如下:
Gini系数可以理解为y=-lnx在x=1处的一阶展开.
总结之,一个属性的信息增益(率)/gini指数越大,表明属性对样本的熵较少的程度越大,那么这个属性使得样本从不确定性变为确定性的能力越强,分支时选择该属性作为判断模块使得决策树生成的越快.
三、举例
看了一遍概念后,我们先从一个简单的案例开始,如下图我们样本:
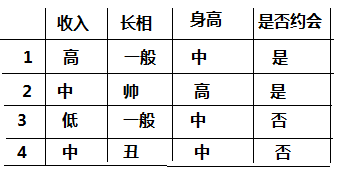
对于上面的样本数据,根据不同特征值我们最后是选择是否约会,我们先自定义的一个决策树,决策树如下图所示:
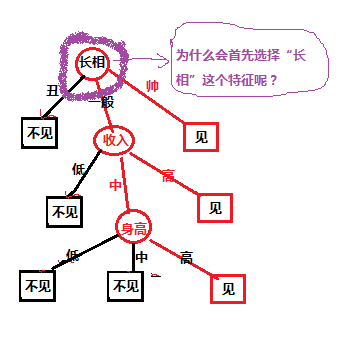
对于上图中的决策树,有个疑问,就是为什么第一个选择是“长相”这个特征,我选择“收入”特征作为第一分类的标准可以嘛?
现在我们就把信息熵运用到决策树特征选择上,对于选择哪个特征我们按照这个规则进行“哪个特征能使信息的确定性最大我们就选择哪个特征”;比如上图的案例中;
第一步:假设约会去或不去的的事件为Y,其信息熵为H(Y);
第二步:假设给定特征的条件下,其条件信息熵分别为H(Y|长相),H(Y|收入),H(Y|身高)
第三步:分别计算信息增益(互信息):G(Y,长相) = I(Y,长相) = H(Y)-H(Y|长相) 、G(Y,) = I(Y,长相) = H(Y)-H(Y|长相)等
第四部:选择信息增益最大的特征作为分类特征;因为增益信息大的特征意味着给定这个特征,能很大的消除去约会还是不约会的不确定性;
第五步:迭代选择特征即可;
按以上就解决了决策树的分类特征选择问题,上面的这种方法就是ID3方法,当然还是别的方法如 C4.5;等;
四、决策树剪枝
1. 完整树的问题
决策树对训练样本具有很好的分类能力。而一棵对样本完全分类的决策树(完整树),对未知的测试数据未必有很好的预测能力,泛化能力较差,容易出现过拟合现象。
完整树:决策树T的每个叶子节点的样本集合中的样本都为同一类型。
过拟合会导致构建出过于复杂的决策树,为解决这个问题,可以通过剪枝的方法来简化已生成的决策树,即将某个划分属性的节点的分支减掉,并将该节点作为一个某个决策结果的叶子节点(对应的决策结果可采用占多数的样本标记)。那怎么判断某个划分属性的节点是否需要剪枝呢?(剪枝在于减少叶子节点的数量)
2. 剪枝的算法
因而,我们需要设计一个分类误差评估函数,然后通过极小化决策树整体的损失函数实现剪枝。
设决策树 T 有 n 个叶子节点,设第t个叶子节点的样本集合Dt有Nt个样本,这些样本的标记类别不一定相同,假设样本集合Dt中的样本有k种标记类别,第i种类别的样本有Nti个。
那么,第t个叶子节点的样本集合的经验熵 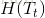
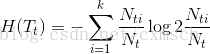
可以看出,当第t个叶子节点的样本集合只有一种标记类型时,经验熵为0。
下面给出我们的决策树 T 的损失函数的定义: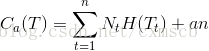
C(T)表示决策树对训练数据的预测误差,参数α控制两者之间的影响,α越大,要求模型越简单,α=0表示不考虑模型的复杂度(即可以产生较多的叶子节点)。
剪枝的过程,就是当α确定时,选择损失函数最小的模型。分类越细,叶子节点的经验熵就越小,C(T)越小,但是由于分类越细会导致叶子节点的数目会很多,α|T|(或αn)越大。损失函数反映的是两者的平衡。
决策树的生成过程只考虑了样本集合分类的纯度,只考虑更好地拟合训练数据,而剪枝过程在于减小整体的复杂度。
决策树的剪枝算法:固定某个经验值α,对划分属性的结点进行剪枝预估,若剪枝后,决策树损失函数减小了,则减掉该结点的叶节点,将该结点作为新的叶节点,该结点对应的决策结果可以为其样本集合中占多数的样本标记。(或构造不同的α值得到一些备选树,通过交叉验证的方法得到最优树)
五、决策树的过拟合解决办法
若决策树的度过深的话会出现过拟合现象,对于决策树的过拟合有二个方案:
1:剪枝
先剪枝和后剪纸(可以在构建决策树的时候通过指定深度,每个叶子的样本数来达到剪枝的作用)
引入评价函数(损失函数):所有叶节点的加权求熵,其值越小表明分类越精准,那么该决策树分类觉越好.Nt是叶节点中样本的个数.
剪枝方法之预剪枝:
从前往后生成树的过程中,从树根开始,逐一生成节点,比较其生成与不生成的C(T),在验证集上选择C(T)小的作为最终的数.
剪枝方法之后剪枝:
剪枝系数:
决策树生成后,查找剪枝系数最小的节点,视为一颗决策树,重复以上,知道只剩下一个节点,这样得到多颗决策树,在验证集上计算损失函数最小的那棵树作为最终的决策树.
2:随机森林
随机森林,指的是利用多棵树对样本进行训练并预测的一种分类器。随机森林就是由多棵CART树构成的。随机森林具有两个随机性:
①样本随机性:对于每棵树,它们使用的训练集是从总的训练集中有放回采样出来的。这意味着,总的训练集中的有些样本可能多次出现在一棵树的训练集中,也可能从未出现在一棵树的训练集中。
②特征随机性:在训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机地无放回抽取的,根据Leo Breiman的建议,假设总的特征数量为M,这个比例可以是sqrt(M),1/2sqrt(M), 2sqrt(M)。
随机森林与使用决策树作为基本分类器的bagging有些类似,它们都具有①,但是使用决策树做为基分类器的bagging不具有②。
2.1 随机森林的训练过程
(1)给定训练集S,测试集T,特征维数F。确定参数:使用到的CART的数量为t ,每棵树的深度d,每个节点使用到的特征数量f, 终止条件:节点上最少样本数s,节点上最少的信息增益m
对于第t-1棵树,i=t-1:
(2)从S中有放回的抽取大小和S一样的训练集S(i),作为根节点的样本,从根节点开始训练
(3)如果当前节点上达到终止条件,则设置当前节点为叶子节点,如果是分类问题,该叶子节点的预测输出为当前节点样本集合中数量最多的哪一类c(j),概率p为c(j)占当前样本集的比例;如果是回归问题,预测输出为当前节点样本集各个样本值的平均值。然后继续训练其他节点。如果当前节点没有达到终止条件,则从F维特征中无放回的随机选取f维度特征。利用这f维特征,寻找分类效果最好的一维特征k及其阈值th,当前节点上样本第k维特征小于th的样本被划分到左节点,其余的被划分到右节点。继续训练其他节点。
(4)重复(2)(3)直到所有节点都训练过了或者被标记为叶子节点。
(5)重复(2)(3)(4)直到所有CART都被训练过。
2.2 利用随机森林的预测过程
对于第t-1棵树,i=t-1;
(1)从当前树的根节点开始,根据当前节点的阈值th,判断是进入左节点(<th)还是进入右节点(>=th),直到到达某个叶子节点,并输出预测值。
(2)重复执行(1)直到所有t棵树都输出了预测值。如果是分类问题,则输出为所有树种预测概率总和最大的那一个类,即对每个c(j)的p进行累计;如果是回归问题,则输出为所有树的输出的平均值。
3.随机森林的特点
影响分类性能的主要因素:①森林中单棵树的分类强度:每棵树的分类强度越大,则随机森林的分类性能越好。②森林中树之间的相关度:树之间的相关度越大,则随机森林的分类性能越差。
两个随机性的引入,使得随机森林不容易陷入过拟合
两个随机性的引入,使得随机森林具有很好的抗噪声能力
对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化。
可生成一个Proximities=(pij)矩阵,用于度量样本之间的相似性:pij=aij/N,aji表示样本i和j出现在随机森林中同一个叶子结点的次数,N表示随机森林中树的棵树。
可以得出变量重要性排序(两种:基于OOB误分率的增加量和基于分裂时的GINI下降量)
bootstrapping中没有被选择的数据称为out of bag(OOB) examples, 这些数据由于没有用来训练模型,故可以用于模型的验证。
4.简述RF、GBDT、xgboost区别
随机森林Random Forest是一个包含多个决策树(CART)的分类器。GBDT(Gradient Boosting Decision Tree)即梯度上升决策树算法,相当于融合决策树和梯度上升boosting算法。xgboost类似于gbdt的优化版,不论是精度还是效率上都有了提升。与gbdt相比,具体的优点有:①损失函数是用泰勒展式二项逼近,而不像gbdt里的就是一阶导数。②对树的结构进行了正则化约束,防止模型过度复杂,降低了过拟合的可能性。③节点分裂的方式不同,gbdt是用的gini系数,xgboost是经过优化推导后的。
六、决策树优缺点
优点:
->计算简单,易理解,可解释性强
->适合处理确实属性的样本,对样本的类别要求不高(可以是数值,布尔,文本等混合样本)
->能处理不相干特征
缺点:
->容易过拟合
->忽略了数据之间的相关性
->不支持在线学习,对新样本,决策树需要全部重建